
본 블로그 글의 내용을 '테디노트'님 채널에서도 만나보실 수 있습니다. 아래 썸네일을 클릭하세요!

RAG의 평가가 필요해
RAG를 깊게 파고들다보면 분명히 '어떻게 성능을 올리지?'와 같은 질문에 마주한다. 세상에 RAG 모듈과 방법론은 넘쳐나는데, 뭐가 더 좋은지 안 좋은지는 실험해보기 전까지 모른다. 그렇다면 여러분은 이 '실험'을 어떻게 하고 있는가?

많은 사람들은 마치 중세 연금술사처럼 실험을 한다. 보통 이런식이다.
내가 A라는 모듈을 새로 적용해 보았어. 이제 적용 해봤으니 질문을 몇 가지 해봐야겠다.
(생각나는 질문 몇 가지를 물어봄....) 음... 답변이 조금 별로인 것 같은데? 다른 방법이 없나?
혹시, 이 글을 읽고 있는 독자분도 이런 식으로 RAG를 평가하는가? 그렇다면 이것은 반드시 바꾸어야 한다. 정성적인 평가에만 의존하며 명확한 기준 없이 개발을 한다면, 성능 좋은 RAG가 도대체 무엇인지도 정의를 못하면서 성능을 높이려는 것이다.
RAG 역시 여타 다른 인공지능 관련 프로젝트와 마찬가지로, 정량적인 지표와 평가 데이터셋을 통한 체계적인 실험이 필요하다.
이런 체계적인 실험을 도와주고 자동화해주는 툴이 바로 AutoRAG이다. 이번 글에서는 AutoRAG 사용의 사실상 가장 중요한 부분인 평가 데이터셋을 만드는 방법에 대해 이야기해본다.
전언하자면, 이 포스트에서 실제 코드를 다루지는 않을 것이다. 하지만, RAG 평가 데이터셋의 구조와 그것을 잘 만드는 방법에 대해 잘 알게 될 것이다.
RAG 평가 구조
무엇을 평가하는가?
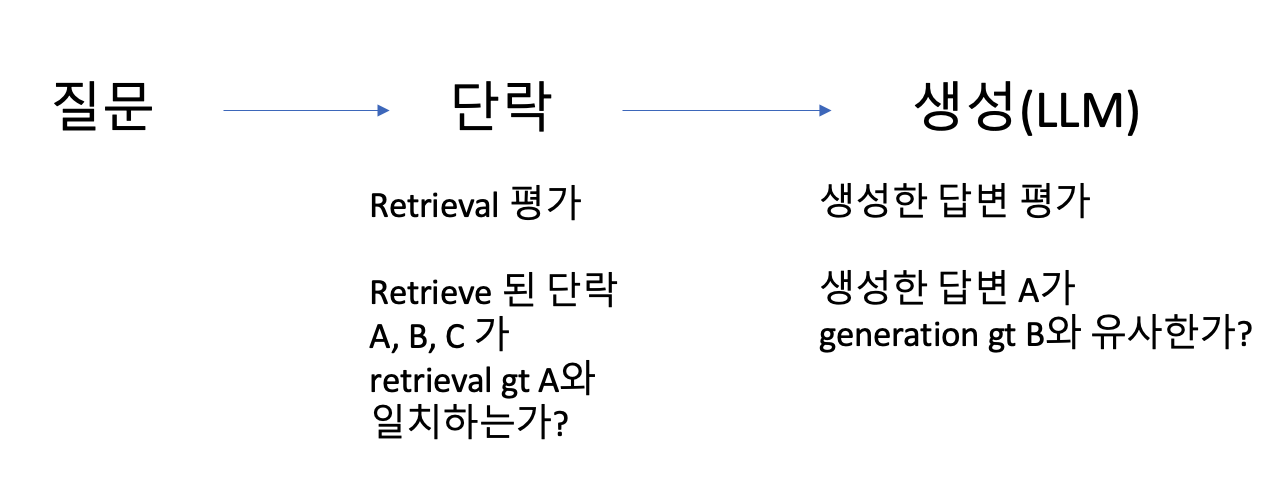
RAG를 다시 살펴보면 다음과 같다. 유저가 질문을 한다. Retrieval에서 적절한 단락을 retrieve한다. 해당 단락을 유저의 질문과 합쳐 하나의 프롬프트로 만든다. LLM에게 답변을 생성하도록 한다.
여기서 평가할 부분은 크게 두 가지다.
1. 적절한 단락이 retrieve 되었는가?
2. LLM의 답변이 적절한가?
기본적으로 이 두 가지를 평가하는 것이 곧 RAG의 평가다. 첫 번째는 retrieval 평가, 두 번째는 generation (생성) 평가이다.
어떻게 평가하는가?
retrieval 평가에는 무엇이 필요할까? 적절한 단락이 retrieve 되어있는지 알기 위해서는, 당연히 무엇이 적절한 단락인가를 알면 된다. 이것이 바로 retrieval gt이다.
그렇다면 generation 평가에서는? 답변이 적절한가를 알기 위해서는, 무엇이 적절한 답변인가를 알면 된다. 이것이 generation gt이다.

위의 예시를 보자. 유저의 질문은 "OpenAI CEO는 다음 GPT에 대해 어떻게 생각하나요?"이다.
이 질문에 대해서 뒷받침이 될 수 있는 단락이 두 개가 있다. "샘 알트먼은 gpt-5가 gpt-4보다 똑똑할 것이라 했다."라는 단락과, "샘 알트먼은 OpenAI CEO이다"라는 단락이다. 이 두 단락이 모두 있어야 질문에 제대로 답할 수 있을 것이다. 즉, 이 예시에서 retrieval gt가 이 두가지 단락이다.
또한, 모범 답안은 다음과 같을 것이다. "OpenAI CEO인 샘 알트먼은 다음 gpt (gpt-5)가 gpt-4보다 똑똑할 것이라 생각한다." 이것이 바로 generation gt가 된다.
그래서, RAG 평가 데이터셋은 기본적으로 세 가지. 질문 - retrieval gt - generation gt 쌍이 여러개 준비되어 있어야 한다. 물론, retrieval gt와 generation gt가 없이 평가할 수 있는 메트릭도 있으나, 그러한 지표들은 정확도 면에서 gt가 있을 때보다 떨어지고, 그 평가 비용도 훨씬 비싸다. 이것에 대해서는 다른 글이나 영상에서 다뤄보겠다.
결론적으로, 질문 - retrieval gt - generation gt 쌍을 100여개 정도 준비하면, AutoRAG를 구동하여 RAG를 평가 및 최적화하는 준비가 끝났다고 보면 된다!
그런데... 어떻게 이것을 만들까?
RAG 평가 데이터셋 만드는 법
요약하자면 다음과 같은 순서로 RAG 평가 데이터셋을 만들 수 있다.
- 원본 문서를 파싱하고 청킹하여 단락들을 만든다.
- 단락들 중 랜덤으로 retrieval gt를 선택한다.
- 선택된 단락을 기반으로 질문을 생성한다.
- 단락과 질문을 통해 모범 답안 (generation gt)를 생성한다.
- 결과물을 검토하여 품질을 높인다.
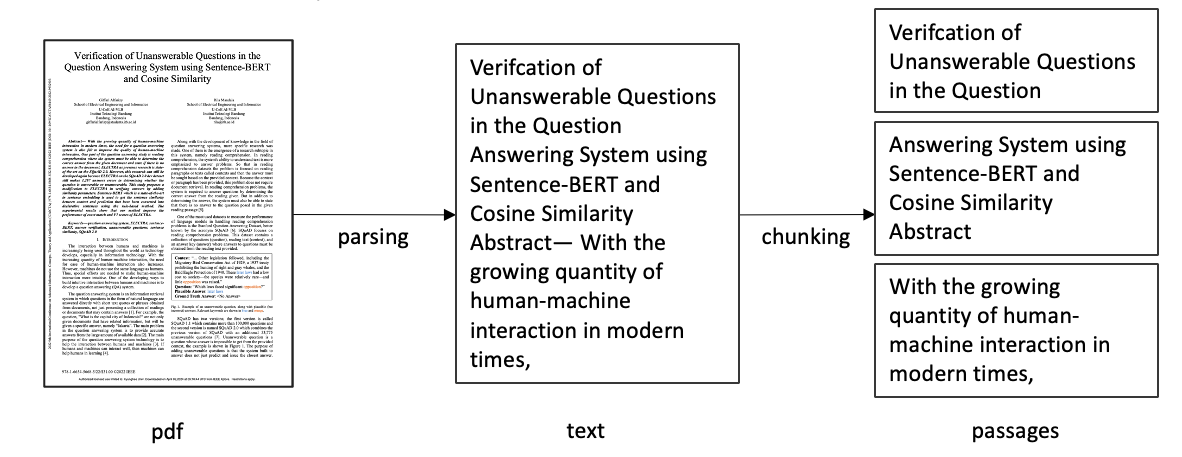
일단, 단락부터 만들어야 한다. 그러러면 원본 문서를 파싱하여 글로 변환하고, 그것을 청킹하여 짧은 단락들로 만든다.
물론, 어떤 파싱 방법을 사용할 것인지, 그리고 어떤 방식으로 청킹할 것인지 역시 큰 고민이다. 아직은 AutoRAG에서 파서와 청킹 방법 최적화는 지원하지 않지만, 추후 지원을 위한 연구를 진행하고 있다.
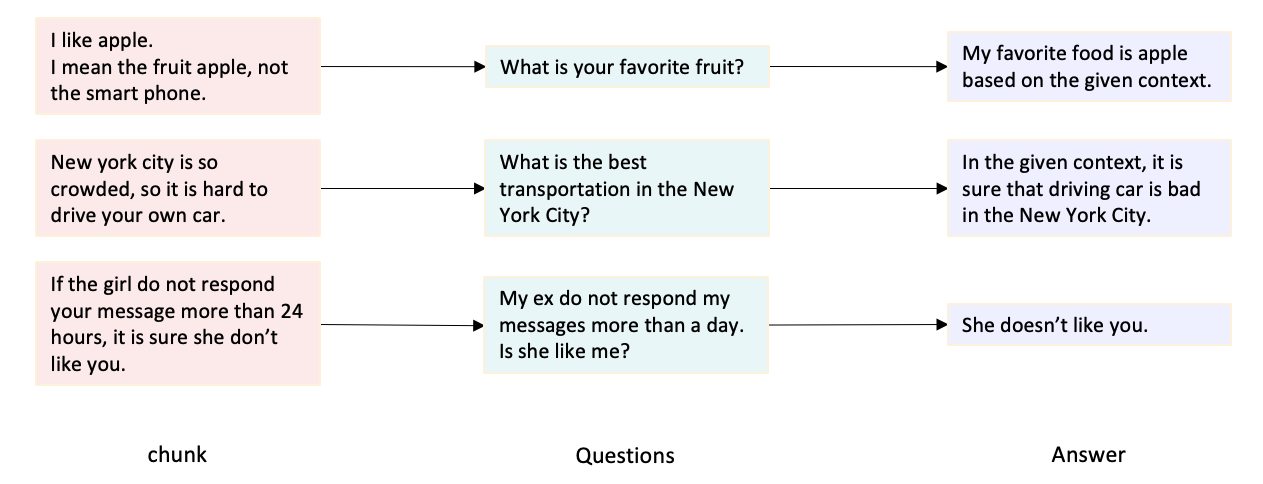
이제 각 단락에서 질문을 만들 수 있다. 이 때, 질문은 반드시 '단락'에 기반한 질문이어야 한다. 이렇게 하면, 처음 선택한 그 단락이 곧 retrieval gt가 된다.
질문을 먼저 만들고 retrieval gt를 찾기 위해서는, 모든 단락들을 검토해야 하기 때문에, 이러한 방법으로 retrieval gt - 질문 쌍을 만드는 것을 추천한다.
이제 마지막으로, 질문과 단락을 LLM 등에 보여주고 모범 답안을 생성하게 하면 된다. 이 때는, gpt-4와 같은 높은 성능의 LLM을 통해 좋은 답변을 생성하도록 하자. 또한, 모범 답안이 많으면 많을수록 더 정확한 평가를 진행할 수 있다.
검증은 필수야
직접 위와 같은 과정을 통해 RAG 평가 데이터셋을 받아들면, 이러한 생각을 할 것이 분명하다.
뭐지 이 이상한 질문은?
세상에 누가 이런 질문을 물어봐?
아무리 똑똑한 LLM도, 아직 현실적인 질문을 만드는 능력이 떨어진다. 그렇기 때문에, 좋은 RAG 평가 데이터셋을 만들기 위해서는 사람의 개입이 필수적이다.
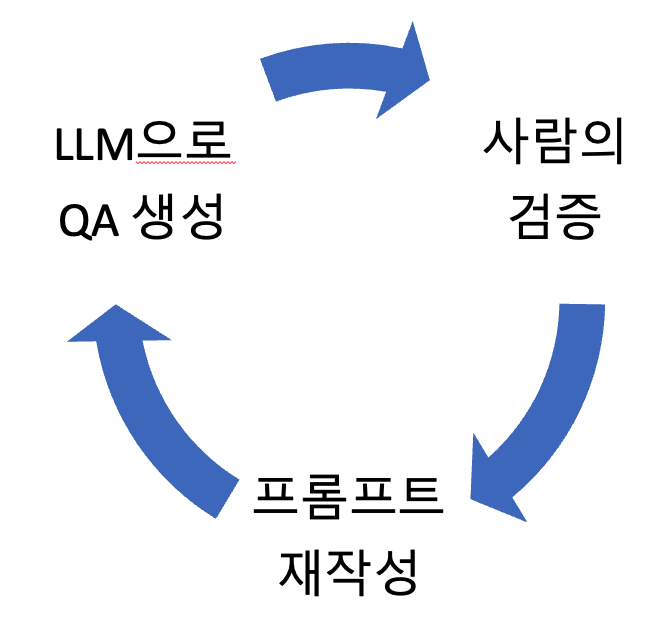
위처럼 LLM과 사람이 합심해서 RAG 평가 데이터셋을 만드는 것이 바람직하다. 어떤 질문 유형이 현실적이고, 어떤 것이 현실적이지 않은지 직접 파악해보고, 그러한 특성을 파악해서 질문 생성 프롬프트를 재작성하는 것이다.
개선한 프롬프트로 다시 질문을 생성하고, 그것을 다시 평가하고, 부족한 부분을 채우는 프롬프트를 다시 작성하는 방식을 반복하다 보면, 좋은 품질의 RAG 평가 데이터셋을 확보할 수 있을 것이다.
이 과정은 빠르게 끝나는 것이 아닌, 데이터셋을 만드는 과정에서 사람의 노력이 필요하다. 매우 지루하고 힘든 과정일 수 있지만, 실제 유저들의 특징을 반영하는 좋은 평가 데이터셋을 만드는 것이 RAG 성능 향상의 과정 중 가장 중요한 과정임을 기억하자.
평가 데이터셋 생성 후에 나머지 부분은 AutoRAG에게 맡기면 된다. 전체 시간중 90% 이상을 평가 데이터셋 구성에 투자하는 것을 강력하게 추천한다.
더 읽어보기
- AutoRAG => https://github.com/Marker-Inc-Korea/AutoRAG
- AutoRAG data creation => https://docs.auto-rag.com/data_creation/tutorial.html
- AutoRAG dataset format => https://docs.auto-rag.com/data_creation/data_format.html
