[부스트코스]AI 엔지니어 기초 다지기
1.1-1 정형 데이터
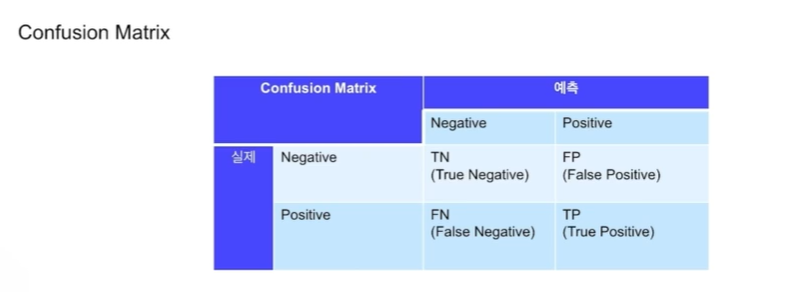
정형 데이터: 엑셀 파일 형식아니 관계형 데이터베이스의 테이블에 담을수 있는 데이터 행(row)과 열(column)으로 표현 가능한 데이터. 하나의 행은 하나의 데이터 인스턴스를 나타내고, 각 열을 데이터의 피처를 나타냄비정형 데이터: 이미지, 비디오, 음성, 자연어
2.1-2 탐색적 자료 분석
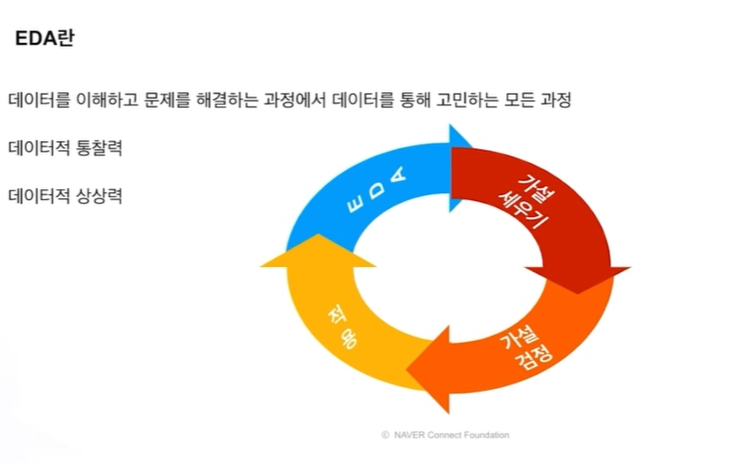
: 데이터를 탐색하고 가설을 세우고 증명하는 과정다양한 시각을 통해 데이터를 이해하고 특징을 찾아내는 과정이러한 특징들을 시각화, 통계량으로 표현데이터를 특징과 문제들을 직관적으로 이해정형, 비정형 모든 데이터는 분석에 앞서서 이러한 EDA과정을 수반주어진 문제를 데이
3.1-3 데이터 전처리
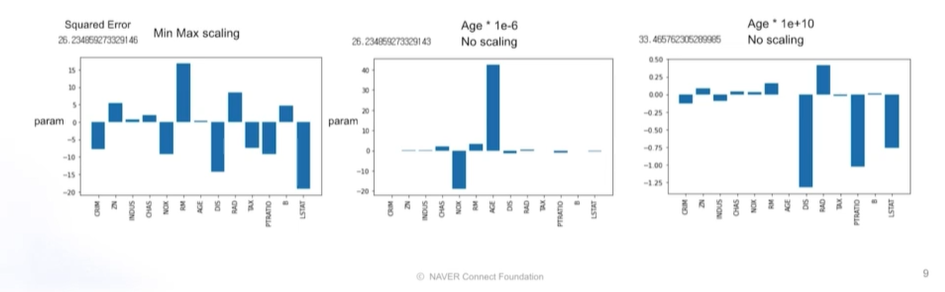
데이터 전처리: 머신러닝 모델에 데이터를 입력하기 위해 데이터를 처리하는 과정EDA에 따라 달라지는 데이터 전처리모델,목적에 따라 달라지는 데이터 전철선형모델? 트리? 딥러닝? -> 달라지는 데이터 전처리 방식데이터 전처리연속형, 범주형 처리결측치 처리이상치 처리Sca
4.1-4 머신러닝 기본 개념
fit: 데이터를 잘 설명할 수 있는 능력Underfitting: 데이터를 설명하지 못함Overfitting: 데이터를 과하게 설명우리의 데이터셋은 전체 일부분if 우리의 데이터셋이 전체와 유사하다면 Overfitting is best(거의 없음)Underfitting
5.1-5 트리 모델

:칼럼값들을 어떤한 기준으로 group을 나누어 목적에 맞는 의사결정을 만드는 방법하나의 질문으로 yes or no을 decision을 내려서 분류일련의 분류기준을 설명한 뒤 데이터를 분류 예측하여 일련의 규칙을 찾는 알고리즘(스무고개하는 느낌)트리 모델의 발전bagg
6.2-1 피처 엔지니어링

1.feature engineering (1) : 원본 데이터로부터 도메인 지식 등을 바탕으로 문제를 해결하는데 도움이 되는 feature를 생성, 변환하고 이를 머신 러닝 모델에 적합한 형식으로 변환하는 작업 머신러닝 성능의 80% 는 여기 부분에서 결정이 난다 1
7.2-2 하이퍼 파라미터 튜닝
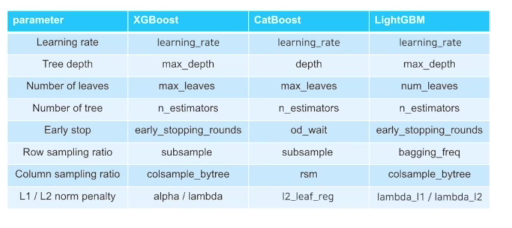
하이퍼파라미터: 모델이 학습과정에서 컨트롤하는 파라미터 value학습하기 전에 사람이 직접 설정하는 파라미터하이퍼파라미터 튜닝: 하이퍼파라미터를 최적화하는 과정하이퍼 파라미터 튜닝 방법Manual Search: 자동화 툴을 사용하지 않고 매뉴얼하게 실험할 하이퍼파라미터
8.2-3 앙상블
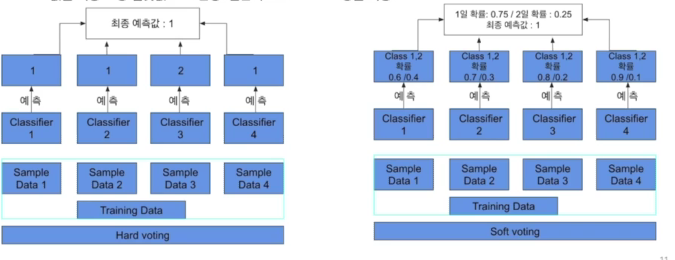
여러개의 결정 트리를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝기법앙상블 학습의 핵심은 여러 개의 약 분류기를 결합하여 강 분류기 만드는 과정여러 개의 단일 모델들의 평균치를 내거나, 투표를 해서 다수결에 의한 결정을 하는 등 여러 모델들의 집단 지성
9.3-1 벡터, 행렬이가 뭐에요?

벡터는 숫자를 원소를 가지는 리스트 또는 배열열벡터, 행벡터벡터는 공간에서 한 점을 나타냅니다.벡터는 원점으로부터 상대적 위치를 표현합니다.벡터에 숫자를 곱해주면 길이만 변합니다.(스칼라곱)!스칼라가 1보다 크면 길이가 늘어나고, 1보다 작으면 길이가 줄어듬(단, 0보
10.3-2 경사하강법
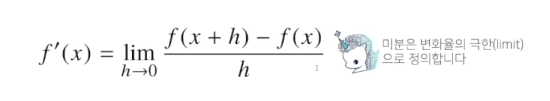
변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구로 최적화에서 제일 많이 사용하는 기법최근엔 미분을 손으로 직접 계산하는 대신 컴퓨터가 계산해 줄 수 있습니다.미분은 함수f의 주어진 점(x, f(x))에서의 접선의 기울기를 구한다.한 점에서 접선의 기울기를 알면
11.3-3 딥러닝 학습방법 이해
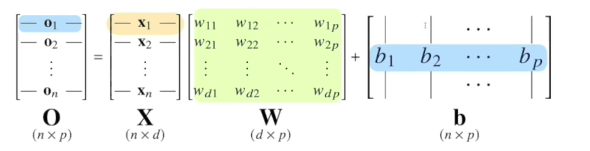
참고소프트 맥스소포트맥스 함수는 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산입니다.분류 문제를 풀떄 선형모델과 소프트맥스 함수를 결합하여 예측학습을 하는 경우는 사용하나, 추론으로 할때는 최댓값을 가진 주소만을 1로 출력하는 연산을 사용하므로 소포트 맥스가 아
12.4-1 확률론 맛보기 냠

딥러닝에서 왜 확률론이 필요한가?
13.4-2 통계학 맛보기 냠

통계적 모델링은 적절한 가정 위에서 확률분포를 추정하는것이 목표이며, 기계학습과 통계학이 공통적으로 추구하는 목표그러나 유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확하게 알아낸다는 것은 불가능하므로, 근사적으로 확률분포를 추정할 수 밖에 없다.데이터가 특정 확률
14.4-3 베이즈 통계학 맛보기 냠

조건부확률: 특정 B가 일어난 상황에서 A가 일어날 상황/특정 사건 B가 일어난 상황베이즈 정리는 조건부확률을 이용하여 정보를 갱신하는 방법을 알려줌베이즈 정리 예제D: 새로운 데이터θ: 가설, 모델링하는 이벤트, 모델에서 계산하고 싶어하는 파라미터(모수) 등(1):
15.5-1 딥러닝 기초
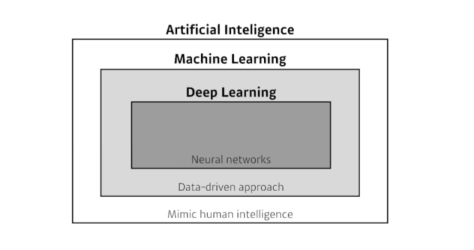
인공지능: 사람의 지능을 모방하는 것머신러닝: 사람의 지능을 모방하는 방법중 데이터로 학습하는 방법딥러닝: 뉴럴네트워크를 사용하는 방법딥러닝의 4가지 주요 요소데이터모델손실 함수알고리즘(손실 함수를 최소화하기 위한 알고리즘)연구, 논문을 볼때 4가지 접근으로 확인데이터
16.5-2 딥러닝 기초2
정의포유류의 뇌신경망을 모방하고자 하는 시스템, 애매하게 영향을 받은 컴퓨터 시스템이다(위키피디아).요소: 기울기, 절편, 2개의 파라미터loss 함수의 값을 최소화 값을 찾기 위해서 W에 대한 편미분함W,b를 계속 업데이트 하는데 이를 Gradient descent라
17.5-3 최적화
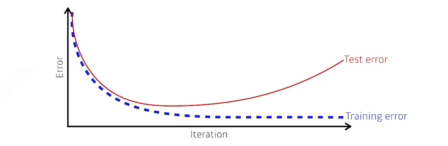
Gradient descent 로컬 미디엄을 찾기위해 1차 미분을 반복적으로 최적화하는 알고리즘일반화 성능을 높이는게 목표임 그렇다면 일반화는 뭘까?generalization:training error와 test erorr 차이와 관련일반적으로 일반화가 좋다는것은 te
18.5-4 최적화2
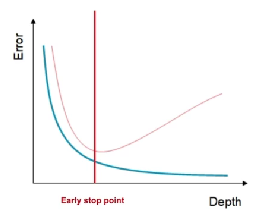
Regularization 규제를 건다 - 학습을 방해하도록 무엇가를 한다 why? test 데이터에도 잘 동작할 수 있도록 Early stopping 학습을 멈추는 것 Parameter norm penalty 뉴럴네트워크 파라미터를 너무 커지는것을 방지 네트워크
19.6-1 Convolutional Neural Networks (CNN)
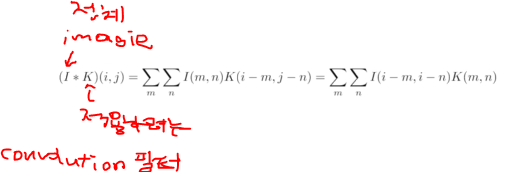
2D image convolutionconvolution한다는 것은 어떤 의미가 있을까?해당 Convolution 필터 모양은 해당 이미지에서 찍는다고 했는데 즉, 적용하고자 하는 필터의 모양에 따라서 같은 이미지에 대해서 Convolution의 결과가 Blur가 될수
20.6-2 CNN-2
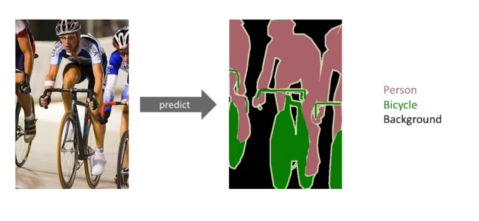
어떤 이미지가 있을때, 각 픽셀마다 분류를 하는것활용 예시: 자율주행, 운전보조장치 기본적인 CNN구조: 이미지 하나가 들어오면 어떠한 과정을 걸치고 마지막에 dense layer를 통과시켜 1000개짜기 아웃풋을 생성flat -> 20 x 20 x 1000 => 40
21.6-3 Recurrent Neural Networks (RNN)
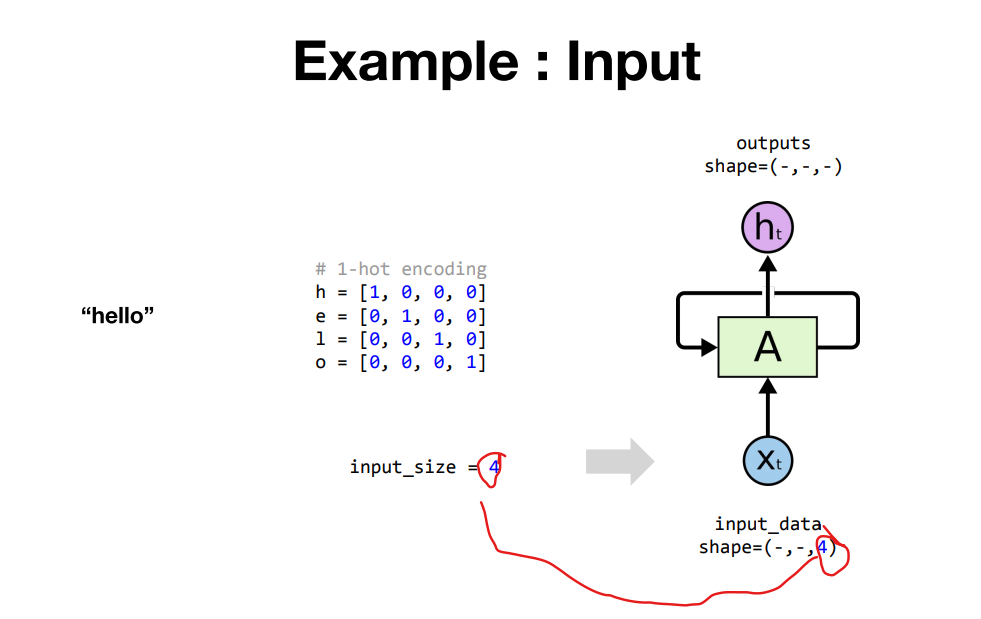
Sequential Models - RNN Sequential Model Sequential data: 말, 음성, 영상, 모션..등 어려운 점: 얻고 싶은것은 하나의 라벨, 정보인데 받아드려야 하는 차원(몇 개의 음절,음성) 을 알 수 없음 가장 기본적인 Sequ
22.6-4 Generative Model

'Generative Model을 만든다'는 무엇을 말하나요?단순히 GAN을 가지고 그럴듯한 이미지를 만다는걸로 생각할 수 있지만, 그것이 전부는 아니다.예를 들어 강아지 이미지가 주어졌을 때,서로 다른 강아지를 생성(Generation)고양이같은지? 강아지 같은지 구