 출처 : Task-aware Retrieval with Instructions에서 번역
출처 : Task-aware Retrieval with Instructions에서 번역
리랭커라면 비단 ‘질문을 보고 단락들을 재정렬'하게 되는 매커니즘을 가지고 있다.
(리랭커가 뭔지 모르겠다면 여기를 눌러 이 전 글을 보고 오자)
그런데 이 TART라는 리랭커는 뭔가 다르다. 바로 ‘instruction’이 추가로 장착되어 있는 리랭커이다. 왜 리랭커에 도대체 Instruction이 필요할까?
참고문헌
TART 리랭커는 메타에서 나온 리랭커 기법이다. Task-aware Retrieval with Instructions이라는 논문에 잘 소개가 되어 있고, 깃허브도 있다.
TART 리랭커란
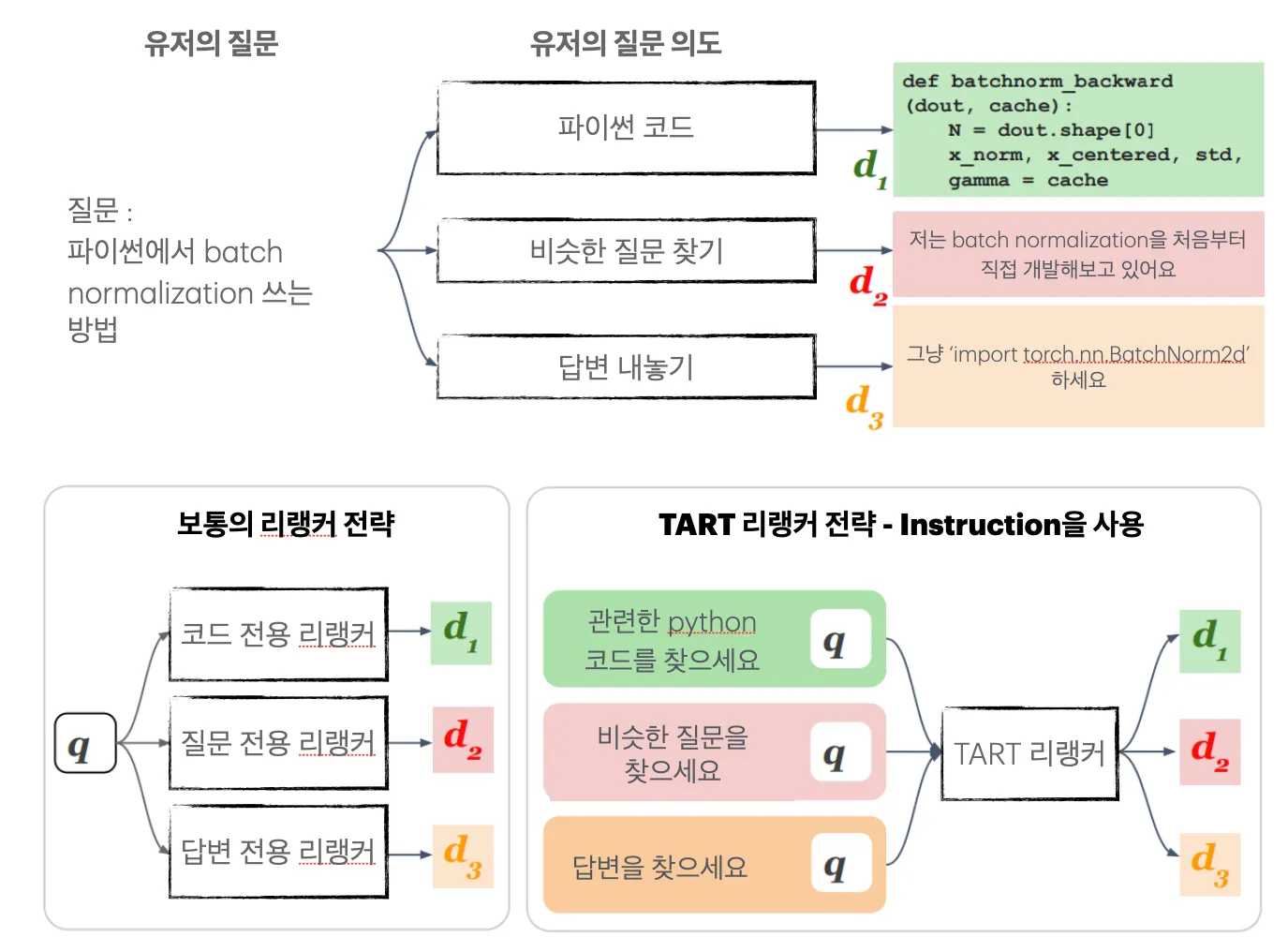
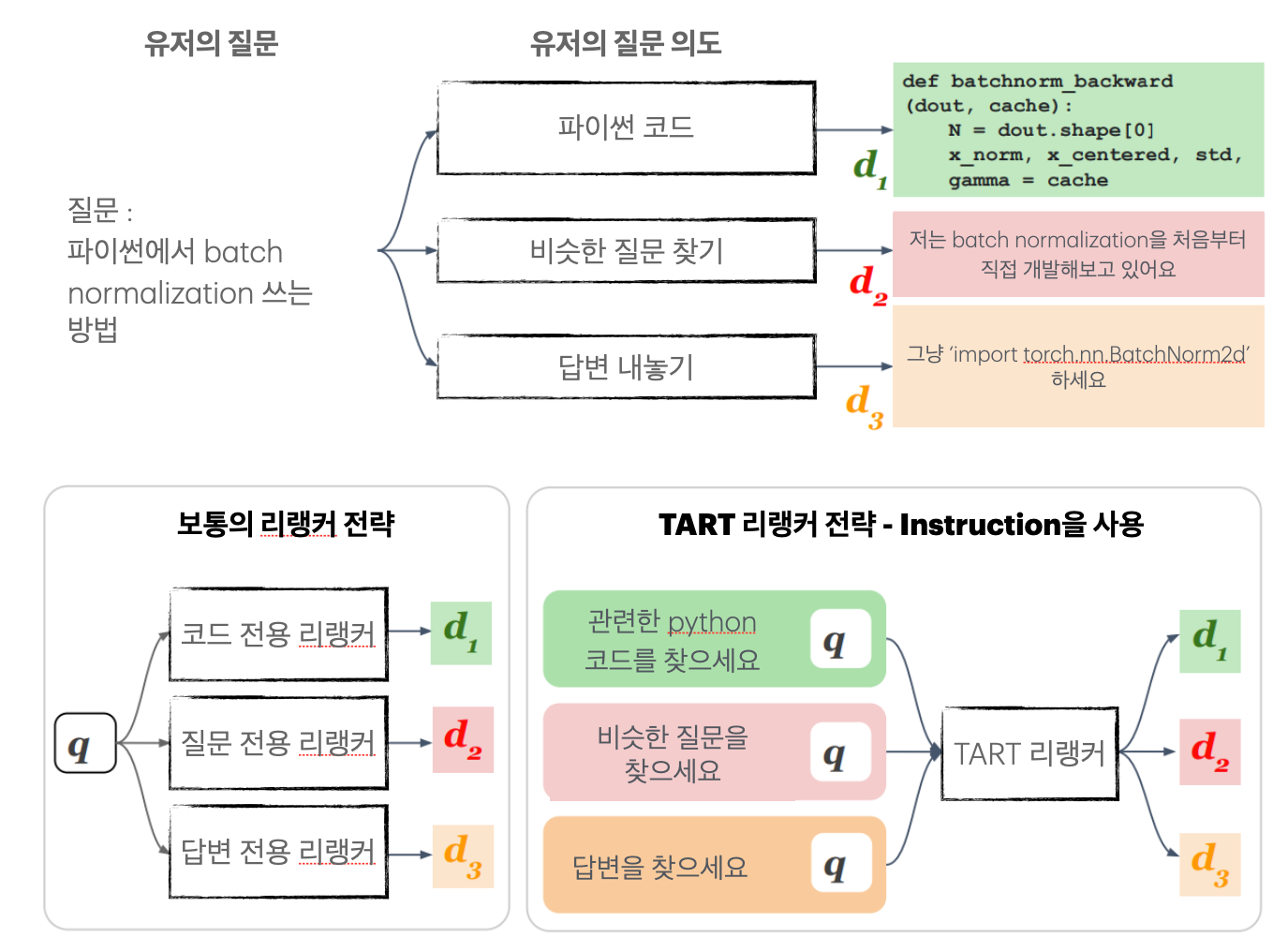
TART의 핵심은 “재정렬 시에 Instruction을 포함시킨다” 에 있다. 단순한 유저의 질문이 아니라, 질문 문장에는 담기지 않은 의도까지 포함하여 검색할 수 있는 것이다.
예시를 들어보겠다.
예시
유저가 다음과 같은 질문을 한다고 하자.
질문 : Python에서 1부터 10까지 더하는 방법을 알려줘.
이러한 경우 유저에게는 두 가지 의도가 있을 수 있다.
- Python에서 1부터 10까지 더하는 코드를 작성해줘.
- Python에서 1부터 10까지 더하는 방법을 상세하게 줄글로 설명해줘.
이러한 경우에 질문과 관련된 문서는 코드 그 자체와, 코드를 설명한 줄글로 두 가지 종류가 있을 것이다. 그리고 실제 유저의 의도가 1처럼 코드를 원할 때에는 코드 문서를, 2와 같이 줄글을 원할 때에는 줄글 문서를 높은 relevance (관련성) 점수를 주어야 할 것이다.
TART는 이러한 상황을 위해, 유저의 의도를 질문 및 단락과 함께 리랭커 모델에 넣어준다. 그러면 TART가 의도를 고려하여 단락을 재정렬한다. 위의 예시에서 유저가 코드를 원한다는 의도를 넣어 주었다면 코드 문서를, 풀이글을 원했다면 풀이글 문서를 높은 순위로 재정렬 해 주는 것이다.
만든 방법
연구진들은 BERRI라는 instruction-질문-정답 단락 쌍이 있는 데이터셋을 만들고, 그것으로 리랭커를 학습시켰다. 더 자세한 부분은 논문을 참고해주시길.
AutoRAG에서 성능 비교하기
TART 리랭커의 성능을 직접 확인해보고 싶다면? AutoRAG에서 간단하게 성능을 비교해보자.
YAML 파일만 수정하면 간단하게 사용할 수 있다.
아래와 같이 YAML 파일을 구성해 보았다.
node_lines:
- node_line_name: retrieve_node_line
nodes:
- node_type: retrieval
strategy:
metrics: [ retrieval_recall, retrieval_ndcg, retrieval_map]
speed_threshold: 10
top_k: 30
modules:
- module_type: bm25
- module_type: vectordb
embedding_model: openai
- node_type: passage_reranker
strategy:
metrics: [retrieval_f1, retrieval_recall, retrieval_precision]
speed_threshold: 10
top_k: 5
modules:
- module_type: pass_reranker
- module_type: tart # 이곳에서 TART 리랭커를 사용할 수 있다.
instruction: "Find passage contains detailed code to implement user's query"
- module_type: upr
prefix_prompt: "단락 - "
suffix_prompt: "주어진 단락을 바탕으로 사람이 할 만한 질문을 적어주세요."
- module_type: flag_embedding_reranker위 YAML 파일에서는 Retrieval에서 벡터 유사도 검색과 BM25 방법을 비교한다.
그 후에, 리랭커 단계에서는 리랭커를 안쓰거나, UPR, Flag Embedding 리랭커, 그리고 TART 리랭커의 성능을 비교한다.
이 YAML 파일을 활용해서, 2개의 Retrieval 모듈과 4개의 리랭커 모듈 중 최적의 조합을 빠르게 찾을 수 있는 것이다.
AutoRAG를 설치하고 위 YAML 파일을 이용해 직접 실험하는 방법은 여기를 참고하자.
TART 리랭커 사용시 주의점
-
CUDA 사용을 권장한다. CPU도 정상 작동하나 시간이 오래 걸릴 수 있다.
-
첫 실행 시 모델을 다운로드 받아야 하기 때문에 시간이 오래 걸릴 수 있다. 인내심을 가지고 기다리자.
-
TART에는 도메인이나 문서 특성, 사용 의도에 따라 instruction 커스텀이 가능하다는 것이 장점이다. 일반적인 목적의 RAG가 아니라면, 반드시 instruction을 직접 작성하는 것이 성능 향상에 큰 도움이 될 것이다.
여러 instruction을 리스트로 작성하여 instruction 간 성능을 비교하는 것 역시 가능하다. -
한국어로 훈련되지 않은 모델이므로, 한국어에서는 성능이 낮을 수 있다.
더 읽어보기
-
AutoRAG 깃허브 => https://github.com/Marker-Inc-Korea/AutoRAG
-
UPR 리랭커 알아보기 => [링크]
