
Multimodal Machine Learning
본 포스팅은 CMU Multimodal Machine Learning, Fall 2023 강의를 듣고 정리한 내용입니다. 본 강의는 위 링크에서 찾아볼 수 있습니다. 정리한 내용은 혼자서 이해한 내용을 바탕으로 작성한 내용으로 100% 정확하지 않습니다.
개요
이번 포스팅에서는 2-1강 Unimodal representation강의를 듣고 각 모달리티에서 하나의 모달리티일 때의 기본적인 표현들을 정리하려고 한다. 하나의 모달리티에서는 우리가 원래 배우던 내용들과 일치하기 때문에, 간단하게 정리한다.
Visual modality

먼저 visual modality에 대해서 살펴본다. 우리가 흔히 사용하는 Image는 픽셀로 구성되어 있다. 각각의 픽셀은 로 표현된다. 여기서 d는 채널의 수(RGB인 경우 d=3).
즉 visual modality에서는 pixel 값들의 모음, 즉 vector로 표현된다. 이미지의 pixel값들을 일렬로 늘어선 형태로 표현한다.
그렇게 표현된 vector값으로 우리가 원하는 task를 수행할 때의 Input으로 들어간다.
Language modality
Language modality의 경우 단어들을 one-hot encoding해서 one-hot vector로 표현한다. 그래서 input observation은 문장의 단어들을 one-hot encoding한 vector가 된다.
그렇게 표현된 vector를 우리가 Word-level clssification의 경우, 그것이 명사인지, 동사인지 구분할 수 있고, 감정이 어떠한지, 긍정인지 부정인지 분류할 수 있다.
Document-level classification의 경우에는 input observation을 bag-of-word vector로 표현할 수 있다. bag-of-word는 단어들의 출현 빈도를 통해서 표현하는 방법이다.
Acoustic modality
소리에 대한 정보를 어떤식으로 표현할 수 있는가를 생각해보는 것이다.
신호처리에서 배우는 영역들이 등장하는데, sampling rate, time window size 등을 통해서 신호를 디지털화 시켜서 정보를 표현한다.
Sensors
sensor 데이터도 생각해볼 수 있는데, sensor는 그 특성에 따라서 다르지만, 주로 time series 데이터로 표현한다.
이 밖에도 Graph, Table등의 Unimodal representation 방식이 있다.
Image representations
이미지를 어떻게 표현할 수 있을까?
가장 간단한 방법으로는 앞서 언급했듯이 image를 vector로 바라보는 것이다.
하지만 최근에는 더 복잡한 task를 위해서 image를 list of object로 바라보는 관점이 주를 이룬다. 이를 object-based visual representation이라 한다.
object-based visual representation
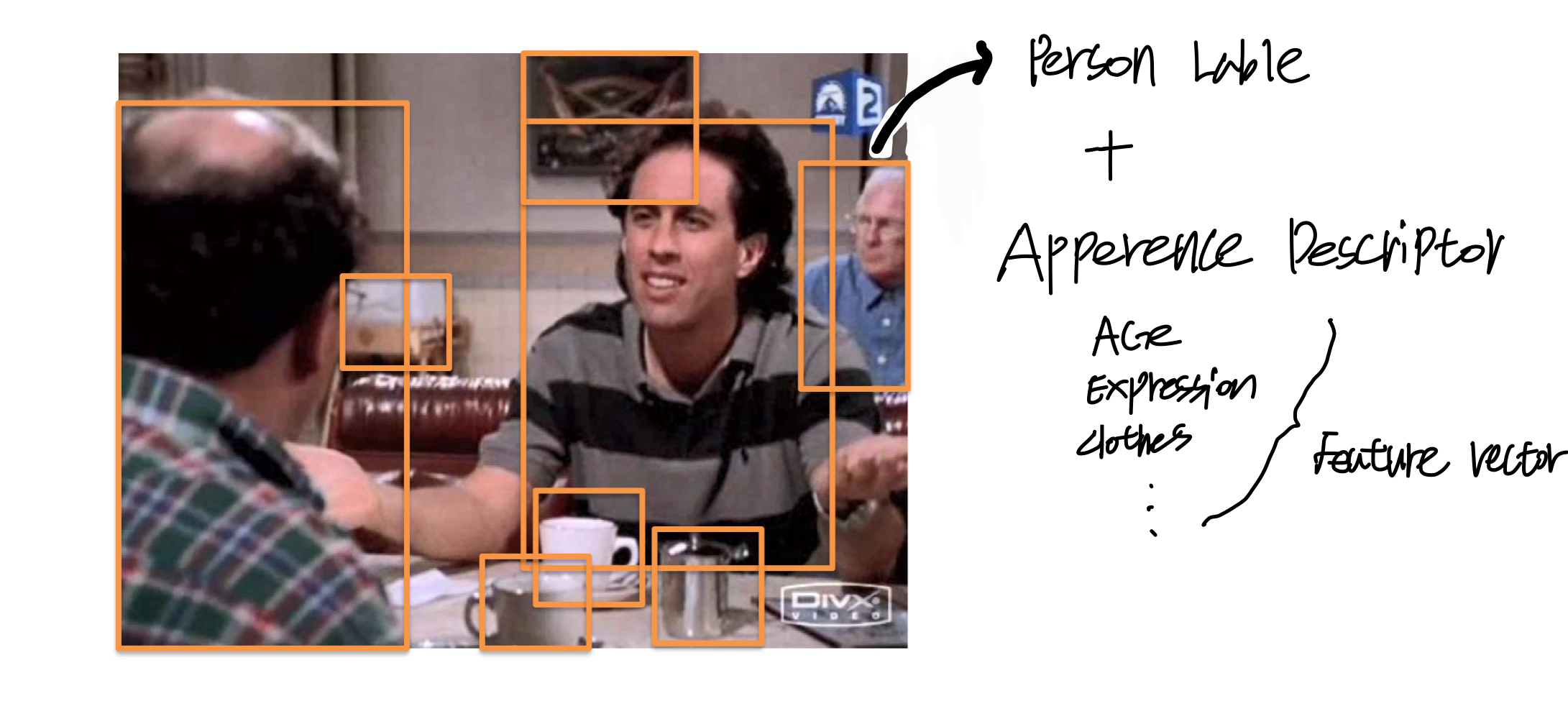
label이 포함된 객체와 추가적인 feature를 가지고 이미지를 표현한다. 추가적인 feature를 object descriptors라고 한다. 말 그대로 오브젝트를 추가적으로 설명할 수 있는 항목들이다.
그래서 가장 효율적인 방법의 image representation이라고 한다면 요즘은, image-> blackbox에 넣어서 연산을 하고, 결국에는 list of boundingbox(object), label, visual dense representation으로 표현하는 방식이다.
그렇다면 어떻게 object를 표현하고 탐지할 것이냐?? --> 많은 방법들이 있었지만, 현재는 유명한 convolution kernel를 이용한 방법이다.
