
검색
선형 검색
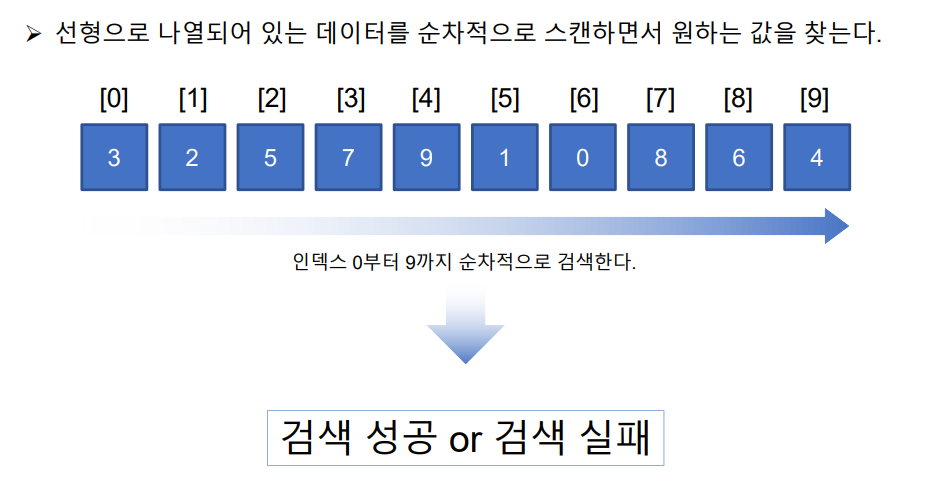
말그대로 선형으로 나열되어 있는 데이터를 순차적으로 스캔하면서 원하는 값을 찾는다.
인덱스 0 부터 순차적으로 검색한다.
검색 성공 or 검색 실패
< 선형검색 기본코드>
datas = [3,2,5,7,9,1,0,8,6,4] print(f'datas: {datas}') print(f'datas length: {len(datas)}') searchData = int(input('찾으려는 숫자입력: ')) searchResultIdx = -1 n = 0 while True: if n == len(datas): searchResultIdx = -1 break if datas[n] == searchData: searchResultIdx = n break n += 1 print(f'searchResultIdx:{searchResultIdx}')
근데 여기서 또하나의 개념이 등장한다.
바로 보초법!!!!!!
보초법은 맨 끝에 판별할 수 있는 보초(문제에서는 사용자 입력 숫자)를 세워두고
그 숫자가 등장했을때 판단 없이 없다고 판별해줌!
그냥 들었을 때는 아니 어차피 끝까지가서 비교해주는 데, 결국 보초법도 보초한테까지 가는데 뭐가 다르다고???
그렇게 검색을 한 결과 내 생각에는!
코드가 말해준다.
<보초법을 쓸 코드>
n = 0 while True: if datas[n] == searchData: if n != len(datas)-1: searchIdx = n break
!!!!!!
보초 하나로 while문이 이렇게 간결해질 수가 있다니...!
(그래서 더 빠르다는 것)
위에 코드는
n과 search 데이터가 일치하면 True
근데 거기서 인덱스로는 마지막(len(datas)-1)이 올때까지 찾았다면 자료가 있으니까 True
없으면 False이기에 없는 거임.
위에보다 판단이 짧은 명령문으로 되어있기때문에 판독이 빠르다.
이진검색
다른 수강생분들도 그랬는지 모르겠지만 이진검색이 훨-씬 이해도 빠르고 그만큼 코드 이해도 금방 따라갔다.
이진검색이란?
★정렬되어★ 있는 자료구조에서 중앙 값과의 크고 작음을 이용해서 데이터를 검색한다.
중앙 값보다 작다
↓
그럼 다시 그 구간에서 중앙값과 비교
↓
검색될 때까지 반복

<이진검색 코드>
datas = [1,2,3,4,5,6,7,8,9,10,11] print(datas) print(len(datas)) searchData = int(input('searchData : ')) serachResultIdx = -1 staIdx = 0 endIdx = len(datas)-1 midIdx = (staIdx+endIdx) // 2 midVal = datas[midIdx] print(f'midIdx : {midIdx}') print(f'midVal : {midVal}') while searchData <= datas[len(datas)-1] and searchData >= datas[0]: if searchData == datas[len(datas)-1]: serachResultIdx = len(datas)-1 break if searchData > midVal: staIdx = midVal midIdx = (staIdx+endIdx) // 2 midVal = datas[midIdx] print(f'midIdx : {midIdx}') print(f'midVal : {midVal}') elif searchData < midVal: endIdx = midIdx midIdx = (staIdx+endIdx) // 2 midVal = datas[midIdx] print(f'midIdx : {midIdx}') print(f'midVal : {midVal}') elif searchData == midVal: serachResultIdx = midIdx break print(f'serachResultIdx:{serachResultIdx}') staIdx = 0 endIdx = len(datas)-1 midIdx = (staIdx+endIdx) // 2 midVal = datas[midIdx]
4가지 개념을 잘만 이해하면 다른건 따라온다.
시작값, 끝값, 중간값의 인덱스, 중간값 설정
+++ 내가 쉽게 놓치는 while문의 조건부
searchData <= datas[len(datas)-1] and searchData >= datas[0]
찾는 데이터가 그 리스트 안에서만 돌 수 있게 명시하는 부분
datas[len(datas]-1] 끝과 같거나 작을때 그리고 datas[0] 처음보다는 크거나 같을때
조건식 안으로 들어온다!
순위 검색
수의 크고 작음을 이용해서 수의 순서를 정하는 것을 순위라고 한다.
자료구조 내부에 있는 데이터끼리 비교를 해서 인덱스를 하나씩 올려줘서 순위를 매김.
개념은 쉬운데, 이렇게 활용해서 순위를 매길 수 있구나 놀랬다.
import random nums = random.sample(range(50,101),20) ranks = [0 for i in range(20)] print(nums) print(ranks) for idx, num1 in enumerate(nums): for num2 in nums: if num1 < num2: ranks[idx] += 1**ranks = [0 for i in range(20)]**변수 담기를 for문을 이용할 수 있음..!
rank는 점수를 담기위한 변수그릇 (활용도 上)★★if num1 < num2: ranks[idx] += 1비교하여 작으면 idx값을 하나먹여 (마치 랭크의 순위가 올라가듯) 뒤로 보냄
데이터를 담는 곳과 순서 담는 곳을 달리해서 순서매김
💬 코멘트
제로베이스 데이터취업반 3주차
알고리즘..! 유튜브 알고리즘만 듣던 나에게는 새롭고도 어려운 개념이였다.
그래도 제로베이스의 장점이라함은 개념수업과 실습수업이 나뉘어서 한번 더 활용이 들어간다는 것.
그래도 오늘은 생소한 개념의 이야기라 거의 따라쓰는 건 고사하고 이해없이 떠밀려가다간 더 크게 넘어질 수 있겠다 싶어. 목표 수강치는 다 듣고 복습을 좀 나눴다. 이해 안되는건 추가 검색도 해가면서 이제야 조큼 큰 구조내에서 오늘 배운게 이렇게 나뉘는 거구나 싶었다. (그래도..더 깊은 이해를 위해 토요일에는 정렬을 좀 더 공부해야지)
