자연어 처리
- 언어: 인코딩되어서 하고 싶은 말을 전달해 주는 매개체
- 소통 과정: 전달자는 전달하고자 하는 메시지를 머릿속으로 생각하고 언어로 인코딩해서 전달, 수신자는 수신된 언어를 디코딩하여 이해
자연어란
- 자연언어: 일반 사회에서 자연히 발생해 쓰이는 언어
- 인공언어: 프로그래밍 언어처럼 인위적으로 만들어진 언어
자연어처리
- 컴퓨터를 이용해 인간의 언어를 이해, 생성, 분석하는 기술 (이해하도록 대체)
- 수신자가 컴퓨터가 되고, 컴퓨터가 인코딩된 언어를 해독하는 과정
-> 컴퓨터가 자연어를 해독하고, 그 의미를 이해하는 기술
자연어처리 방법
1) Symbolic approach
- 규칙/지식 기반 접근법
- 발화 상황을 다 매핑하여 정리

- 발화 상황을 다 매핑하여 정리
2) Statistical approach
- 확률/통계 기반 접근법
- TF-IDF 이용해 키워드 추출
- TF(Term frequency): 단어가 문서에 등장한 개수
→ TF가 높을수록 중요한 단어! - DF (Document frequency): 해당 단어가 등장한 문서의 개수
→ DF가 높을수록 중요하지 않은 단어, 그래서 역수를 취한 IDF 사용
- TF(Term frequency): 단어가 문서에 등장한 개수
자연어 처리의 단계
- 전처리
어떤 데이터를 이용해서 학습하려고 하는데 내가 원하는 예쁜 형태가 아닐 수 있다 -> 입맛에 맞게 바꾸자- 개행문자, 특수문자, 공백, 중복 표현(ㅋㅋㅋ, ㅠㅠㅠ 등) 제거
- 이메일, 링크, 제목 제거
- 불용어(무의미한 용어), 조사 제거
- 띄어쓰기, 문장분리 보정
- 사전 구축
- Tokenizing
자연어는 문장으로 이루어져 있다, 통째로는 못 봐 -> 어떻게 쪼개서 볼래?- 어절: 한국어는 어절 단위로 잘랐을 때 그게 의미를 가지는 최소 단위가 아니다
- 형태소: 대표적인 방법! 형태소는 의미를 가지는 최소 단위
아예 오렌지 -> 오 / 렌 / 지 -> ㅇ / ㅗ 이런 식으로 분리하는 연구도 진행 중... (2019년 기준이라 성과 냈을지도?!) - n-gram
- WordPiece: BERT에 적용된 토크나이징 기법
- Lexical analysis
- 어휘 분석, 형태소 분석, 개체명 인식, 상호 참조
- Syntactic analysis
- 구문 분석
- Semantic analysis
- 의미 분석
자연어 처리를 활용한 예시
- 문서 분류, 문법이나 오타 교정
- 정보 추출, 정보 검색
- 음성 인식 결과 보정, 음성 합성 텍스트 보정 -> 우리가 해야 할 일,,,
- 요약문 생성, 질의 응답
- 기계 번역, 기계 독해
- 챗봇 (핑퐁으로 대화 이어지게)
자연어 처리 -> '분류' 문제
- 형태소 분석, 문서 분류, 개체명 인식 등 대부분의 자연어 처리 문제는 분류 문제에 속한다

특징 추출과 분류
-
분류를 위해서는 데이터를 수학적으로 표현해야 함
-
분류 대상의 특징!을 먼저 파악해야 함 (Feature extraction)
-
특징을 기준으로 분류 대상을 그래프 위에 표현할 수 있다
-
분류 대상의 경계를 수학적으로 나눌 수 있음 (Classification)
-> 새로운 데이터가 들어왔을 때 어느 쪽과 가까운지 판별 가능
자연어에서 특징 추출과 분류
- 과거에는 사람이 직접 특징 파악 후 분류했음, 하지만 복잡한 문제는 사람이 파악하기에 어려울 수 있음
- 특징을 컴퓨터가 스스로 찾고, 스스로 분류까지 하는 게 기계학습의 핵심기술
Word Embedding - Word2Vec
(이전)
- 자연어를 좌표평면 위에 표현해 보자
- 가장 단순한 표현법은 one-hot encoding!
단어를 쪼개서 일치하면 1, 아니면 0을 주는데 이 경우에 문장이 길어지고, 단어가 많아지면 대부분의 값에 0이 들어가게 됨
-> Sparse representation - 즉, 단어가 가지는 '의미'를 벡터 공간에 표현할 수 없다
Word2Vec
- 자연어(특히 단어)의 의미를 벡터 공간에 임베딩한다!
- 한 단어의 주변 단어를 통해 의미를 파악함
ex)
**가 멍멍 짖었다
$$가 멍멍 짖었다
--> **와 $$가 뭔지는 몰라, 근데 주변 단어가 비슷하네? 그럼 의미도 비슷하지 않을까?-
Word2vec 알고리즘은 주변부의 단어를 예측하는 방식으로 학습됨 (Skip-gram)
-
간단한 신경망 구조로 이루어져 있음 (input, hidden layer, output)
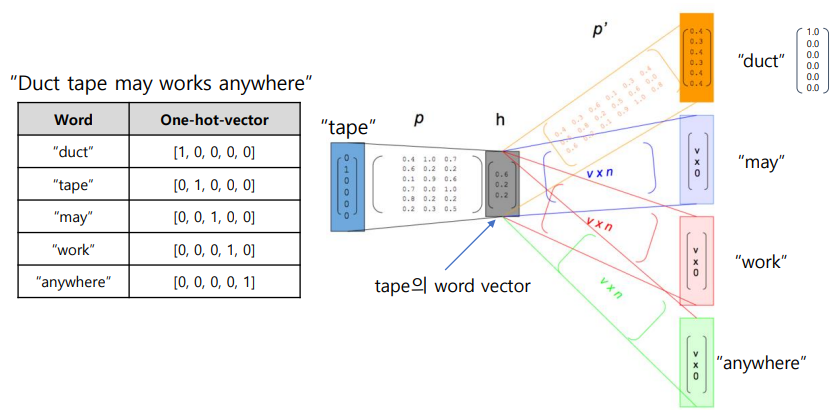
-
input은 (문장을 원핫 벡터로 치환해서) 원핫 벡터가 들어감, 맞히고 싶은 건 주변 단어의 원핫 벡터
-
ex) "tape"의 원핫 벡터인 (0,1,0,0,0)이 들어가면 "duck"의 원핫 벡터인 (1,0,0,0,0)이 나왔으면 좋겠어
실제로 나왔다? 그러면 tape의 word vector를 hidden layer의 가중치로 얻을 수 있음 -
Word2vec 이용해서 단어를 벡터 공간에 나열하게 된다??(= 단어의 의미가 벡터로 표현) -> 벡터 연산이 가능해진다
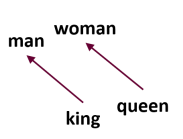
ex) king에서 man을 뺀다 -> king에서 man으로 향하는 벡터 차원 공간 생긴다
이 벡터 차원 공간을 queen에 더한다 -> woman이 나온다
Sparse representation vs Dense representation
Sparse representation
- 원핫 인코딩을 사용한 방법
- 단어의 의미를 유추할 수 없음
- 차원의 저주에 빠짐 (차원이 무한대가 된다면 정보 추출 어려움)
- 원핫 벡터의 차원 축소를 통해 분류해 단점을 해결하려는 연구 진행 중
Dense representation
- Word embedding을 이용!
- 단어 벡터를 한정된 차원으로 표현할 수 있음
- 의미 관계도 유추할 수 있음
- 주변 단어들을 활용하기 때문에 비지도 학습으로도 단어 의미 학습할 수 있다는 장점!!
Word embedding의 성능 검증
-
WordSim353 (similarit 비교)
- 사람이 실제 두 단어를 보고 유사도 표기
- 호랑이와 고양이 7.35, 호랑이와 호랑이 10...
- 벡터 공간에 나열된 워드 임베딩의 벡터 값을 이용해 두 벡터의 유사도 구할 수 있음
- 두 단어의 cosine similarit를 구해서 정답과 Spearman's rank-order correlation 값 획득 --> 임베딩 얼마나 잘됐는지 확인 가능
-
analogy 테스트
- 덧셈 뺄셈을 이용해 판단하자
- Semantic analogy: 의미 관계 판단
대한민국 - 서울 + 도쿄 = 일본 - Syntactic analogy: 문법적 구조 판단 (점수 잘 안 나옴)
밥 - 밥을 + 물을 = 밥
Word2Vec을 정리
-
단어가 가지는 의미 자체를 다차원 공간에 '벡터화'한다
-
중심 단어의 주변 단어들을 이용해 중심 단어를 추론하는 방식!
-
장점
- 단어간의 유사도를 측정하는 데 용이함
- 단어간 관계 파악에도 유용하게 쓰임
- 벡터 연산으로 추론 가능!!
한국-서울+도쿄 = 일본
-
단점
- 단어의 subword information을 무시함 -> 서울vs서울시vs고양에서 공통점을 찾지 못함... 걍 독립된 애다! 라고 생각함, 배운 대로만 생각
- our of vocabulary(OOV)에 적용 불가능 -> 학습에 사용되지 않은 단어가 입력으로 들어오면 사용할 수 없다 ㅠㅠ
Word Embedding - FastText
-
한국어는 다양한 용언 형태를 가진다 (모르다, 모르고, 모르네, 몰라서, ...)
-
Word2Vec은 다양한 용언 표형을 다 서로 독립된 vocab으로 관리함 --> 모르고와 몰라서가 다른 애로 취급됨
-
subword를 활용해서 임베딩을 하면 더 좋은 임베딩이 이뤄지지 않을까?!?
-> Fasttext라는 라이브러리 탄생
FastText
-
학습은 주변 단어를 활용
-
word2vec과 달리, 단어를 n-gram으로 나누어 학습 수행
ex) n-gram 범위가 2-5라면,
assummption = (as, ss, su, ..., ass, ssu, ..., ption, assumption)라는 n-gram set을 만듦 -
input에 assumption n-gram을 넣어서 학습/추론하게 됨
-
최종적 assumption 벡터는 n-gram 벡터를 모두 합쳐서 만들어짐
-
subword들이 n-gram 안에 포함되게 된다!
-
'assum'이 input으로 들어오면, assumption n-gram에 존재하기 때문에 추론이 가능하다 (만들어진 벡터들을 합산함으로써 얻을 수 있음)
-
결과적으로 OOV가 들어오더라도, 걔의 n-gram으로 벡터 만들 수 있다
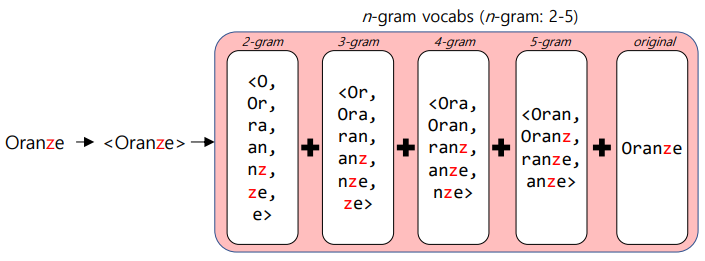
예시
-
FastText는 단어를 n-gram으로 분리한 후, 모든 n-gram vector를 합산해 평균을 내고, 그걸로 단어 벡터를 획득한다
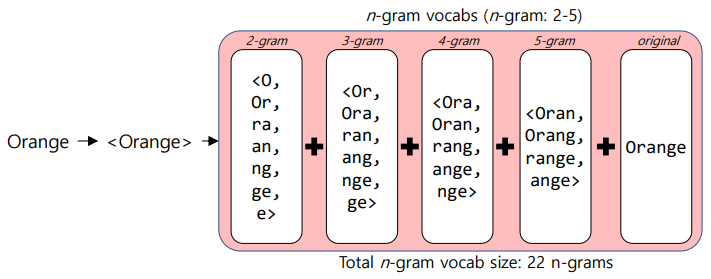
-
'Orange' 입력 예
-
따라서 'Oranges'라는 OOV가 들어왔음 -> 'Orange'로 학습한 n-gram과 매우 유사함 -> 따라서 'Orange'와 유사한 워드벡터 생성 가능
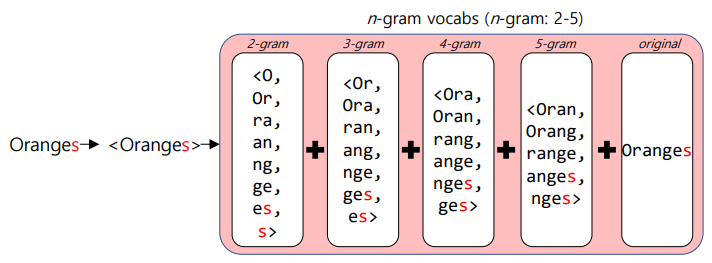
-
오탈자도 OOV로 많이 발생 -> 이것도 워드벡터 얻어 낼 수 있다! 오탈자여도 n-gram은 유사하게 나오기 때문
장점
-
오탈자, OOV, 등장 회수가 적은 학습 단어에 대해서도 강세를 보임
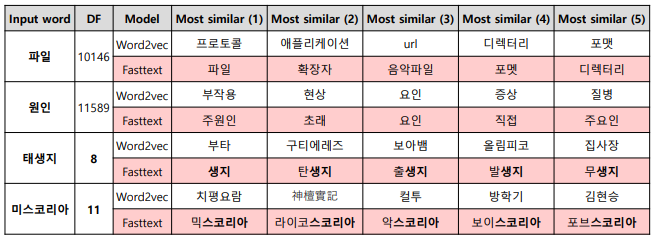
-
word2vec은 DF가 낮을 경우 유의미한 단어를 찾지 못함
-
fasttext는 subword information이 유사한 단어를 찾음
-
한국어는 외래어 표기 시에 오탈자 발생률 높음
-
FastText를 활용하면 이러한 경우에도 유의미한 결과 도출 가능
실습
- 제공된 코드는 실행되지 않아, 강의 다 듣고 다른 코드 실행해 볼 예정
Word Embedding의 활용!
-
워드 임베딩은 다른 자연어 처리의 가장 밑단에서 사용됨
-
어떤 feature를 input으로 넣어야 분류가 되는데, 그 feature를 word embedding을 이용해 word to vector, 즉 벡터 공간을 feature로 사용
-
학습 데이터가 매우 적은데 걔로 분류를 해야 한다? 그럼 데이터 양이 너무 부족하고, 학습 데이터만으로 특성을 추출할 수 없다...
-
BERT로 관련 토픽 키워드 추출 가능~
Word Embedding의 한계점
- Word2Vec이나 FastText와 같은 word embedding은 원래 단어의 주변 단어를 관찰하면서 학습이 이뤄진다
- 동형어나 다의어가 들어오면 분리해서 학습할 수 없다
- 즉, 문맥 고려가 안 된다
질문) 한국어에서 n-gram?
- 어떻게 Word Embedding을 사용? 어떻게 FastText를 사용? 에 따라 많이 달라짐
- 보통은 음절 단위로 n-gram이 이뤄짐 -> 이 경우 오탈자에 대해 임베딩이 약하다는 단점
- 자소(ㄱ-ㅏ-ㅁ) 단위로 분해한 다음 n-gram, 범위를 음절을 포함할 수 있을 만큼 줘야 함
음절이 자소 최대 6개로 이뤄지겠지? 그럼 범위는 6~12 정도!
