SC11X
f문자열 포매팅
print(f"df.csv 결측치: \n {df1.isnull().sum()}\n ")\n: 한 줄 띄어쓰기하는 이스케이프 (파이썬 기초 1.문자열부분 확인)
f-string:문자열 안에 변수 값을 끼워넣어 원하는 포맷으로 변환하는 하는 것(파이썬 기초1 문자열부분 확인)
참고
특정조건 추출
is_korea = df['country']=='kor' is_2018=df['Year']== 2018 korea = df[is_korea&is_2018] koreadf.loc[(df['country']=='kor')&(df['Year']==2018)]
SC12X
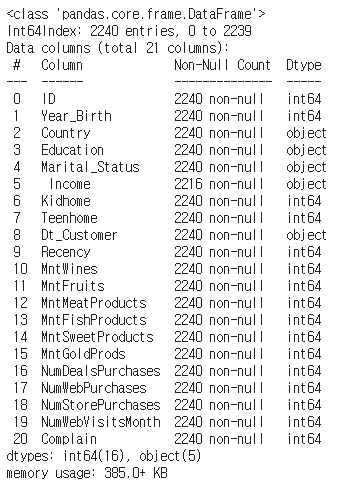
df.info 출력 해석하기
왼쪽부터 차례대로 칼럼명, 결측값이 아닌 데이터의 수, 데이터 타입
참고
df.loc 조건문/pd.Timedelta
출처
df['가입한 기간 '] = (pd.Timestamp.today() - df['가입한 날'])Timestamp.today()- 현재 날짜
df['가입한 날짜']- 가입한 날짜
날짜-날짜=> 타임델타df.loc[((df['featrue 1'] >= 20) & (df['featrue 2'] >= pd.Timedelta("100 days"))), 'VIP'] = True df.loc[~((df['featrue1'] >= 20) & (df['featrue 2'] >= pd.Timedelta("100 days"))), 'VIP'] = FalseTimedelta: 절대기간
df.loc 조건문 참고할만 블로그
SC13X
몇개의 feature에만 정규화하기 출처
import pandas as pd data = pd.DataFrame({'Name' : [3, 4,6], 'Age' : [18, 92,98], 'Weight' : [68, 59,49]}) col_names = ['Name', 'Age', 'Weight'] features = data[col_names]from sklearn.compose import ColumnTransformer from sklearn.preprocessing import StandardScalerct = ColumnTransformer([ ('somename', StandardScaler(), ['Age', 'Weight']) ], remainder='passthrough') ct.fit_transform(features)'somename'은 그냥 내가 아무거나 지정(Name 설정)
공식문서
K-means 적용하고 그 결과를 그래프로 그리기
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters = 3) #3개로 나눈다 kmeans.fit(df[['x','y']]) # or kmeans.fit(df) df['cluster_id'] = kmeans.labels_ # 'cluster_id' feature에 각각 4개의 군집의 라벨 표시(여기서는 3개니까 0,1,2으로 표기되어있음)import seaborn as sns sns.scatterplot(x = 'x', y = 'y', data = df, hue='cluster_id', palette='RdYlBu_r') ```'
궁금증
df:컬럼이 x,y 만 있는 데이터 프레임 이라고 가정(SC13X- 7번)
kmeans.fit(df[['x','y']]) vs kmeans.fit(df)의 차이는?
위에 보면 kmeans.fit의 인자 X는 array- like 형식이다.
array- like 형식이란
kmeans.fit(df[['x','y']]) vs kmeans.fit(df)둘은 표현의 차이일 뿐이고 실제로 둘은 type도 같고 출력하면 동일하게 나온다
출처1
출처2

마루에 미친자