
자료구조(data structure)는 자료들을 저장하는 방식에 관한 것이다. 흔히 추상자료형(abstract data type)과 혼용해서 사용하기도 하는데, 자료구조는 추상자료형이 실재로 구체화한 것이다.
Stack
스택은 후입선출(Last In First Out, LIFO)이다. 함수 호출 등 스택 메모리 구조에 사용된다.
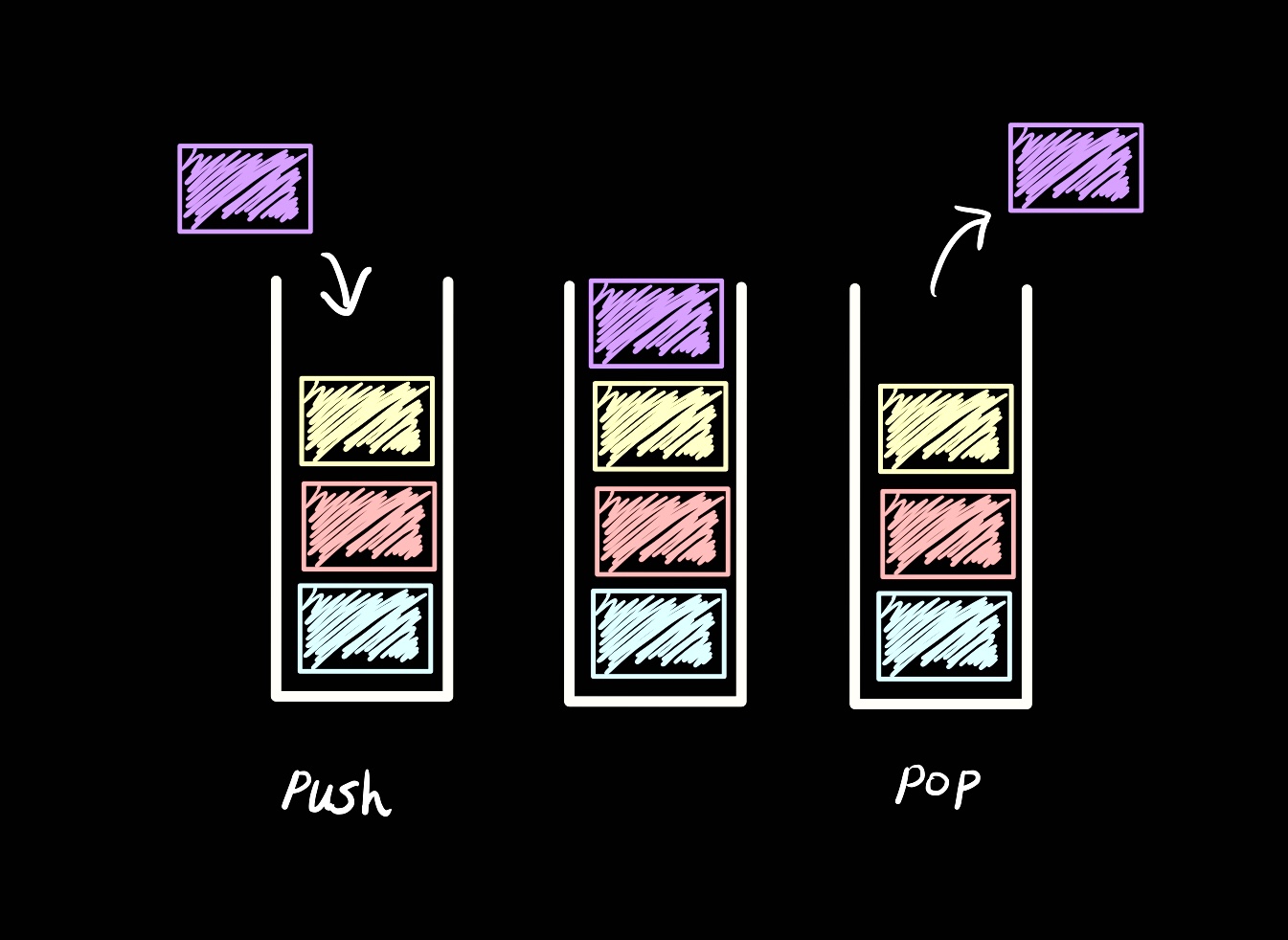
insert/push = 요소 삽입
delete/pop = 가장 나중에 들어온 요소 삭제
peek/top = 가장 나중에 들어온 요소 확인
Queue
큐는 선입선출(First In First Out, FIFO)이다.

insert = 요소 삽입
delete = 가장 오래된 요소 삭제
peek = 가장 오래된 요소 확인
Priority queue
우선순위 큐는 요소의 우선순위에 따라 동작되는 자료구조다. 프로세스 스케쥴링에 사용된다.

insert = 요소 삽입
delete = 우선순위가 가장 높은 요소를 삭제
peek = 우선순위가 가장 높은 요소를 확인
Heap
max heap
부모 노드의 key값이 자식 노드보다 크거나 같을 때의 이진 트리 구조다. 힙정렬에도 사용된다. 힙으로 자료구조를 만들어 놓은 뒤 하나씩 delete하면 정렬되어 나오기 때문.
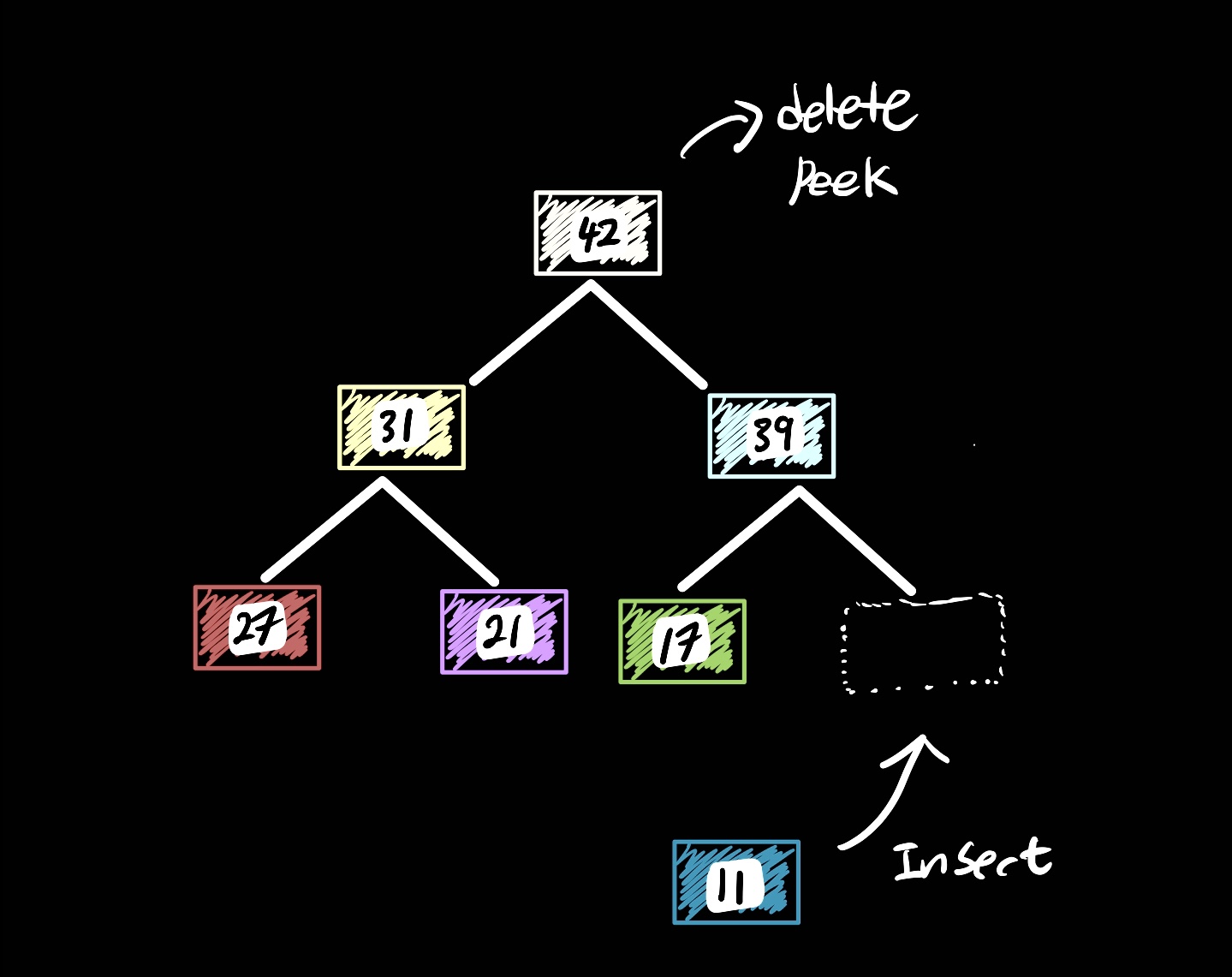
insert = 마지막 요소의 다음 위치에 요소 삽입하면서 부모 노드 key값보다 작은지 확인
delete = key값이 가장 큰 요소(root)를 삭제, 마지막 순서에 있는 노드가 root자리로 온 뒤 다시 비교하면서 스위치 해줌
peek = key값이 가장 큰 요소를 확인
min heap
부모 노드의 key값이 자식 노드보다 작거나 같을 때다. max heap과 같은 방식으로 동작한다.
insert = 마지막 요소의 다음 위치에 요소 삽입하면서 부모 노드 key값보다 큰지 확인
delete = key값이 가장 작은 요소(root)를 삭제, 마지막 순서에 있는 노드가 root자리로 온 뒤 다시 비교하면서 스위치 해줌
peek = key값이 가장 작은 요소를 확인
힙을 우선순위 큐에 포함시키는 이유?
흔히 생각하는 큐 구조와 트리구조는 전혀 다른 것임에도 우선순위 큐를 구현할 때 힙 구조로 구현하는 경우가 많다.
이는 우선순위 큐는 ADT, 즉 추상자료형이고 힙은 DS, 자료구조로 실제 동작이기 때문이다. 큐는 보통 선입선출 구조를 말하지만, 실제 사용 시에는 선입선출과 무관하게 대기하는 공간을 그냥 큐라고 부르는 경우가 많다.
비슷하게 동적배열은 ADT로 vector로 구현되고, 같은 ADT인 연관배열은 map 또는 dictionary로 구현된다.
List
리스트는 값을을 저장하는 ADT로 순서가 있고 중복도 허용된다.
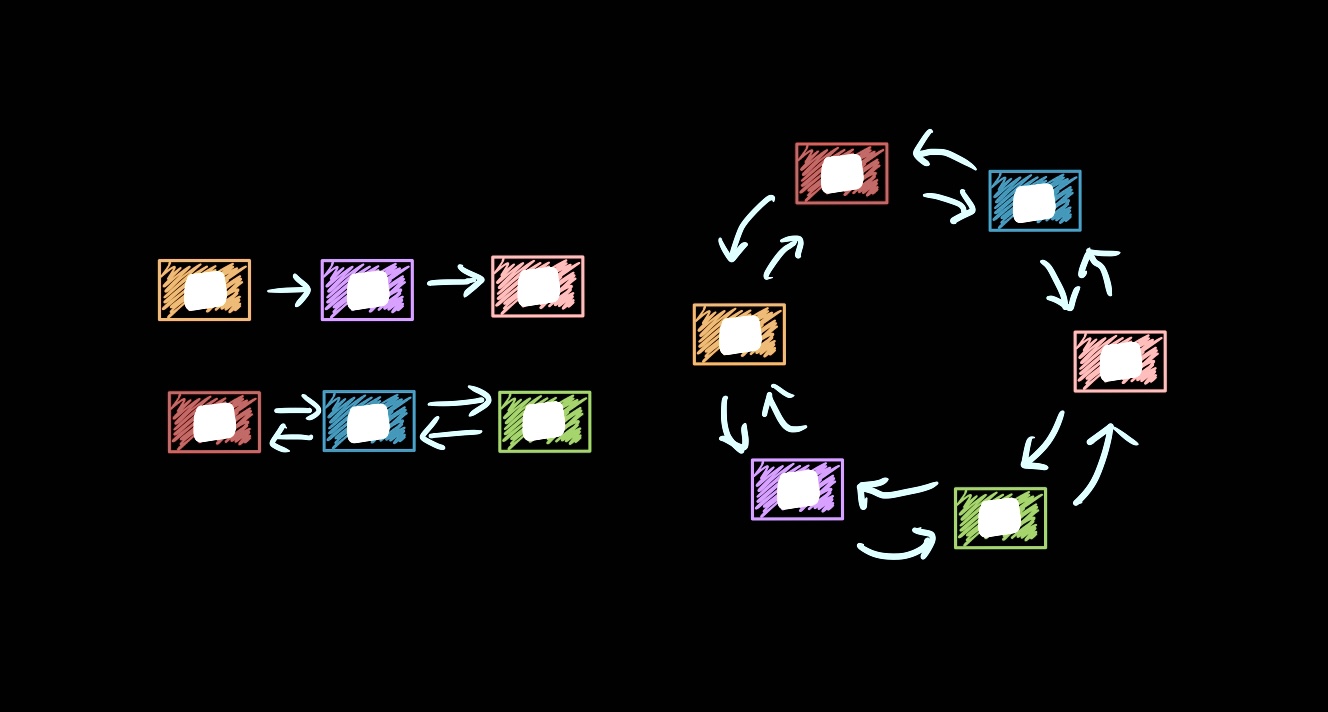
일반적으로 자료구조 공부를 하게되면 리스트는 흔히 포인터를 이용한 linked list로 구현하게 된다.
여기서 또 분류가 되는데, next포인터 뿐 아니라 prev 포인터를 추가해 양방향 순회가 가능한 double linked list가 있다.
또 tail노드를 head노드를 가리키게 해서 순환 형식을 가지는 circular linked list가 있고, 양방향으로 구현한 것이 circular double linked list이다.
Array list
리스트는 포인터가 아닌 배열을 이용해 구현한 것도 있다. 이를 배열 리스트라고 하는데 공간이 없으면 모든 자료들을 이동시켜줘야 해서 시간이 다소 걸리게 된다.
하지만 링크드 리스트와 배열 리스트 중 어떤것이 더 효율적인가에 대한 논란이 있으며, 실제로는 배열로 구현된 링크드 리스트를 더 활용하는 경우가 많다. C++의 벡터 자료구조가 일종의 배열 리스트라고 보면 된다.
