
(24년 12월 추가)
글 내용과 관련해 강의를 런칭하였습니다. 더 많은 정보가 필요하신 분들은 참고해주세요!!
▪ 쿠폰코드: PRDTEA241202_auto
▪ 할인액: 4만원 (~25/1/5 까지 사용가능)
▪ 강의링크: https://bit.ly/3BayH1F
우리는 지난 실험에서 청킹이 RAG 답변 성능에 미치는 정도를 알아봤었다.
실험에 사용한 청킹 방법들 말고도 무수히 많은 청킹 방법들이 있고, 연구가 활발히 이루어지고 있는 덕분에 계속해서 쏟아져 나오고 있다.
뜬금없이 스포를 하나 하자면, 곧 우리 AutoRAG에서도 청킹 최적화를 지원할 계획이다 ! 정말 기쁜 일이다 !!
그래서 혼자 신난 기념으로😂 RAG에서 주로 많이 사용되는 5가지 청킹 방법을 소개하고자 한다.
1. Token
먼저, Token이다.
랭체인과 라마인덱스에서는 TokenTextSplitter 라는 이름을 사용 중이다.
from llama_index.core.node_parser import TokenTextSplitter
from langchain.text_splitter import TokenTextSplitterTextSplitter는 거의 모든 청킹 뒤에 따라붙기 때문에 편히 Token이라고만 부르도록 하겠다 :)
과정은 크게 다음과 같다.
- 토크나이저로 텍스트 → 토큰
- token_size로 자르고, overlap_size만큼 오버랩해준다.
장황한 설명보다는 직접 청크 사이즈와 오버랩 사이즈를 조절해보며 감을 잡을 수 있는 링크를 소개하려고 한다!
이렇게 사진과 함께 보면 토큰 사이즈와 오버랩의 감이 잡힐 것이다.
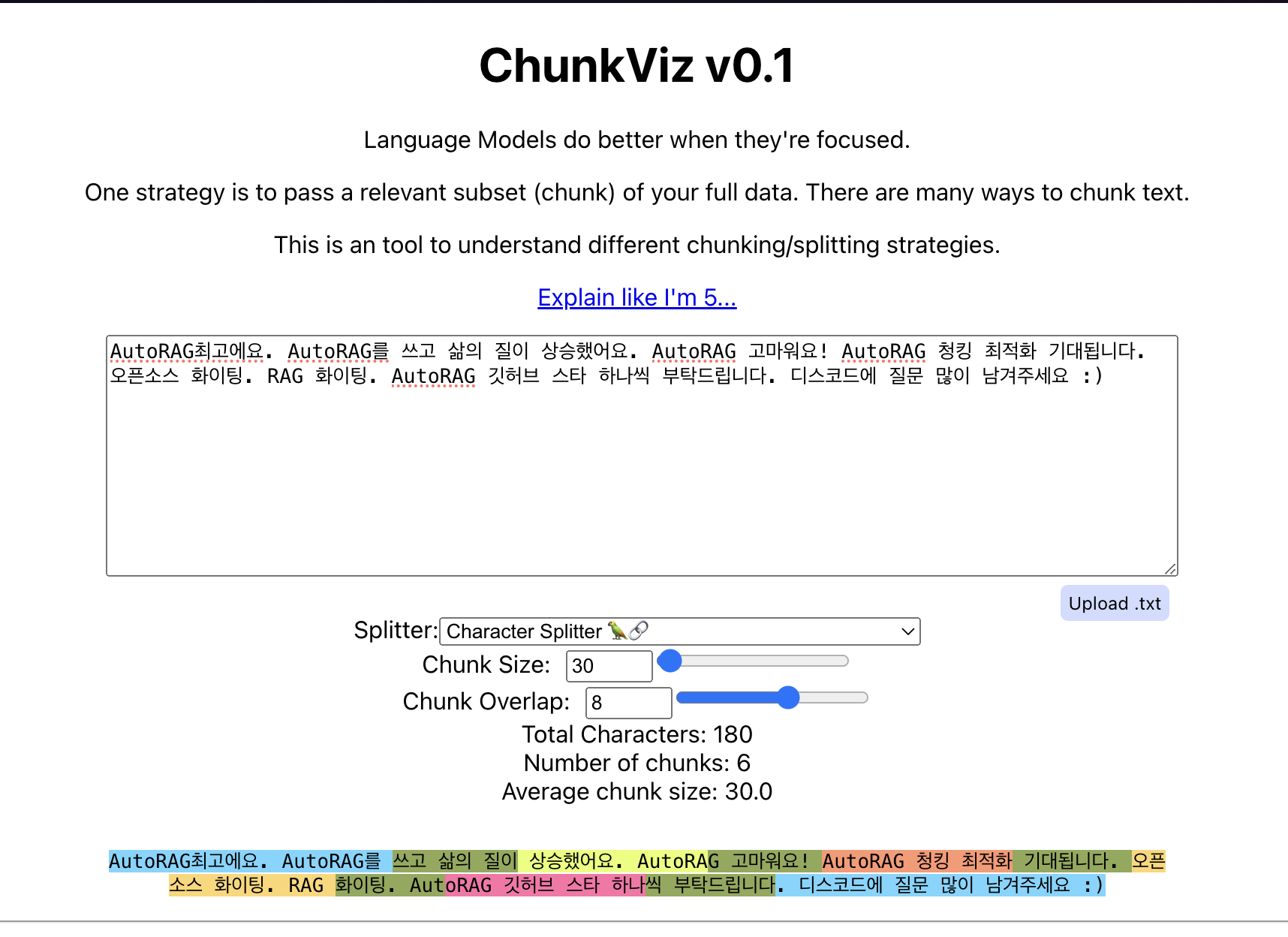
진한 초록색이 오버랩된 부분이다.
청킹 결과는 [ AutoRAG최고에요. AutoRAG를 쓰고 삶의 질이, 쓰고 삶의 질이 상승했어요. AutoRAG 고마워요! ,…] 이런 식으로 얻을 수 있는 것이다.
2. Character
다음은 Character청킹이다.
랭체인의 CharacterTextSplitter 를 통해 사용해볼 수 있다.
from langchain.text_splitter import CharacterTextSplitterAutoRAG 최고에요.\n\n AutoRAG를 쓰고 삶의 질이 상승했어요.\n\n AutoRAG 고마워요!
Character의 separator는 “\n\n”로 다음 텍스트를 청킹한다고 해보자.
[ AutoRAG 최고에요., AutoRAG를 쓰고 삶의 질이 상승했어요., AutoRAG 고마워요!]
다음과 같이 3 문장으로 청킹 될 것이다.
가장 직관적이다! 문장 단위로 잘라주는 청킹이다.
문장 분리기를 사용해서 텍스트를 문장 단위로 잘라주는 것이다!
3. Sentence
대표적으로 라마인덱스의 SentenceSplitter 가 있다.
from llama_index.core.node_parser import SentenceSplitter라마인덱스의 Default 문장 분리기는 다음과 같다.
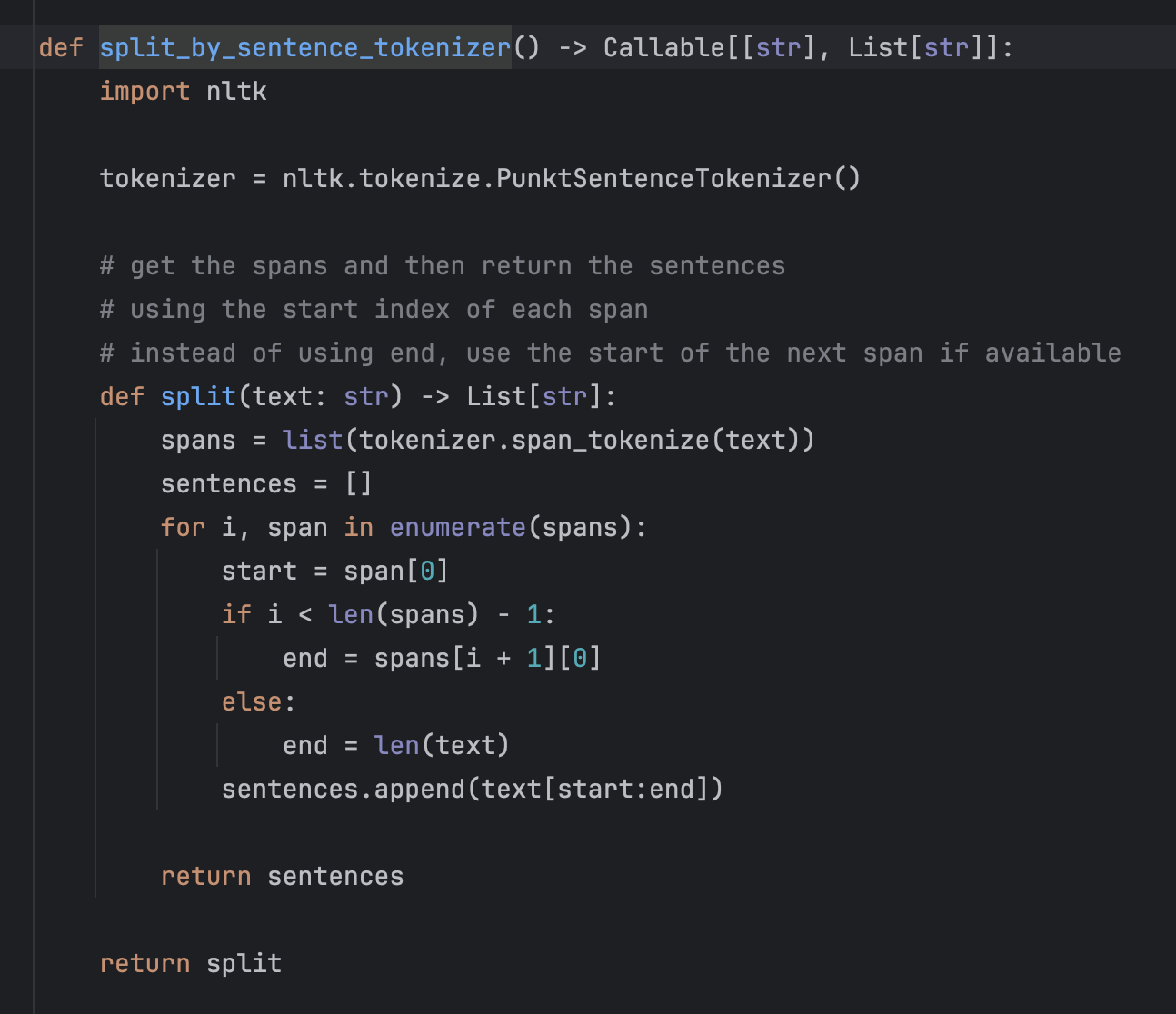
해당 문장 분리기는 시맨틱 청킹에 문장 분리기 바꿔보기에서 꽤나 자세히 다루었는데, 더 궁금한 게 있다면 다음 글을 참고하자 !
특히, 랭체인에는 한국어 문장 분리기인 konlpy가 있다!
from langchain.text_splitter import KonlpyTextSplitter4. Semantic
다음은 지난 청킹 실험에서 1등을 차지한 시맨틱 청킹이다 !
from llama_index.core.node_parser import SemanticSplitterNodeParser
from langchain_experimental.text_splitter import SemanticChunker랭체인과 라마인덱스에서 지원하는 시맨틱 청킹 모듈의 방법이 약간 다른데, 이는 따로 소개하도록 하겠다 !
이외에도 라마인덱스의 SemanticDoubleMergingSplitterNodeParser 도 있다
핵심 원리는 임베딩 모델을 사용하여 의미론적으로 비슷한 문장끼리 뭉쳐서 청킹하는 것이다.
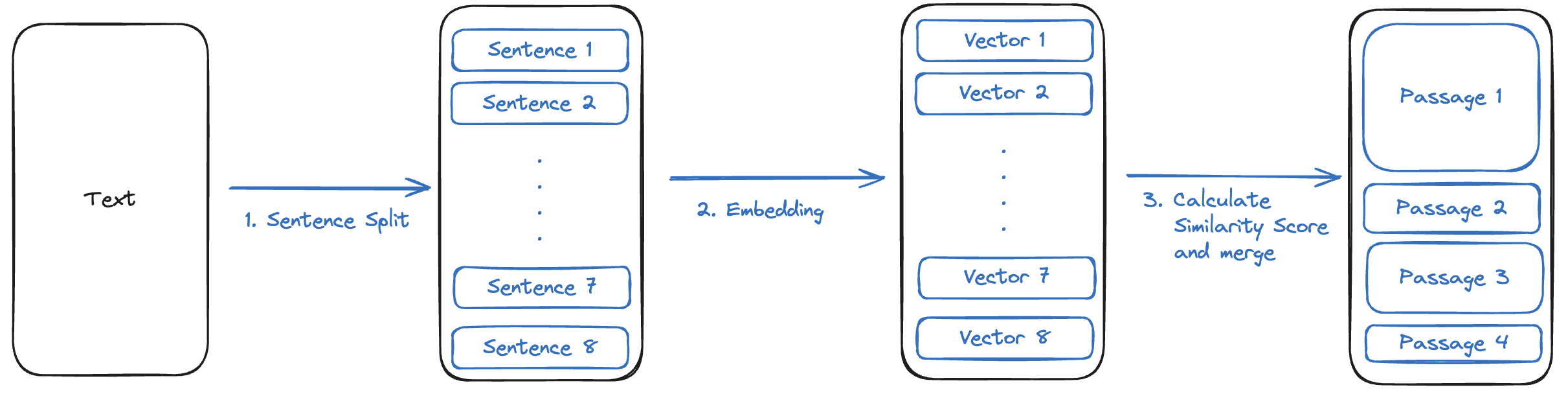
- 문장으로 자름
- 임베딩 모델로 문장 임베딩
- 문장 간의 벡터 유사도 계산
- 벡터 유사도가 Threshold를 넘긴 문장들을 합쳐서 하나의 청크로 구성
4번 단계에서 사용하는 방법에 따라 라마인덱스의 시맨틱 청킹, 시맨틱 더블 머징, 랭체인의 시맨틱 청킹이 살짝 다르다.
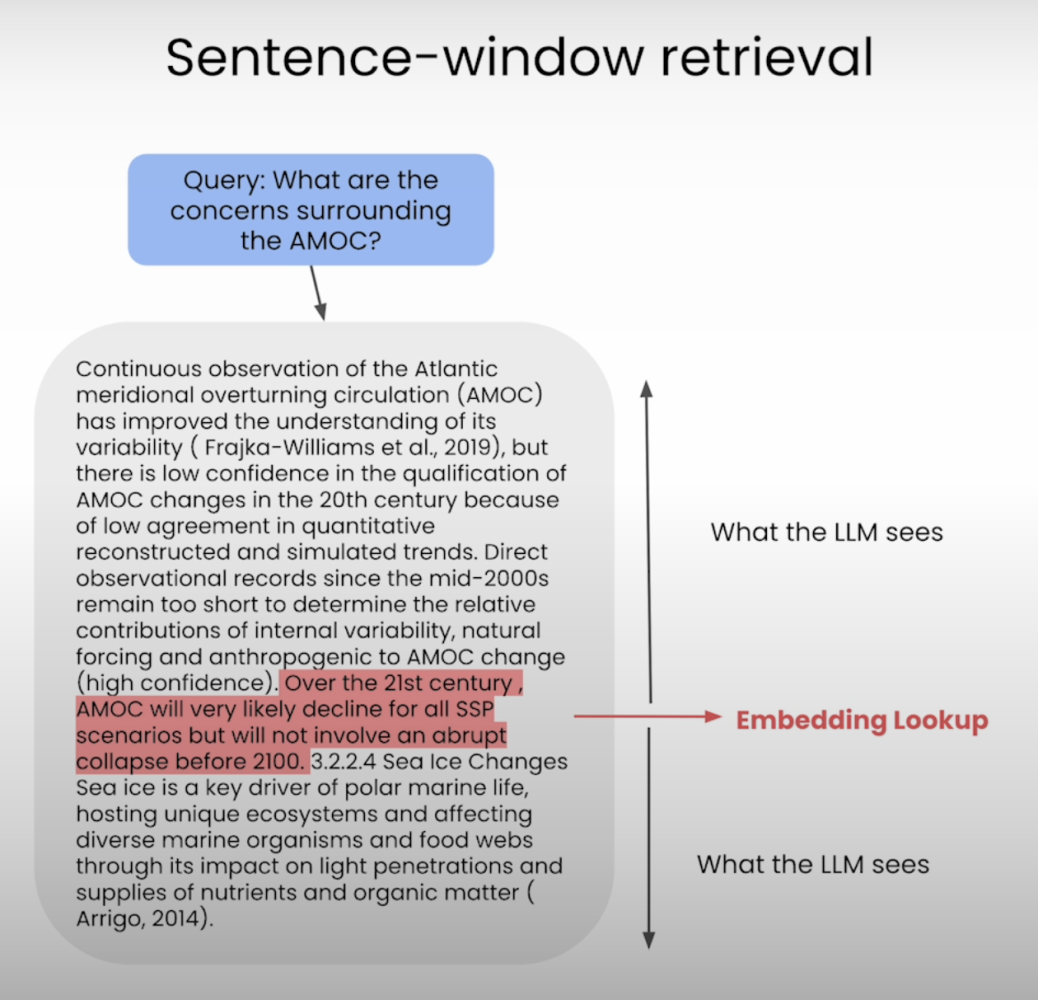
5. Window
마지막은 Sentence Window 청킹이다!
라마인덱스의 SentenceWindowNodeParser를 사용한다.
from llama_index.core.node_parser import SentenceWindowNodeParser과정은 다음과 같다.
1. 문장으로 자름
2. 정해진 윈도우 사이즈만큼 앞뒤 문장을 윈도우로 지정하여 문장의 metadata에 넣어줌
직관적인 이해를 돕는 사진을 함께 첨부한다!
⚠️ 랭체인, 라마인덱스 청킹을 사용할 때 주의해야 할 점!
잘린 문장이 chunk_size보다 작으면, 너무 잘게 잘려서 자른 문장을 다시 merge하는 기능이 있다.
따라서 다음 [ AutoRAG 최고에요., AutoRAG를 쓰고 삶의 질이 상승했어요., AutoRAG 고마워요!]처럼 문장을 잘게 자르고 싶다면, chunk_size 파라미터를 통해 충분히 chunk_size를 줄여주도록 하자!
도움이 되셨다면 AutoRAG 스타 ⭐ 부탁드립니다 :)
