BERT
-
bi-directional Transformer로 이루어진 언어 모델!
-
SQuAD 데이터 셋 -> 본문이 있고, 본문에 대한 질문을 넣으면 답변이 나오도록 되어 있음
-
기존의 모델들은 사람의 performance를 뛰어넘기 힘들었는데, 버트는 나오자마자 이겨 버림
- 원래는 BERT에 이것저것 많이 달아서 성능을 높이고 있었는데 다른 모델들이 나오면서... 1등은 뺏김...
-
잘 만들어진 BERT 언어모델 위에 classification layer만 부착하면 다양한 NLP task 수행 가능
BERT 모델의 구조도
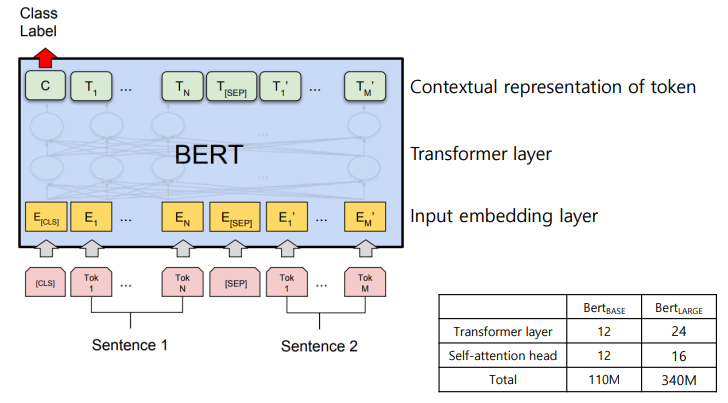
- input은 sentence 2개를 받음
- sentence를 토큰 단위로 임베딩하고,
- transformer layer(12개)를 거친다
- 최종적으로 input으로 들어온 본인을 표현하는 모델
BERT 모델 학습 데이터
-
영어 데이터에 대한 데이터셋만 표현이 되어 있는데,
- 30억 어절의 데이터를 이용해 학습
- 3만 개의 토큰을 사전으로 사용해 학습
-
WordPiece tokenizing! 사용!
- 버트는 영어 모델 공개 시 multi lingual 모델도 같이 공개했음
- 한국어 모델 하나만 만드는 것도 어려운데, 어떻게 멀티 링구얼 모델 (100개 넘는 언어)를 만들었을까? --> WordPiece를 사용했기 때문
- 빈도 수에 따라 분리하는 토크나이징 방법
He likes playing -> He likes play ##ing-> ing는 좀 자주 나오니까 떼 주자
BERT의 WordPiece tokenizing
- Byte Pair Encoding (BPE) 알고리즘 이용
- 빈도 수에 기반해 단어를 의미 있는 패턴(Subword)으로 잘라 tokenizing
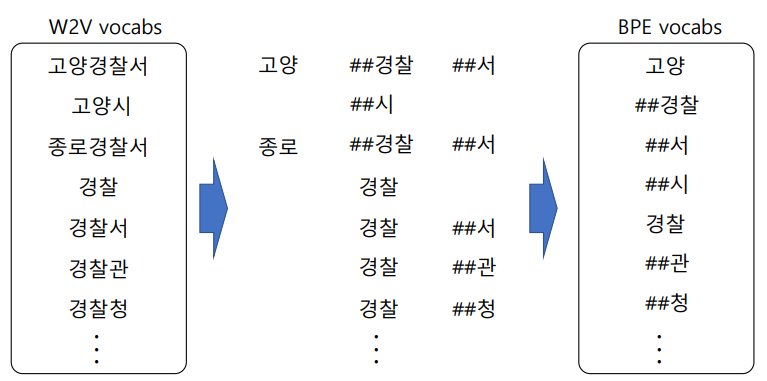
- W2V 모델을 사용하면 고양경찰서, 고양시, 종로경찰서, 경찰, 경찰서 ... 등등의 유사성을 판별하지 못함
- BPE 알고리즘을 사용하면... 많이 등장할 것 같은 애들을 다 token 단위로 잘라서 vocabs 만듦
- 고양, ##경찰, ##서, ##시 등등으로 이루어짐
과정
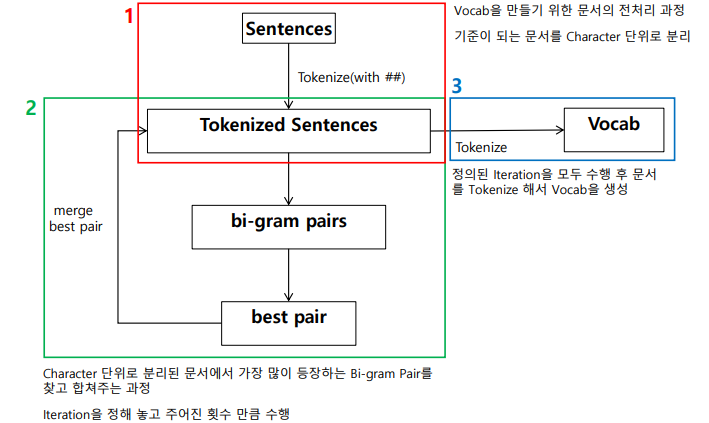
1-1) Sentences - Tokenizing할 대상, 얘를 이용해 Vocabs를 만들기 시작
1-2) 모든 캐릭터 단위로 Tokenizing 진행
2-1) 빈도 수가 많이 나오는 캐릭터 묶음이 있을 것 --> Iteration만큼 반복해서 돌면서 확인
2-2) 특정 Iteration만큼 돌아서 만들어진 Vocab을
3) 저장하게 된다!
예제
Tokenize 대상: 경찰청 철창살은 외철창살이고 검찰청 철창살은 쌍철창살이다
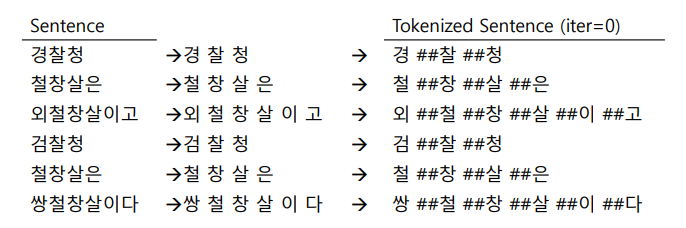
- 대상을 어절 단위로 분리 -> 캐릭터 단위로 분리 -> 두 번째부터 등장하는 캐릭터에 ##을 붙인다!
- 왜? 같은 글자라고 해도 맨 앞에 나오는 '철'과 중간에 나오는 '철'은 다른 의미가 있을 거다
- Vocab은 어떻게 만들어?
- 캐릭터 단위로 토크나이즈된 sentence에서 중복 제거 -> Vocab 후보 생성
- Bi-gram Pair Count
- Vocab 후보를 기준으로
토크나이징된 애를 가지고 Bi-gram pair를 만든다! 두 개씩 이어서... - Bi-gram pairs 만듦
- 만들어진 Bi-gram pairs에서 빈도 수를 구해
-> 가장 높은 빈도 수를 보이는 Bi-gram pair를 찾을 수 있음
- Vocab 후보를 기준으로
- Merge Best pair
- Best Pair은
##창 ##살--> 중요하다는 거니까 하나로 합쳐!##창살 - 캐릭터 단위로 다 분리되었던 애에서 ##창, ##살을 ##창살로 합쳐 줬다
- Best Pair은
- 다시 Vocab 생성 단계로 와서
- Vocab 후보 업데이트
- Bi-gram Pairs 구하고, 빈도 수 찾아
- 같은 빈도 수가 등장하면 그냥 돌려서 처음으로 나온 애 하나를 Best Pair로
- Merge Best pair
- 이번엔
##찰 ##청이 Best pair --> 하나로 합치기##찰청
- 이번엔
- 이 과정을 Iteration만큼 진행하면 최종 Vocab이 저장된다
- Vocab 생성 --> 정해진 Iteration 모두 수행 후!!! (매 Iteration마다 생성되는 건 Vocab이 아니라 Vocab '후보'임)
BERT Tokenization 예시
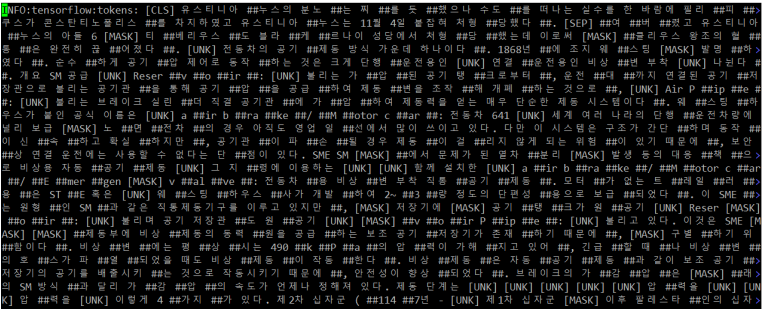
- BPE를 이용해 subword로 분리했어. 그래도 vocab에 존재하지 않는 애가 있다? [UNK] 토큰으로 변환해
Masking 기법 (BERT input)
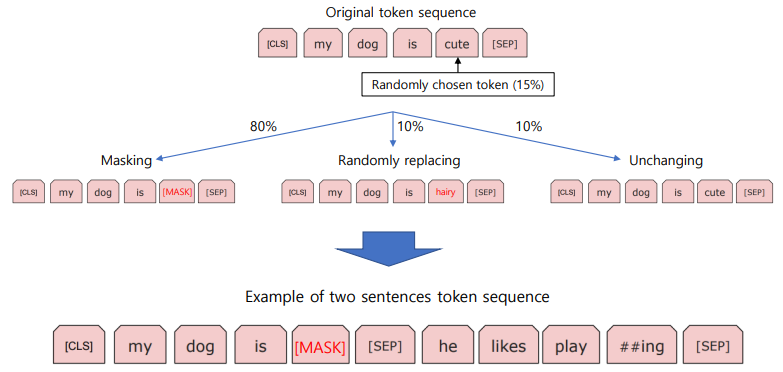
- input은 학습 데이터의 첫 번째부터 문장을 하나 가져온다
- 문장 시작 지점에 [CLS] 토큰, 끝 지점에 [SEP] 토큰을 붙임
my dog is cute의 경우 토큰이 4개다, 랜덤한 확률(15%)로cute를 선택했다고 가정- 80%는 Mask로 바꿔 버려
- 10%는 랜덤하게 다른 단어를 선택해 replace
- 나머지 10%는 안 바꿔
- 그림 맨 밑처럼 바뀌게 되겠지?!
[CLS] my dog is [MASK] [SEP]
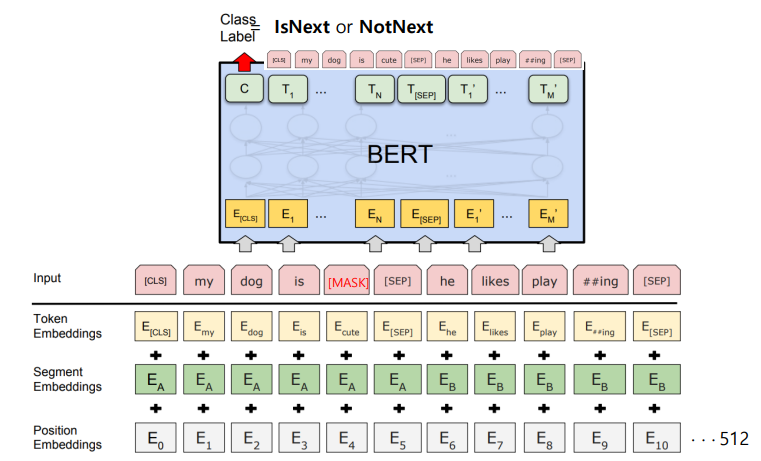
- BERT는 input sentence를 예측(출력)하는 방식으로 학습이 이뤄짐
- input으로 sentence가 들어가서 --> transformer 거쳐 --> 원래의 문장 예측!
- MASK 된 단어도 원래의 단어로 나오도록 학습이 진행
- 두 번째 sentence는 다음 문장일 수도 있고, 아예 다른 문장일 수도 있다
- 두 가지 학습
- IsNext? NotNext? --> 다음 sentence 예측
- MASK --> MASK 된 애 원래 값 찾아
- Input 데이터는 세 가지 Embedding을 거치게 된다
- Token Embedding -> 토큰 단위로
- Segment Embedding -> 어떤 sentence인지
- Position Embedding -> 토큰 위치 (순서)
NLP 실험

- 그냥 이런 실험을 했군...
- 한국어는 이러한 데이터셋이 부족해서 BERT로 성능 평가하는 데 어려움이 있음
- 결과는 생략
BERT 적용 실험
- 감성 분석
- 네이버 영화 리뷰 코퍼스를 이용해 감성 분석 진행
- QnA 문장 유사도 (이진 분류 기반)
- 디지털 동반자 패러프레이징 질의 문장 데이터 활용해 질문-질문 데이터 생성 및 학습!
- 하지만 실제 사례에서는 확실하게 구분되는 애보다 애매모호한 애가 더 많이 사용됨 --> 의미 유사한 모호한 애로 실험하면 정확도 떨어짐
- QnA 문장 유사도 (문장 벡터 기반)
- 애매모호한 애를 이겨내 보자,,, --> 정확도 올리기 성공
- 그 외에도 관계 추출 실험, 개체명 인식, 기계독해 실험, TOEIC 문제 풀이 등등 다양한 실험에 적용해 봤음!
- 정리는 별로 의미 없는 것 같아서 생략합니다 :D

α CMa