언어 모델
모델이란?
- 개념: 주제를 화상 또는 기호 등을 사용해 표현
- 모델의 종류: 일기예보 모델, 데이터 모델, 비즈니스 모델 등
- 모델의 특징
- 자연 법칙을 컴퓨터로 모사함으로써 시뮬레이션 가능
- 이전 state 기반으로 미래 state 예측
- 즉, 미래 state 올바르게 예측하는 방식으로 모델 학습 가능
언어 모델
- '자연어' 법칙을 컴퓨터로 모사 --> 언어 '모델'
- 주어진 단어로부터 다음 등장할 단어를 예측하는 방식
- 다음으로 등장할 단어를 잘 찾는 모델 -> 언어의 특성이 잘 반영됐다, 문맥적 특성 잘 파악한다
Markov 확률 기반의 언어 모델
- 마코프 체인 모델
- 초기의 언어 모델은 다음의 단어나 문장이 나올 확률을 통계와 단어의 n-gram을 기반으로 계산
- 딥러닝 기반의 언어모델은 해당 확률을 최대로 하도록 네트워크를 학습한다

- 언어에 대한 확률값을 다 만들어 놓으면 문장에 대한 확률도 만들어 낼 수 있다!
- 확률을 곱하고 곱하면 문장의 확률도 구할 수 있음
- 초기 모델에서 딥러닝으로 넘어갈 때 어떻게...? 앞의 구조를 신경망 구조로 바꿈 (RNN)
RNN 기반의 언어 모델
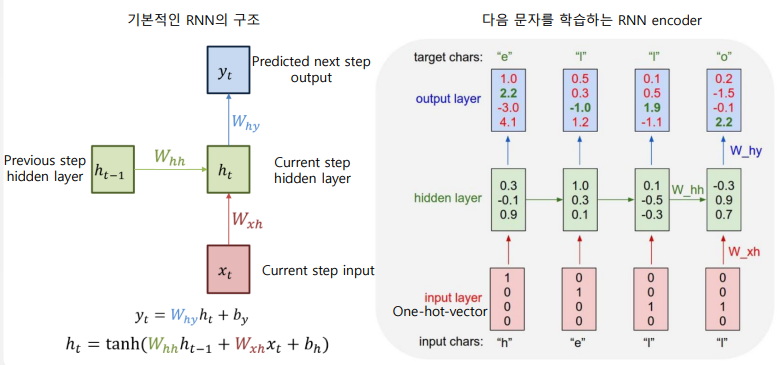
-
Predicted state를 구하기 위해 Current state의 상태를 입력으로 받아 계산
-
이전 state의 hidden state를 입력 --> 다음 애 찾아
-
h를 넣어서 e를 예측하기 위한 hidden layer 깔고, 또 e 넣어서 l 예측하는 hidden layer 깔고...
RNN 언어 모델
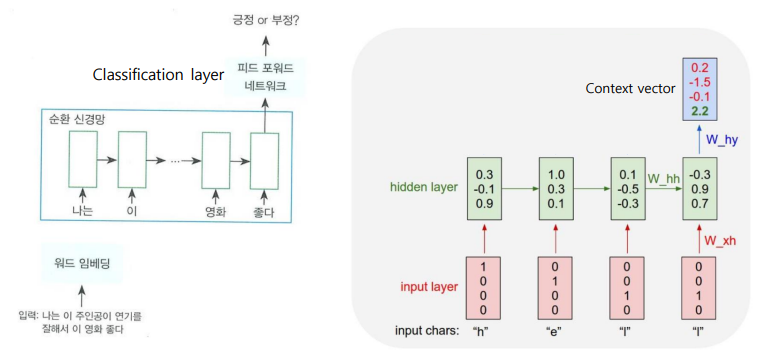
- RNN을 이용하면 앞에 나온 문맥을 고려한 output을 얻을 수 있음
vector -> Context vector- 좋다의 output을 확인해 보면 이 문장이 가진 Context Vector를 얻을 수 있다
- 출력된 context vector 값에 classification layer 붙이면 분류를 위한 신경망 모델이 됨
- RNN으로 언어 모델을 만들어 놓고 거기에 Classification layer를 달아 주면 다양하게 활용할 수 있다, BERT도 마찬가지
- context vector는 좌표평면 위에 나열이 되니까 분류가 되는 것
Encoder - Decoder
- 자연어를 컴퓨터가 이해하기에 앞서 Encoding (context vector)
- RNN을 해석하는 데만 달게 되면? 정보 처리가 이뤄질 수 있다
RNN 모델 기반의 Seq2Seq
- 입력이 sequence로 들어가고, 출력도 sequence로 나온다
- 입력이 문맥이 고려된 RNN을 거치면! Context Vector가 나오고, 이게 다시 RNN을 거치면? 벡터에 대한 해석이 가능해진다
예제
- 음성을 입력으로 넣고 텍스트로 뽑자!
- 비디오를 넣고, 텍스트로 뽑자!
- 텍스트 넣어서 얘가 명사인지 조사인지도 뽑아 볼까?
- 번역도 해 볼래?
- 챗봇도 가능하지~
RNN의 구조적 문제점
- 입력 시퀀스 길이가 매우 길다면, 처음에 나온 토큰에 대한 정보가 희석된다
- RNN은 앞의 내용을 전달전달전달하니까
- Seq2Seq의 최종 output인 context vector는 고정된 벡터 사이즈를 가짐
- 한 단어의 vector를 얻으려면 의미 있는 결과 얻을 수 있겠지만, 문서라면 별로 의미 없음
- 긴 sequence 정보 함축에 대한 어려움
- 모든 token이 영향을 미치기 때문에 중요하지 않은 token들도 중요한 키워드처럼 학습에 사용이 돼 버림 --> 안 좋은 영향
- 이러한 한계 극복하고자 Attention 모델 등장
Attention 모델
- 픽셀의 모든 정보를 다 집중하는 게 아니라 집중해야 할 부분에만 집중하자!!
- 난 널 사랑해 -> 전부 중요하게 생각하는 게 아니라 '난'에 초점을 두는 거면 거기에 어텐션을 줘서 번역을 하자
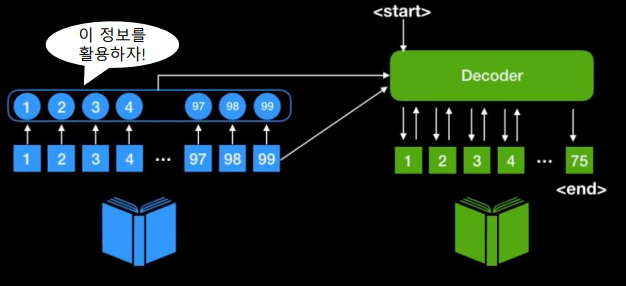
- 기존 Seq2Seq에서는 RNN의 최종 output인 Context vector만을 활용
- Attention에서는 인코더 RNN 셀의 각각 output을 활용 (사진에 이 정보를 활용하자 부분)
- Decoder은 단계마다 RNN 셀의 output을 활용해서 다이나믹하게 context vector 얻어 보자!
단계
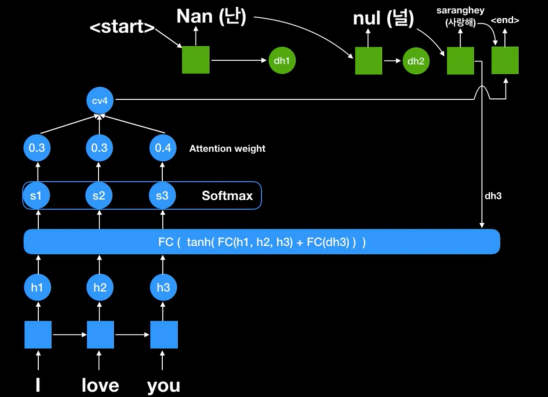
1) 기존 RNN 모델에서 시작
2) 각각의 RNN 셀에서 나온 output을 Feed forward fully connected layer를 거쳐서 Score 생성 (바로 디코더 안 들어가!!)
3) Score에 softmax 취함 -> 0~1 사이의 점수로 나온다! 얘가 Attention weight다 --> Attention 핵심
4) 디코더 들어가기 전에 context vector는 어떻게 구하냐? 나온 score랑 각각의 hidden state를 모두 곱해
5) 구해진 context vector가 Decoder의 input으로 들어감
6) Decoder에서 예측이 일어나고, rnn network의 output이 다시 아래의 입력으로 들어간다...
- 여기서 결과가 많이 다르다? 그럼 좋지 못한 context vector가 들어간 거다, 좋지 못한 context vector? 좋지 못한 attention weight로부터...
7) 최종적으로 Decoder에서 output 출력
장점

input의 어디가 중요하냐? attention weight로 알 수 있게 된다
어느 input과 어느 output이 강하게 연결되어 있는지 시각화가 가능해짐
- 내가 원하는 대로 강하게 attention 연결이 안 되어 있다면 모델이나 설계가 잘못된 것 -> 피드백 받아서 고칠 수 있음
정리
Decoder의 input으로 들어가는 context vector -> attention weight를 이용하여 다이나믹한 context vector를 얻을 수 있다
기존 seq2seq의 encoder, decoder 성능을 비약적으로 향상
하지만 단점... RNN 네트워크를 거치느라 시간이 오래 걸림
-> RNN을 없애는 건 어때? ^^
-> self-attention 모델 등장!
self-attention 모델
- encoder와 decoder에서 RNN 제거함
- ateention 하나만 가지고도 encoding, decoding 잘되고, 학습 잘되고
- RNN+attention에 적용된 attention은 decoder가 해석하기에 적합한 가중치를 찾으려고 노력한 애다
-> 그럼 decoder 말고 input인 애 자체를 잘 표현하기 위해 학습해 보는 건??
-> 좋아~ 자기 자신을 가장 잘 표현할 수 있는 좋은 embedding임!
-> self-attention 모델의 탄생!
목표
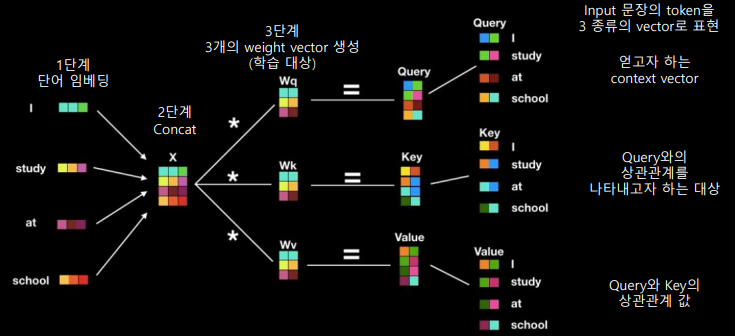
- 스스로를 잘 표현할 수 있는 attention을 구한다
- '딥러닝 자연어 처리 어려워요'라는 문장이 있고, '딥러닝'이라는 쿼리를 날렸을 때 '딥러닝'에 가장 집중할 수 있는 attention을 학습하는 게 목적

- Input 문장의 token을 3종류의 vector로 표현
- 얻고자 하는 context vector는 Query*Key로 얻을 수 있다 (Score)
- Score에 softmax를 취하면 0~1 사이 값이 나오고, 얘가 self-attention의 weight 값이 된다
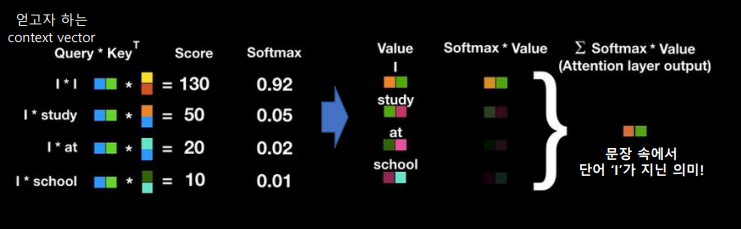
-
self-attention으로 나온 점수 * value = 각각의 중요도가 곱셈으로 표현되게 됨
-
만들어진 애들 모두 합산하게 되면! attention layer의 output, 즉 문장 속에서 'I'가 지닌 의미가 context vector로 표현되게 된다
-
전체로 확장하면?

-
문장 내에서 각각의 단어들이 가지는 중요도를 확인할 수 있겠지?
-
각각의 token에 대한 context vector를 독립적으로 구할 수 있다
Multi-head Self Attention 모델
- Query, Key, Value로 구성된 attention layer 여러 개를 동시에 수행
- RNN은 이전 state를 기다렸다가 다음 state를 예측했지만,
- self-attention은 행렬 연산으로 되어 있음 -> GPU 사용 시 이러한 행렬 연산을 병렬 연산으로 빵! 처리할 수 있다
★ self-attention을 사용하면 병렬 처리가 되기 때문에 여러 개를 놔도 빠르게 처리할 수 있다!
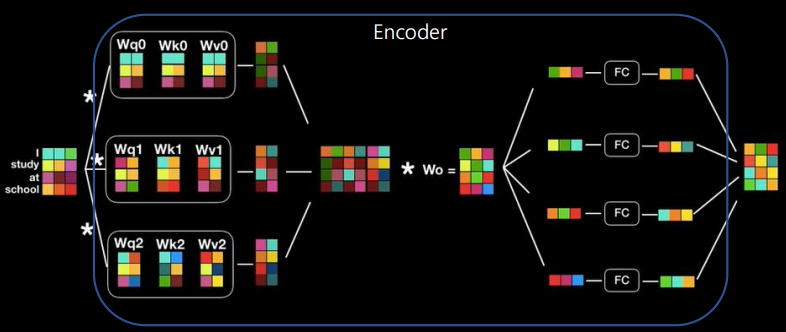
- 최종적으로 자기 자신을 표현하는 vector 획득할 수 있다 ^^
(그냥 참고) BERT는 Multi-head attention을 12개를 달아 버림... -> 학습 진행~
Transformer 모델
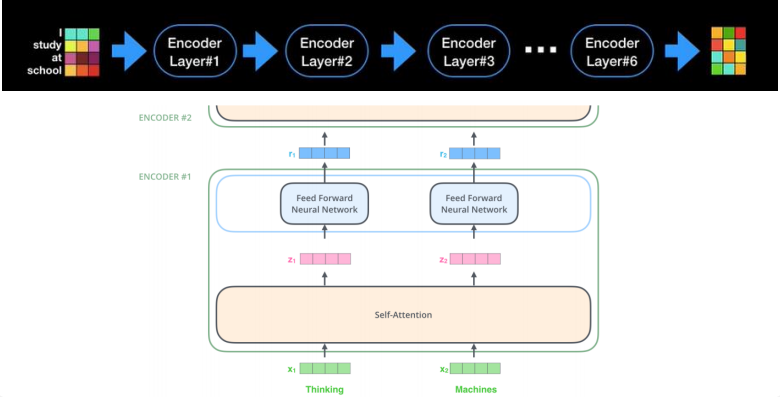
-
multi-head attention으로 이루어진 encoder를 여러 층 쌓아 encoding 수행
-
인코딩을 또 하고 또 하고 또 해서 최종 context vector를 얻는 것
-
BERT가 cost 많이 드는 이유? encoder 안에도 다 복잡하게 구성되어 있고 이걸 다 학습시켜야 하니까 당연히 오래 걸리고 데이터도 많이 필요하다
-
BERT는 어쨌든 인코더임!! 어렵게 생각하지 말자!! 이기자!!
