한국어 BERT
- 지금까지는 multi lingual로 구현했다
- 한국어 BERT는 어떤지 보자!
ETRI KorBERT
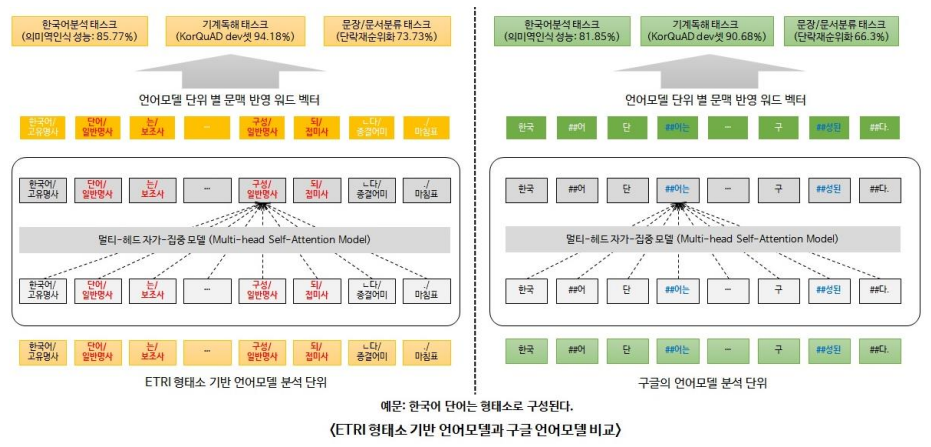
- 기존의 BERT와 Tokenizing 단계가 다름
- 입력 전에 형태소 분석을 해서 줌 -> 웬만하면 텍스트가 더 잘게 쪼개지도록
- Word Embedding 단계에서 형태소 태그를 부착해서 학습하게 되면 동음이의어 등도 형태소가 다르다면 다른 Vocab으로 분류됨
모델 분류
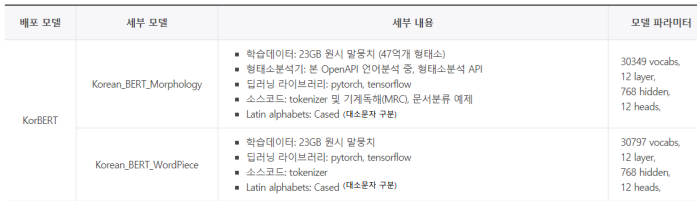
- 형태소 태그 부착, 형태소 분리 후 학습 --> ETRI 형분석기 이용
- 기존은
##단어였다면, 얘는단어_로 써서 단어가 끝났다는 걸 알림
- 기존은
- 기존에 공개된 WordPiece 모델과 동일
- ETRI KorBERT의 input은 형분석 이후 데이터가 입력되어야 한다
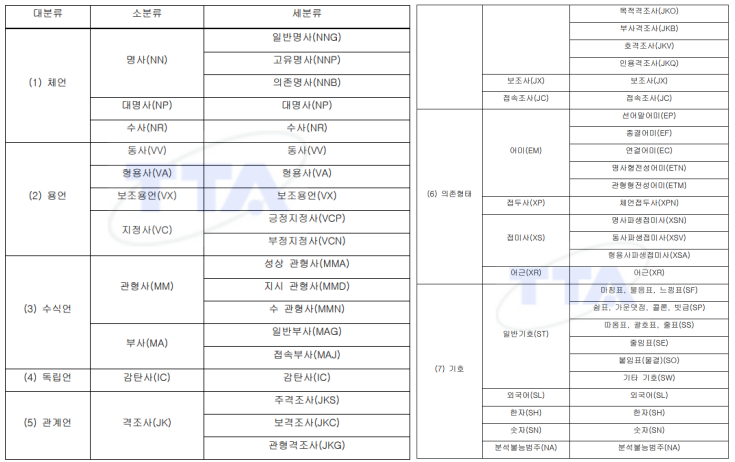
- TTA 기준에 맞춰서 형분석기 사용, ETRI 거 쓰는 게 낫겠지 모...가 아니라 Khaii가 제일 성능 괜찮았다!!
- 근데 강의가 한참 전 거라 지금은 달라졌을 수도...
한국어 BERT 학습
-
대용량 코퍼스 확보
- Dump wiki + news 색인 데이터 (30기가)
- 모아서 한국어 BERT 실험 진행
-
대용량 코퍼스 -> BPE tokenized 코퍼스 -> BERT 모델 -> BERT 기반 MRC 모델
- 성능이 66.06, 79.79로 별로 안 좋았음 왜 그럴까?
BERT 성능에 영향을 미치는 요인
- Corpus 사이즈
- Corpus 도메인
- Corpus tokenizing (어절, BPE, 형태소)
- Vocab 사이즈
--> 다양하게 조절해 보았다... -> 그냥 전처리가 문제였다
전처리를 잘하자!!!


α CMa