LLM의 답변을 평가하기 위해 자주 사용하는 방법은 LLM에게 평가를 맡기는 것이다.
LLM으로 답변을 평가를 하는 메트릭도 여러가지가 있는데, AutoRAG에는 마이크로소프트의 G-eval이 있다.
다음과 같은 G-eval Consistency점수를 얻었다고 해보자.
- A: 4.123
- B: 4.098
그런데 갑자기 의문이 든다.

🤔: 다시 돌리면 점수 달라지는 거 아냐?
🤨: 다시 돌리면 B가 이기는 거 아냐?
맞는 말이다. 다시 돌리면 B가 이길 수도 있다.
1~5점 스케일인 G-eval에서 4점이던 점수가 갑자기 1점이 되지는 않겠지만, 0.1점 정도는 충분히 달라질 수 있는 것이다.
그렇다면 G-eval의 오차 범위는 어느정도일까??
어느 정도 차이가 나야 A가 진짜로 더 좋은 답변을 했다고 믿을 수 있을까??
이를 알아보고자 직접 실험을 해봤다.
실험 계획
팀에서는 정답을 말했는 지를 평가하는 G-eval의 Consistency를 자주 사용하기 때문에, Consistency를 가지고 실험해보기로 한다.
같은 QA 데이터셋을 50번 돌려보고 G-eval Consistency 점수 분포를 확인해보기로 한다.
실험 결과
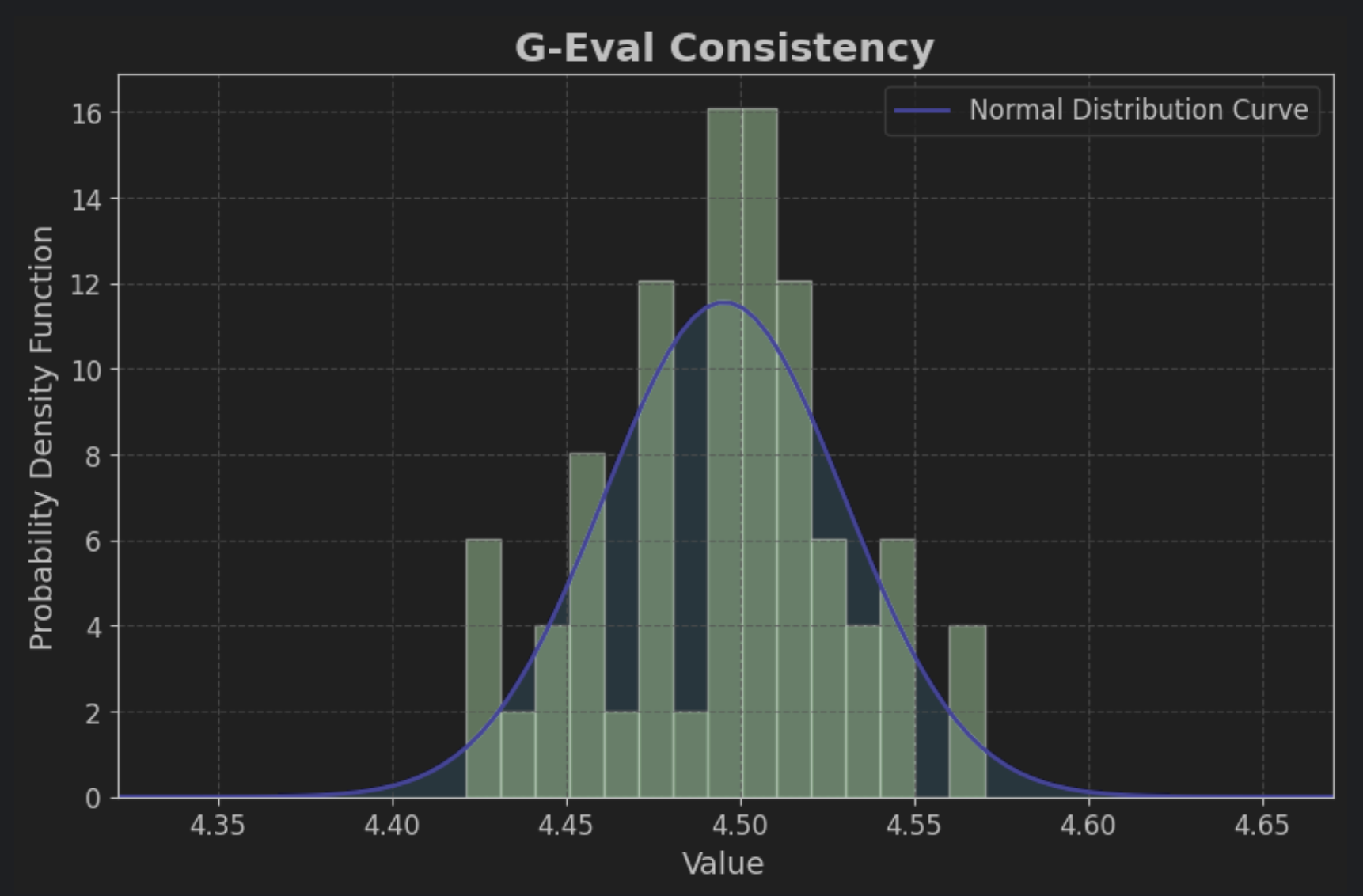
90% 신뢰구간: 4.4872 ~ 4.503795% 신뢰구간: 4.4855 ~ 4.505399% 신뢰구간: 4.4822 ~ 4.5086
다음과 같은 신뢰구간을 얻을 수 있었다.
50개의 표본으로만 진행한 실험이라, 최솟값과 최댓값도 함께 공유한다
(gpt-4를 사용해 너무 비싸 50개만으로 진행하였다)
최솟값: 4.4211최댓값: 4.5702
(모든 결과 값은 소수점 넷째자리에서 반올림 하였다.)
더 읽어보기

RAG AutoML tool - AutoRAG