Part 1 - 데이터 불러오기
결측치 제거하기
df= df.dropna(axis=1) #결측치 있는 열 삭제
자료형의 시계열 객체 변환
pd.to_datetime(df['열이름'])
오늘까지 얼마나 날짜가 차이날까
today =datetime.now() today-df['열이름']위에 링크 참고
주어진 조건에 따라 새로운 데이터프레임 열 생성
참고 예시 conditionlist = [ (df['Salary'] >= 500) , (df['Salary'] >= 300) & (df['Salary'] <300), (df['Salary'] <= 300)] choicelist = ['High', 'Mid', 'Low'] df['Salary_Range'] = np.select(conditionlist, choicelist, default='Not Specified')조건이 여러가지 일때 select 사용 한가지라면 where함수
참고
정수를 시계열 자료형으로 변환
pd.to_timedelta(df['열이름'], unit='D')
N122
파일에서 데이터로 취급하지 않은 수 제거, 인덱스 순서 정리
col = ['컬럼1', '컬럼2', '컬럼3'] row = ['인덱스1', '인텍스2', '인덱스3', '인덱스4'] df = pd.read_csv('파일명.csv', encoding = 'cp949', skiprows=(0,1), index_col=0, names= col) df= df.reindex(row)skiprows=()는 파일에서 데이터로 취급하지 않는 수 제거 참고
reindex(row): 인덱스 정려을 위한 메서드 참고
열 기준으로 합하기
f_sum = df.sum(axis=1)
판다스 객체를 nummpy 배열 객체인 ndarray로 반환
df_sum.to_numpy()
N121
특정 데이터에서 제외시키기
df['행이름'][~df['행이름'].isin(['데이터1','데이터2','데이터3'])]~붙이면 그거 빼고 추출한다는 의미로 해석,(~ :not)
isin을 활용한 색인
if 문 활용한 p value 해석
alpha = 0.05 if P1 < alpha: ans = '가설1(귀무가설) 기각' #if 문이 거짓일 때 elif 사용 elif P2 < alpha: ans = '가설2(귀무가설)' #if, elif 다 거짓일 때 else 사용 else: ans = '귀무가설을 기각할 수 없다'
N123
데이터셋 불러올때 특정 데이터 행만 열기
df = pd.read_csv('파일명.csv', usecols=['행이름1','행이름2'])
빈 figure만들기
fig = plt.figure()
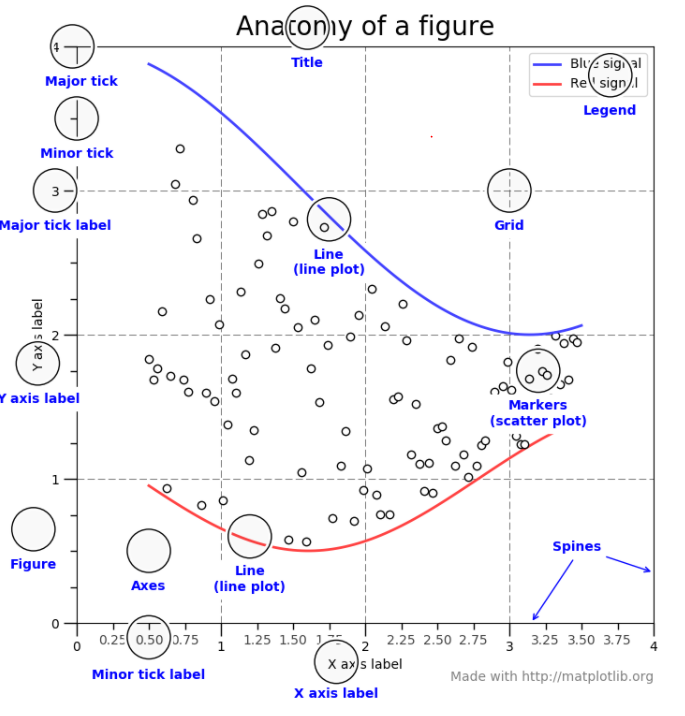
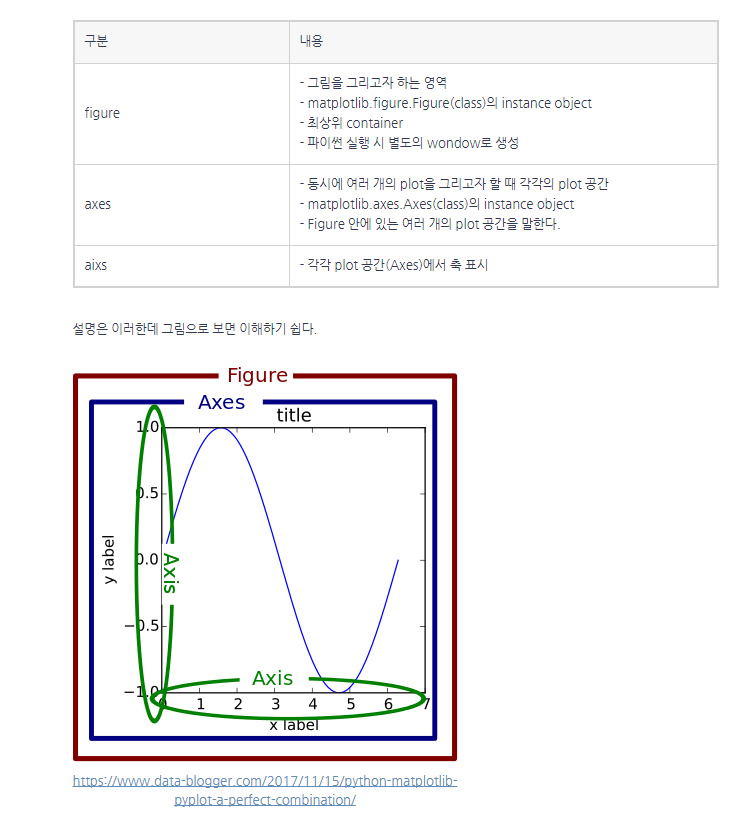
fig.add_axes([0,0,1,1])첫 0은 이미지의 x축의 위치, 두번째 0은 이미지의 y축의 시작위치, 세번째 1은 이미지의 가로길이, 네번째 1은 높이를 의미
참고

마루에 미친자