정형데이터 분류 2강 EDA
1.EDA
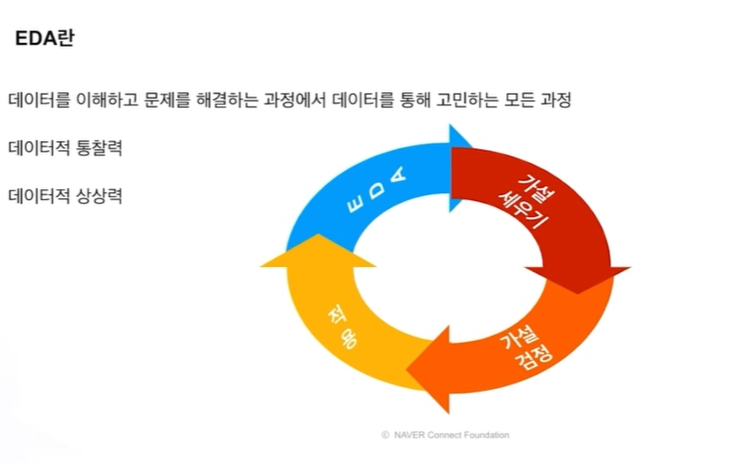
: 데이터를 탐색하고 가설을 세우고 증명하는 과정
다양한 시각을 통해 데이터를 이해하고 특징을 찾아내는 과정
- 이러한 특징들을 시각화, 통계량으로 표현
- 데이터를 특징과 문제들을 직관적으로 이해
- 정형, 비정형 모든 데이터는 분석에 앞서서 이러한 EDA과정을 수반
주어진 문제를 데이터를 통해 해결하기 위해 데이터를 이행하는 과정
- 문제를 해결하는 과정에서 데이터에 대한 이해는 필수적인
- 문제에 대한 이해와 데이터에 대한 이해를 통해 적절한 전처리, 방법론들을 선택
- 즉, 데이터를 통한 문제를 해결하기 위해 데이터를 이해하고 적절한 방법들을 적용
탐색하고 생각하고 증명하는 과정의 반복
1. DATA에 대한 가설 혹은 의무
2.시각화 혹은 통계량, 모델링을 통한 가설 검정
3. 위의 결론을 통해 다시 새로운 가설 혹은 문제 해결
데이터 마다 상이한 도메인
데이터마다 도메인이 상이하고 해결하고자 하는 문제가 다름
- 데이터의 종류, 사용하게되는 모델에 따라 EDA의 방향성은 그때마다 다름
- 금용, 제조, 보건 등 데이터는 고유의 도메인을 가짐
- 일반화가 어렵고 정해진 답이 없음
EDA 시작
가설 혹은 의문을 생각하고 풀어나가는 것이 좋다.
하지만, eda에 대한 개요가 없다면 너무 비효율적
- 개별 변수의 분포, 변수간의 분포와 관계
EDA 타이타닉 데이터
- 개별변수 분포
나이: 20~40대가 많음
왼쪽으로 치우친 포아송 분포가 이룸 - 범주형 변수
일반적인 상식에 맞는지도 확인 - 변수간의 관계
- 성별에 따른 생존비율 : 여성이 더 많이 생존
=> 여성은 먼저 탈출할 수 있도록 배려한 것이 아닐까?
=> 같은 성별 내에서는 어떠한 차이가 있지 않았을까?-> 이름으로 직위나 작위를 확인할 수 있음
2.여성안에서 생존비율: 결혼한 여성이 더 생존했음
=> 아이가 있어 더 많이 살 수 있지 않았을까?
3.독신 / 가족 => 독신인 경우 사망률이 더 많음
=> 도움을 못받아서? 아님 책임감이 덜해서 배려해줬을까?
4.가족 수에 따른 차이 : 중간 가족일때 더 많음, 가족이 많은 경우 사망률이 높음
EDA OUR DATA
- 문제이해 및 가설 세우기
- 이전 달의 TOTAL이 영향을 끼치지 않을까?
- 작년 12월 달의 TOTAL이 영향을 끼치지 않을까?
- 거주 국적에 따른 영향이 있을까?
- 고객마다 주로 구매하는 품목이 있을까? 그렇다면 target에 어떤 영향을 끼칠까?
이러한 가설을 확인하면서 데이터의 특성을 파악 -> 데이터 이해
1.개별 연속형 변수
음수-> 환불 데이터
0~200 사이에 있음
가설: 환불기록이 target에 영향을 미치지 않을까?
가설검정: 환불건수 보다는 구매건수 자체가 유의하다. 구매건수가 높을수록 환불건수가 높다
가설검정: 구매건수와 target은 유의미한 상관관계를 갖는다
2.연속형 변수간의 관계
가설: 2011년 11월 total에 영향을 주는 월은 무엇일까?
가설검정: 2011년 11월의 total과 작년 11월의 total이 높은 상관관계를 갖는다.
- 개별 범주형 변수
가설: 국가별로 total에 차이가 있을까? 국가별로 월별 total간의 관계가 다른지?
국가별로 다른 차이가 없기에 국가 컬럼을 사용하지 않아도 되겠다!
digits number이지만, POST, D와 예외사항으로 둘까?
digits number이지만, 앞자리에 같으면 대분류일까?
워드클라우드를 통해 상품을 분류할 수 있음
word2vec를 통해 상품간의 관계를 알 수 있을듯
description
product_id가 아닌 description을 사용할 경우,NLP로 활용
레이블 생성
TOTAL_THRES = 300
df = data.copy()
# year_month에 해당하는 label 데이터 생성
df['year_month'] = df['order_date'].dt.strftime('%Y-%m') #bef: 2009-12-01 07:45:00 -> aft:2009-12
df.reset_index(drop=True, inplace=True)
# year_month 이전 월의 고객 ID 추출
cust = df[df['year_month']<'2011-11']['customer_id'].unique() # [13085 13078 15362 ... 12966 15060 17911]
# year_month에 해당하는 데이터 선택
df = df[df['year_month']=='2011-11'] # shape (0,10)
#print(df.shape)
# label 데이터프레임 생성
label_1 = pd.DataFrame({'customer_id':cust})
label_1['year_month'] = '2011-11'
# year_month에 해당하는 고객 ID의 구매액의 합 계산
grped = df.groupby(['customer_id','year_month'], as_index=False)[['total']].sum() # as_index: 인덱스에 순위 표시여부
# label 데이터프레임과 merge하고 구매액 임계값을 넘었는지 여부로 label 생성
label = label_1.merge(grped, on=['customer_id','year_month'], how='left')
#print(label)
label['total'].fillna(0.0, inplace=True)
label['label'] = (label['total'] > TOTAL_THRES).astype(int)
# 고객 ID로 정렬
label = label.sort_values('customer_id').reset_index(drop=True)
if True: print(f'{"2011-11"} - final label shape: {label.shape}')분류 평가지표
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score, precision_recall_curve, roc_curve
'''
평가지표를 출력하는 함수
'''
def print_score(label: List[float], pred: List[float], prob_thres: float = 0.5):
print('Precision: {:.5f}'.format(precision_score(label, pred>prob_thres)))
print('Recall: {:.5f}'.format(recall_score(label, pred>prob_thres)))
print('F1 Score: {:.5f}'.format(f1_score(label, pred>prob_thres)))
print('ROC AUC Score: {:.5f}'.format(roc_auc_score(label, pred)))