
Mission
파이썬은 다양한 라이브러리를 제공하여 웹 상의 html 파일안에 우리가 필요한 데이터를 빼내어 저장할 수 있는 기능을 제공합니다. 이를 크롤링이라 하는데요. 이번 과제를 하면서 웹크롤링은 무엇인지, 파이썬으로 어떻게 웹 크롤링을 할 수 있는지 알아보도록 하겠습니다.
API (application programming interface)
프로그램과 프로그램 사이를 잇는 매개체 (연결 통로)
GUI 예시로 스마트폰 홈버튼 -> 버튼만 눌리면 안에서 뭔일이 일어나는 지 몰라도 홈으로 가짐
네이버에서 맵기능 API를 제공한다.
-> API(통로)를 통해 네이버의 맵 기능을 여러 사람이 사용할 수 있게 프로그래밍하여 제공한다.
파이썬 requests 모듈
HTTP 웹 사이트에 요청하기 위해 만들어진 HTTP 라이브러리. 웹 개발이나 API 통신과 관련된 프로젝트에서 필수적으로 사용되는 모듈
클라이언트와 서버에 요청할 때 다양한 방식이 있다.
GET: 서버의 데이터를 읽어온다.- 성공(200), Not found(404), Bad request(400) 응답코드를 리턴
POST : 서버에 새로운 내용을 추가한다.
PUT : 서버의 데이터를 수정한다.
DELETE : 서버의 데이터를 삭제한다.
import requests
url = "https://www.naver.com"
response = requests.get(url)
print("status code:", response.status_code)등과 같이 서버에 여러가지 요청을 할 수 있다.
파이썬 BS4 모듈 (BeautifulSoup)
HTML 문서에서 원하는 정보를 분류(파싱) 해주는 파이썬 라이브러리
- 기능
- HTML 파싱 - HTML을 구성하고 있는 요소 및 태그 그리고 속성을 이해하고 트리 구조로 변환하여 데이터를 추출
- 데이터 추출 - 특정 태그의 내용이나, 속성, 텍스트 등을 선택하여 데이터 추출
- 문서 탐색 - 태그 이름, 클래스, ID 등을 기반으로 웹 문서를 탐색하고 필요한 정보를 찾는다.
- 웹 스크래핑 - 페이지의 특정 부분이나 전체 내용을 스크래핑하여 데이터를 수집
from bs4 import BeautifulSoup
import requests
# 웹 페이지 가져오기
url = 'https://example.com'
response = requests.get(url)
html = response.text
# BeautifulSoup 객체 생성
soup = BeautifulSoup(html, 'html.parser')
# 특정 태그에서 데이터 추출
title = soup.title.text
print("웹 페이지 제목:", title)
# 클래스 이름을 기반으로 요소 선택
articles = soup.find_all('div', class_='article')
for article in articles:
print(article.text)웹 크롤링
어떤 URL에서 원하는 데이터를 찾아서 분류하고 DB에 저장하는 것
requests와 BS4를 이용하여 nba 순위를 크롤링해보자
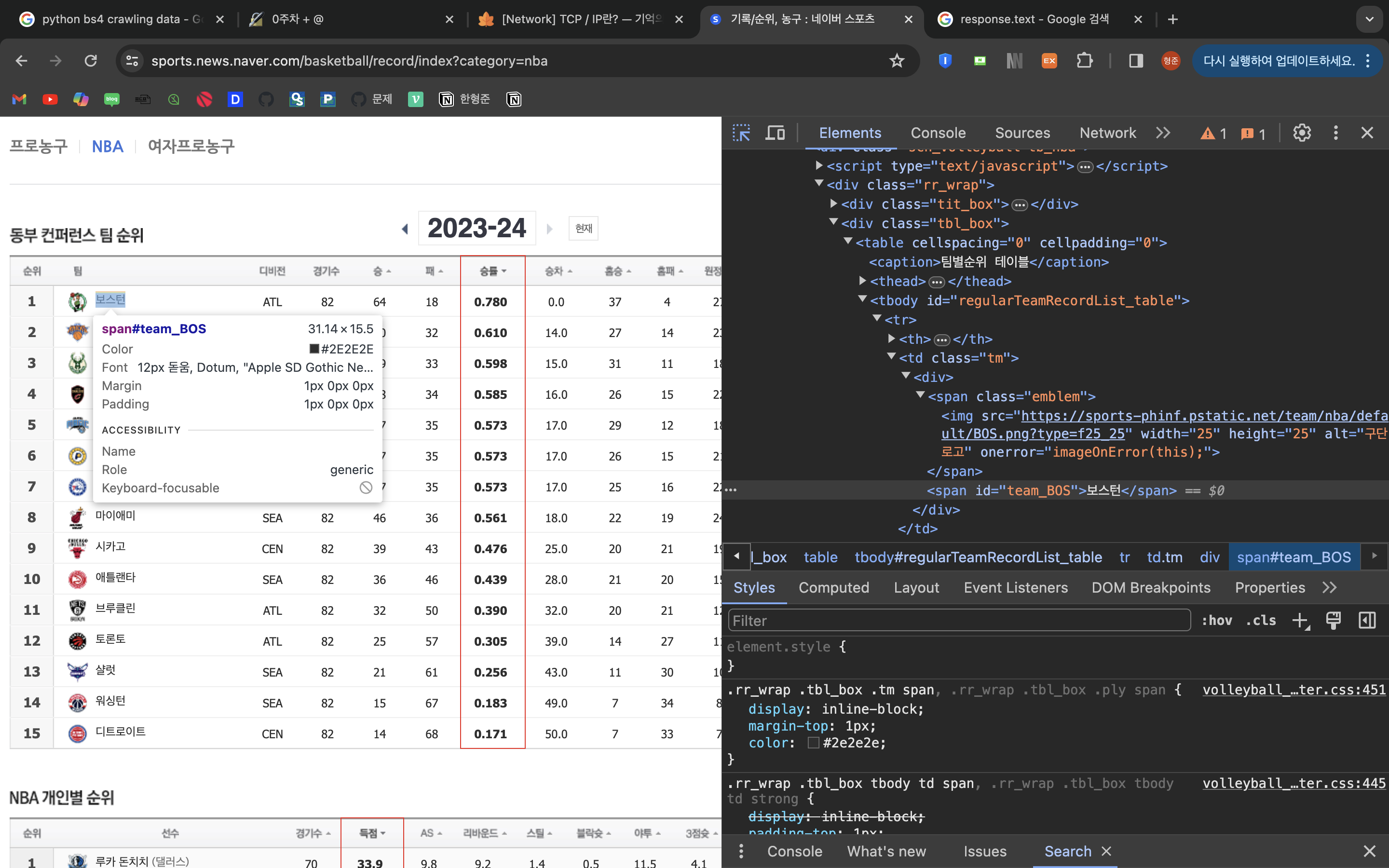
여기서 팀 이름만 크롤링하여 번호를 매겨 파이썬으로 출력하고 싶다.
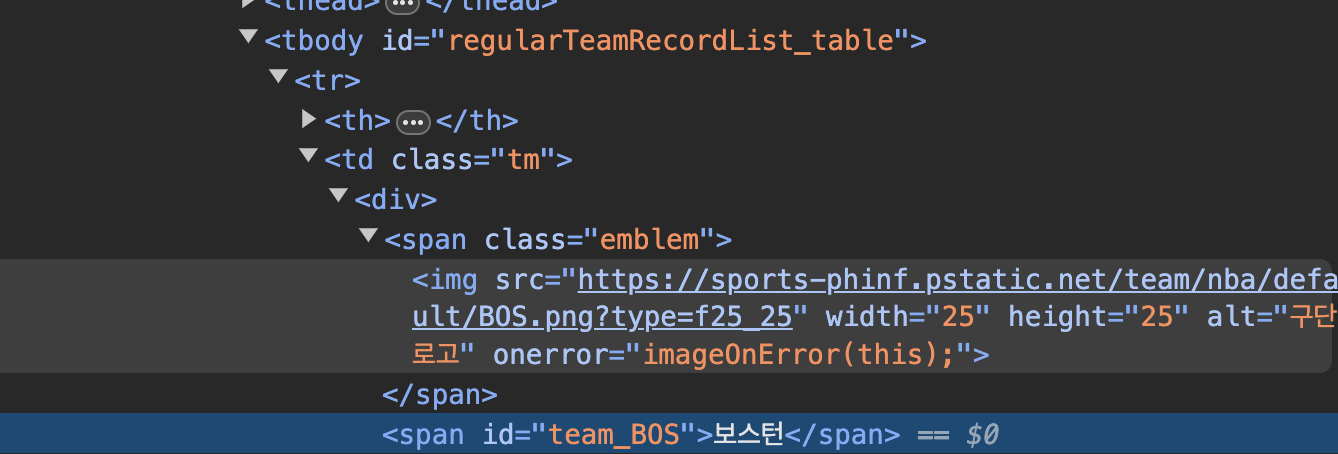
<td태그> 안에 <div태그> 안에 id가 있는 <span태그>에 내가 원하는 팀이름이 있다.
-> lankings = soup.select("td>div>span[id]")로 크롤링한다.
<td태그> 안에 <strong태그>에 내가 원하는 승률이 있다.
-> winningOdds = soup.select("td>strong")로 크롤링해온다.
import requests
from bs4 import BeautifulSoup
url = "https://sports.news.naver.com/basketball/record/index?category=nba"
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
lankings = soup.select("td>div>span[id]")
winningOdds = soup.select("td>strong")
for i in range(15):
print(f"{i+1} : {lankings[i].text}\t승률: {winningOdds[i].text}")
여기서 lankings[0]를 print해보면 <span id="team_BOS">보스턴</span>가 출력된다.
여기서 .text를 붙이면 태그 안의 item만 빼낼 수 있다.결과
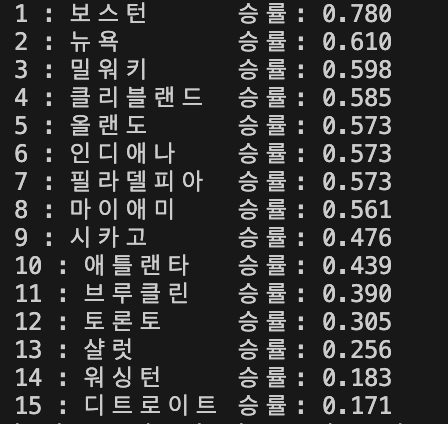
실시간 nba 리그의 순위와 각 팀의 승률을 크롤링을 완료하였다.
참조: https://mooonstar.tistory.com/entry/PythonBeautifulSoupbs4를-사용하여-웹-스크래핑하기
https://me2nuk.com/Python-requests-module-example/
크롤링 참조
https://pythonblog.co.kr/coding/11/
