Multimodal Machine Learning
본 포스팅은 CMU Multimodal Machine Learning, Fall 2023 강의를 듣고 정리한 내용입니다. 본 강의는 위 링크에서 찾아볼 수 있습니다. 정리한 내용은 혼자서 이해한 내용을 바탕으로 작성한 내용으로 100% 정확하지 않습니다.
개요
지난 포스팅에서는 visual modality에 대해서 어떤 방법으로 visual modality 즉 시각 정보를 표현하는지를 가볍게 살펴봤는데, 이번 포스팅에서는 lecture2-2 강의를 듣고 정리를 해보려고 한다.
이번 강의는 Language modality의 representation에 대해서 다루면서 어떤 방식들로 발전해왔는지를 가볍게 살펴본다.
Simple Word representation
가장 먼저 단어를 어떻게 표현할지에 대한 내용이다. 가장 간단한 방법은 단어들을 one-hot encoding을 통해서 one-hot vector로 나타내는 방법이다. 그렇게 나타낸 vector를 우리가 원하는 task에 input으로 넣는 방식이다.
One-hot Encoding
one-hot encoding을 위해서는 먼저 Word dictionary를 정의해야한다. Word dictionary는 데이터에 있는 단어들을 집합으로 나타내고 인덱스를 부여한 것이다. 집합이기 때문에 중복 없이 서로 다른 단어들이 들어가 있다.
예를 들어서 문장 I study ai라는 문장에 대해서 Word dictionary를 만들면 다음과 같이 만들어질 것이다.
word_dictionary : {
'i' : 0,
'study' : 1,
'ai' : 2
}단어 사전이 만들어졌으면 이제 단어를 one-hot encoding할 수 있다. I study ai에서 study라는 단어를 encoding vector로 표현하면 [0,1,0]으로 나타낼 수 있다. 단어 사전 상에서 study가 인덱스 1로 나와있기 때문에, 인덱스 1 위치에 '1'(hot) 표시를 해주면 된다.
이런 방식으로 단어를 표현하는 것이 one-hot encoding 방식이다. one-hot encoding 방식은 문장에서 단어의 존재 여부를 포착할 수 있지만, 단어들간의 semantic relationship이나 문맥상의 의미, 단어 유사도를 포착하지 못한다. 또한 단어의 수가 많아지면 vector의 차원 수가 증가하기 때문에 대용량 데이터를 처리할 때 단점이 존재한다.
결국 중요한 것은 단어의 의미를 어떻게 하면 잘 포착하고 표현할 수 있을지에 대한 문제를 해결해야 한다는 것이다.
여기에서 우리가 새로운 단어를 배울 때를 잘 생각해보면, 단어 하나를 보는 경우도 있지만, 대부분 문맥상에서 단어의 뜻을 유추하는 경우도 있다. 이런 아이디어에서 나온 방법이 Distribution hypothesis 방법이다.
Distributional Hypothesis
Distributional Hypothesis는 "단어의 의미를 그 단어의 주변 단어들로부터 예측한다"로 간단하게 생각할 수 있다.
Distributional Hyporhesis에 기반해서 단어를 이해하기 위해서 Co-occurrence matrix를 계산해서 표현하게 되는데, 이는 주변 단어들이 얼마나 자주 등장했는지를 보고 단어의 의미가 비슷한 단어들끼리 vector space에 인코딩해서 뜻을 표현하기 위함이다.
그러나 이 방법도 단어와 같이 나타나는 빈도를 가지고 표현하기 때문에, 몇 가지 단점이 존재한다.
- 대규모 데이터 셋을 처리할 때에는 정말 희소한 문맥에서 나타나는 단어가 존재할 수 있다. 이런 경우에는 Co-occurrence matrix가 sparse하게 나타날 수 있다.
- 단어의 다중의미를 무시할 수 있다.
- 단어간의 거리를 기반으로 하지 않기 때문에, 단어의 의미를 제대로 포착하지 못할 수 있다. 예를 들어서 very 와 good 은 자주 함께 나타나지만, very와 bad가 함께 나타나는 경우보다 good과 bad가 함께 나타나는 경우가 더 많을 수 있다.
Co-occurrence를 직접적으로 포착하는 방법 대신에 모든 단어에 대해서 주변 단어를 예측하는 방법이라면 단어간의 의미적인 유사성을 포착할 수 있지 않을까 하는 방법이 흔히 자연어처리에서 배우는 Word2Vec 방법이다.
word2vec은 두 가지 방법으로 구현이 가능하다.
1. skip-gram
2. Continuous Bag of Words(CBOW)
Skip-gram 모델에서는 특정 단어를 입력으로 받아 그 주변의 단어를 예측하는 방식이다.
CBOW 모델에서는 반대로 주변 단어들을 입력으로 받아 중심 단어를 예측하는 방식이다.
이런 방식으로 학습된 모델은 단어의 분산 표현(distributed representation)을 학습하게 되는데, 이는 단어 간의 의미적 유사성을 포착할 수 있습니다.
word2vec 부터 단어의 의미를 표현하기 위해서 신경망이 사용된다.
Sentence representations and sequence modeling
이제는 단어 하나의 의미와 표현이 아닌, 문장 전체를 어떻게 표현할 것인가를 다룬다. 이제부터는 RNN과 Language model이 등장하게 된다.
Recurrent neural networks
Sequence modeling은 이전의 요소를 기반으로 input sequence의 다음 요소를 예측하는 task라고 볼 수 있다. 그렇기 때문에 CNN이나, DNN과 같은 feed-forward network는 다음의 특징 때문에 Sequence modeling task에서 사용하지 않는다.
- Independent outputs
- Fixed length input
- Non-sharable parameters
RNN은 보통의 Feed forward network와 달리 은닝층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층으로 보내면서 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 가지고 있다. RNN은 각 timestep간의 같은 weight와 bias를 공유하는 특징을 가지고 있다.
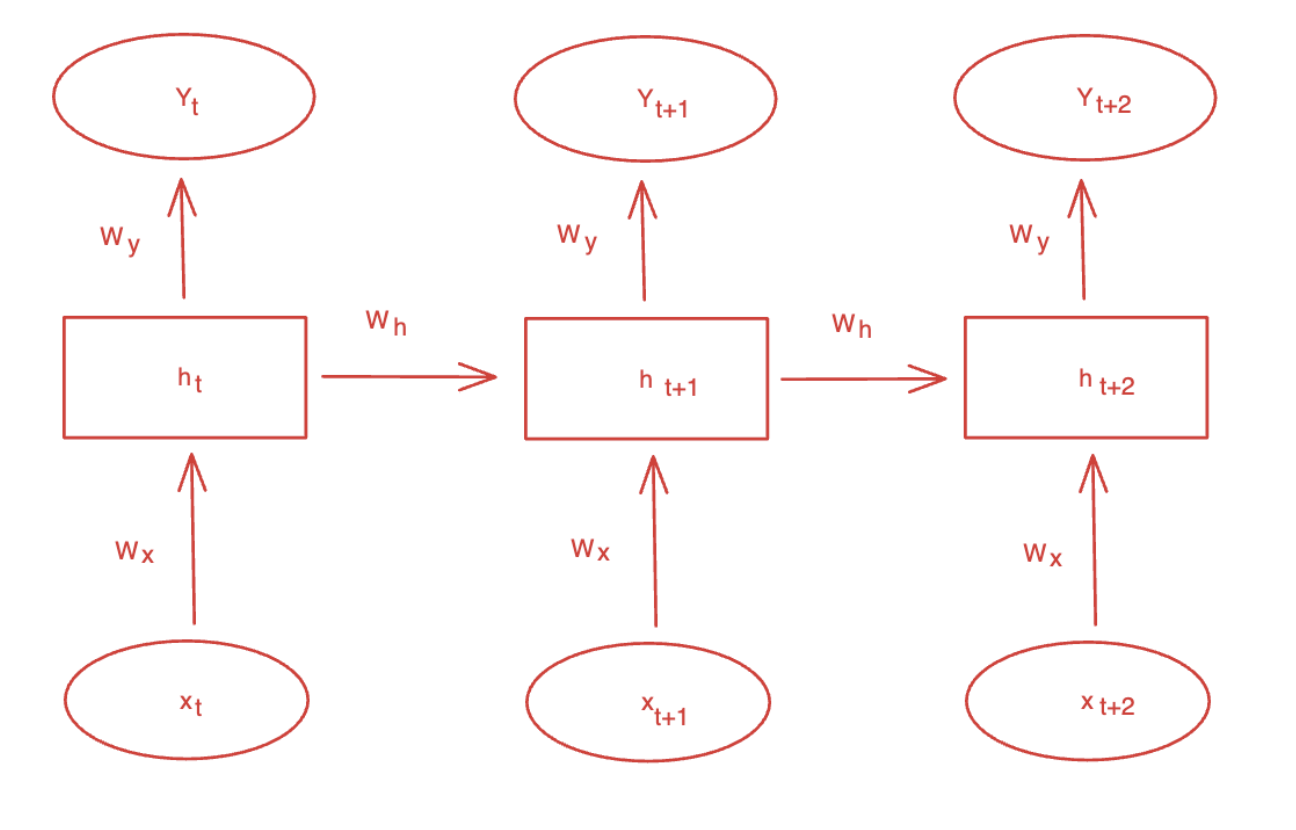
Forward
예를 들어서 y1을 계산한다고 하면 다음과 같다.
Backward
위와 같은 방식으로 각 output을 계산한 후에 각각에 대해서 loss를 계산한다. 그리고 전체 loss의 경우에는 각각의 loss를 더해서 계산한다. 계산한 loss를 기반으로 timestep 전체에 대해서 backpropagation을 진행한다. 이를 보통 back-propagation through time 이라고 부른다.
Language models
Language model application으로 speech Recognition이 대표적인데
여기서 부분을 Language model이 담당한다고 볼 수 있다.
참고
(도서) 딥러닝을 이용한 자연어 처리 입문 https://wikidocs.net/21668
(포스팅) https://medium.com/@rayanimran307/comparing-text-preprocessing-techniques-one-hot-encoding-bag-of-words-tf-idf-and-word2vec-for-5850c0c117f1
