(24년 12월 추가)
글 내용과 관련해 강의를 런칭하였습니다. 더 많은 정보가 필요하신 분들은 참고해주세요!!
▪ 쿠폰코드: PRDTEA241202_auto
▪ 할인액: 4만원 (~25/1/5 까지 사용가능)
▪ 강의링크: https://bit.ly/3BayH1F
RAG에서 굉장히 높은 성능 향상을 가져다주는 모듈 중 하나는 바로 리랭커이다.
이 리랭커의 4가지 종류에 대해 총정리해 보겠다.
1. LM 기반 리랭커
가장 흔히 볼 수 있는 리랭커 종류로, LM (Language Model)을 기반으로 제작한다.
리랭커 모델을 제작하는 방법은 다음과 같다.
- 질문 - 단락 쌍의 데이터셋을 준비한다.
- 관련있는 질문 - 단락 쌍은 1로, 아닌것은 0으로 라벨링한다.
- LM을 질문 - 단락 쌍을 입력받아 1 혹은 0으로 분류하도록 파인튜닝한다.
- 파인튜닝이 완료된 LM을 리랭커 모델로서 활용할 수 있다.
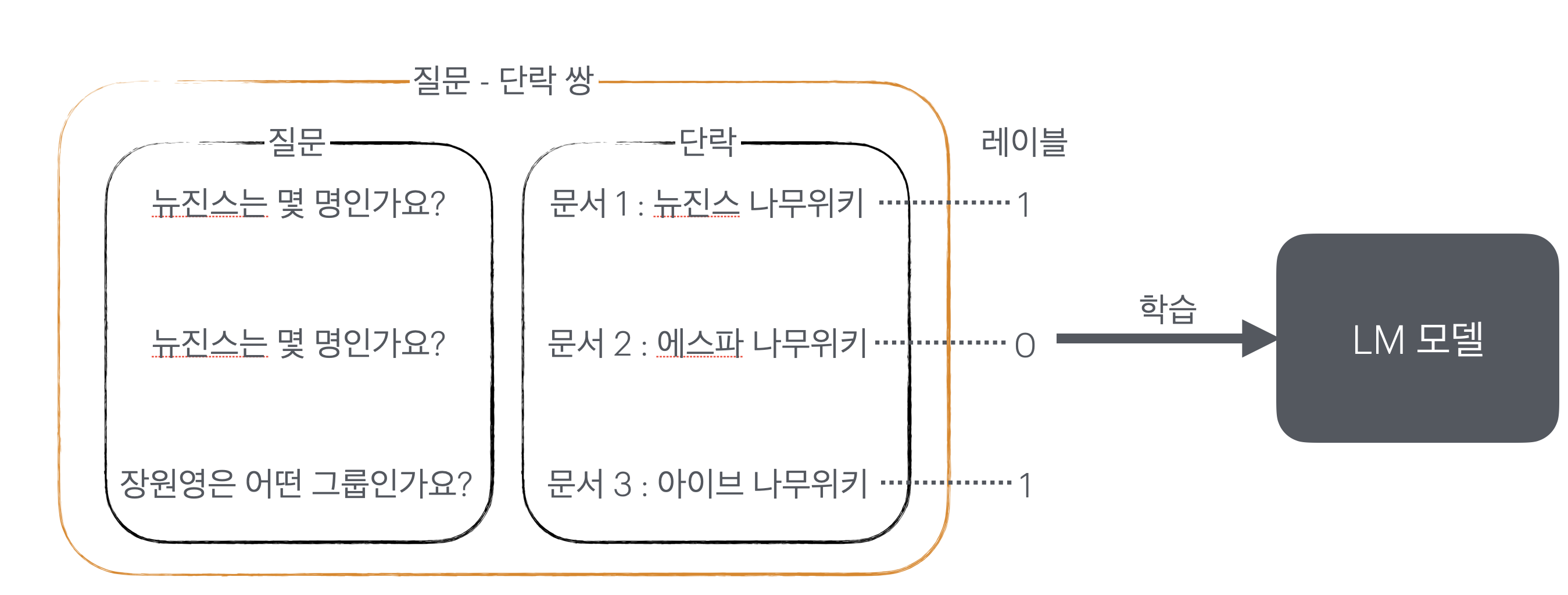
이렇게 튜닝된 LM은 바로 리랭커로서 작동할 수 있다.
질문과 함께 retrieve된 단락을 넣으면, 그 단락이 관련성이 있을지 없을지에 대한 확률을 output으로 내뱉게 되는 것이다. (이는 LM이 1이라고 분류할 확률과 동일하다)
LM 기반의 리랭커는 가장 흔한 방법이므로, 많은 모델들을 찾을 수 있다. AutoRAG에서도 이 방법을 여러 모듈들을 찾을 수 있다. MonoT5, Sentence Transformer Reranker, Flag Reranker, Flag LLM Reranker, TART가 그것이다.
이 중에서 두 가지를 간단히 살펴보자. 먼저 Flag LLM Reranker는 LLM으로 분류되는 구글의 Gemma-2b 모델을 리랭커 용도로 파인튜닝 한 것이다. T5나 BERT와 같은 작은 모델을 사용하는 다른 리랭커와 다르게 2b 모델을 사용하기 떄문에, 많은 사례에서 높은 성능을 보여준다.
TART는 이러한 LM 기반 리랭커에 'instruction' 개념을 추가한 것이다. 질문과 단락의 관련성을 분류하는 기준, 도메인의 특성 등을 프롬프트 엔지니어링 하듯이 부여할 수 있다. 만약 domain-specific한 리랭커가 필요하다면 시도해 볼 만 하다. 더 자세한 내용은 여기를 확인하자.
TMI
좀 더 자세한 원리에 대한 추가적인 설명이므로, 이 섹션은 건너 뛰어도 괜찮다.
LM 기반 리랭커를 훈련할 때, 실제 분류기를 훈련하는 것은 아니고 분류기와 같이 행동하도록 만드는 것이다. 리랭커 모델은 어디까지나 LM (언어 모델)이고, 언어 모델의 기본 원리는 next token prediction이다. 즉, 다음 토큰에 무엇이 나올 것인지 예측하는 것이다.
리랭커는 아래와 같은 프롬프트로 훈련된다.
질문에 주어진 단락이 관련이 있다면 1, 없다면 0으로 분류하세요.
질문 : 뉴진스는 몇 명인가요?
단락 : 뉴진스 나무위키
분류 :
이러면 '분류 :' 프롬프트 뒤에 1을 생성하거나 0을 생성할 확률을 각각 구한다. 이후, 두 확률에 cross-entropy를 적용하면 최종 리랭커의 값이 된다. 이렇게 하면 '1'이라는 토큰을 생성할 확률을 '1 혹은 0 중에서 1을 생성할 확률', 즉 분류기와 동일한 역할을 하도록 만들 수 있다.
2. LLM 기반 리랭커
다음은 LLM을 리랭커로 사용하는 것이다. LLM은 여러 downstream task들에 파인튜닝 없이도 매우 높은 성능을 보여주고, 이는 단락을 재정렬하는 리랭커로서도 좋은 성능을 보여준다.
당연하겠지만, LLM을 사용하기 때문에 높은 비용은 문제가 될 수 있다.
AutoRAG의 LLM 기반 리랭커인 RankGPT의 원리를 알아보며 LLM 기반 리랭커에 대해 살펴보자.

위와 같이 LLM에 프롬프트를 입력해주고, LLM이 단락들의 랭킹을 곧바로 답변으로 생성하는 것이다.
즉, LLM에게 리랭킹을 요청 => 리랭킹 해줌.
이것이 끝이다! 매우 간단한 원리다.
3. 임베딩 기반 리랭커
임베딩 모델 기반의 리랭커는, 질문과 단락을 임베딩 벡터로 생성한 후 유사도가 높은 벡터를 더 높은 순위로 재정렬하는 것이다.
흔히 벡터DB와 함께 사용하는 retrieval과 동일한 원리를 가지고 있으며, 단지 리랭킹 용도로 사용한다는 것만 다르다.
임베딩 모델로는 retrieval 단계에서 사용하는 것과 다른 임베딩 모델을 사용하기 때문에, 벡터DB와 임베딩 기반 리랭커의 조합은 마치 모델 결과를 ensemble하는 것과 같이 성능을 올려줄 수 있는 가능성이 있다.
AutoRAG에서는 임베딩 기반 리랭커 중 Colbert 리랭커를 지원한다.
4. Log-prob 기반 리랭커
LLM은 next token prediction, 즉 다음 토큰을 예측하는 모델인 것은 알고 있을 것이다. 이 특성을 이용한 것이 Log-prob 기반 리랭커이다.
AutoRAG에서는 Log-prob 기반 리랭커로 UPR 리랭커가 있다. UPR 리랭커에 대해서는 여기서 더 자세히 알아볼 수 있다.
원리

위와 같이 리랭커 모델에 입력하면 언어 모델은 질문을 생성할 것이다. 이 때, 실제 유저의 질문 토큰이 나올 확률을 모두 계산할 수 있다. 그렇기에, 최종적으로 주어진 단락에서 유저의 질문이 생성될 확률을 구할 수 있다.
당연하게도 질문과 관련 있는 단락을 보고서 그 질문을 생성할 확률이 높을 것이다. 예를 들어보자.
예시
단락 내용이 아래와 같다.
도쿄는 철도 중심으로 설계된 도시이며, 수많은 노선과 사철들이 존재한다. 대표적인 철도 회사로 공기업인 JR 동일본을 비롯해 한큐, 도에이, 도쿄 메트로, 게이세이 등이 있다.
그렇다면 이 단락을 보고 도쿄의 대표적인 철도 회사는 뭐가 있나요?라는 질문을 생성할 확률은 높을 것이다. 왜냐면 서로 깊은 관계를 보이기 때문이다.
반면, 뉴진스 막내는 누구인가요?라는 질문을 생성할 확률은 극히 낮을 것이다. 왜냐면 서로 아무 관련이 없기 때문이다.
그래서 뭐가 제일 좋은 리랭커죠?
어떤 리랭커가 가장 좋은 지는 경우에 따라 다르다. 그래서 반드시 RAG를 만들때 수많은 리랭커들을 직접 실험해 성능을 측정하는 것이 중요하다. 특히, 서로 다른 유형의 리랭커는 큰 성능 차이를 보일 수 있다.
AutoRAG에서는 간단하게 많은 리랭커를 실험할 수 있다. 아래와 같이 설정 YAML 파일을 구성하면, 이 많은 리랭커들을 알아서 평가하고 최적의 리랭커를 도출해 낼 것이다!
- node_type: passage_reranker
strategy:
metrics: [retrieval_f1, retrieval_ndcg, retrieval_map]
speed_threshold: 10
top_k: 5
modules:
- module_type: pass_reranker
- module_type: tart
- module_type: monot5
- module_type: upr
- module_type: cohere_reranker
- module_type: rankgpt
- module_type: jina_reranker
- module_type: colbert_reranker
- module_type: sentence_transformer_reranker
- module_type: flag_embedding_reranker
- module_type: flag_embedding_llm_reranker
- module_type: time_reranker더 읽어보기
