Warm up
필요한 라이브러리 설치
sklearn 버전 0.23
!pip uninstall scikit-learn -y !pip install -U scikit-learncategory_encoders
!pip install category_encoders
원핫인코딩
범주형 데이터를 숫자로 변환하는 과정
범주형 데이터: 명목형 데이터와 순서형 데이터로 나뉨명목형 데이터에 순서형 인코등 안하면 대소관계를 갖으니 주의
집합의 크기(cardinality)
The cardinality of a set means the number of its elements. For example, the set A = {2, 4, 6} contains 3 elements,판다스로 원핫인코딩
df_oh = pd.get_dummies(df, prefix=['City'])## 불필요한 요소를 없인 더미 코딩 df_dum = pd.get_dummies(df, prefix=['City'], drop_first=True)우선,더미 코딩이전에 원핫인코딩해보기를 권장
Category_encoders
from category_encoders import OneHotEncoder encoder = OneHotEncoder(use_cat_names = True) X_train = encoder.fit_transform(X_train) X_test = encoder.transform(X_test)

feature selection
이전에는 특성선택할때 상관관계가 높은 것 위주로 선택하였다면,이제 사이킷런의 SelectKBest를 사용해서 회귀모델에 중요한 특성을 선택할 수 있음(k개 선택)
- 특성 선택(Feature Selection)은 특성 공학(Feature Engineering)에 포함
- 좋은 특성을 뽑는 방법은 특성들끼는 상관성이 적으면서 타겟과는 상관성이 높은 것을 뽑는것
## f_regresison, SelectKBest from sklearn.feature_selection import f_regression, SelectKBest ## selctor 정의합니다. selector = SelectKBest(score_func=f_regression, k=10) ## 학습데이터에 fit_transform X_train_selected = selector.fit_transform(X_train, y_train) ## 테스트 데이터는 transform X_test_selected = selector.transform(X_test)select_mask=selector.get_support() scores = selector.scores_[select_mask]특성의 수 k 를 어떻게 결정하는가?
MAE, R2 점수들을 고려해야함
- MAE는 낮은것, R2은 높은 것을 선택
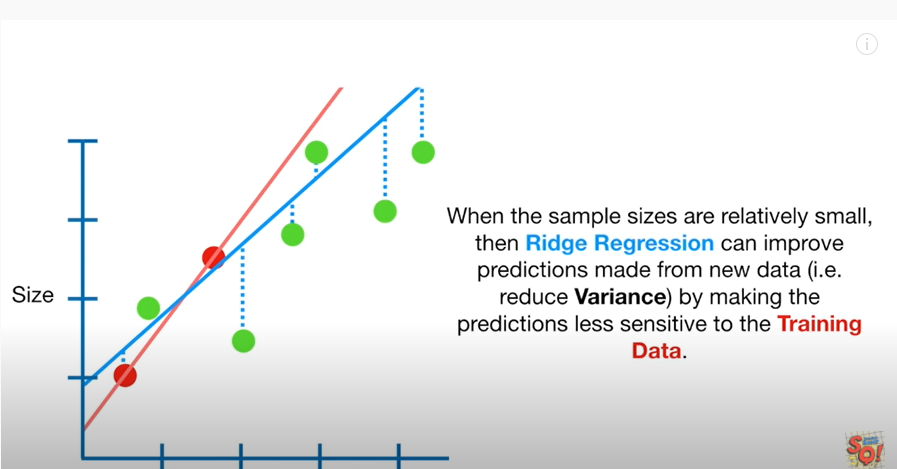
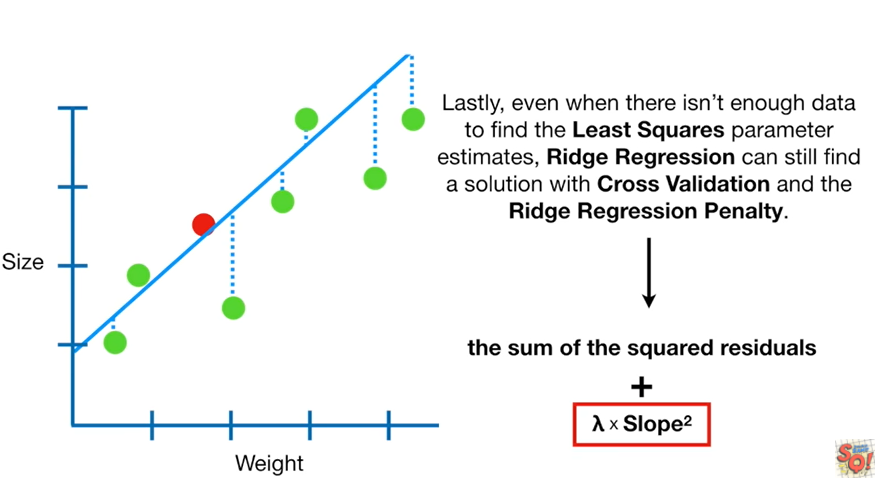
Ridge Regression 모델 학습
Ridge Regression: 편향에러를 더하는 대신 분산을 낮추고 일반화를 유도하는 모델
:
- 기존 다중회귀선을 훈련데이터에 덜 적합이 되도록 만든다는 것 why? 과적합을 줄이기 위해서
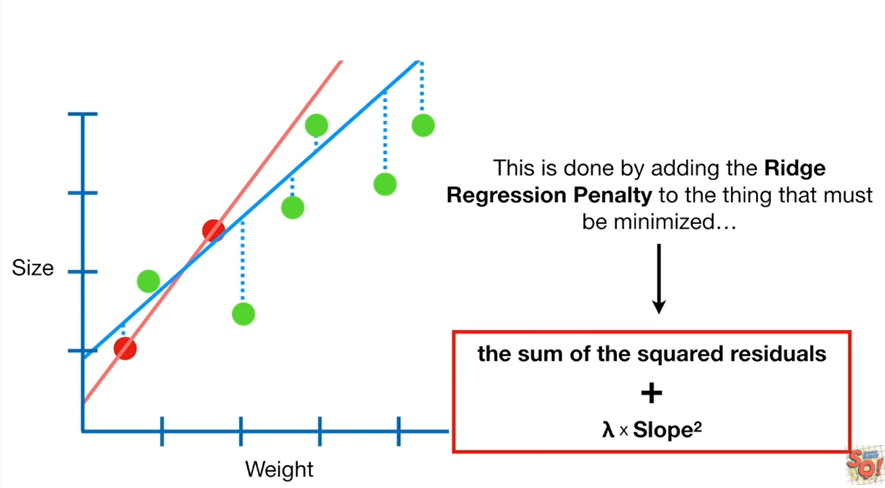
- Ridge 회귀는 이 편향을 조금 더하고, 분산을 줄이는 방법으로 정규화(Regularization)를 수행
- 정규화는 모델을 변형하여 과적합을 완화해 일반화 성능을 높여주기 위한 기법
샘플수, p: 특성수, λ : 튜닝 파라미터(패널티)
- λ =alpha, lambda, regularization parameter, penalty term
- λ 는 정규화의 강도를 조절
- → 0, →
#람다가 0에 가까워지면 다중회귀분석이 됨- → ∞, → 0
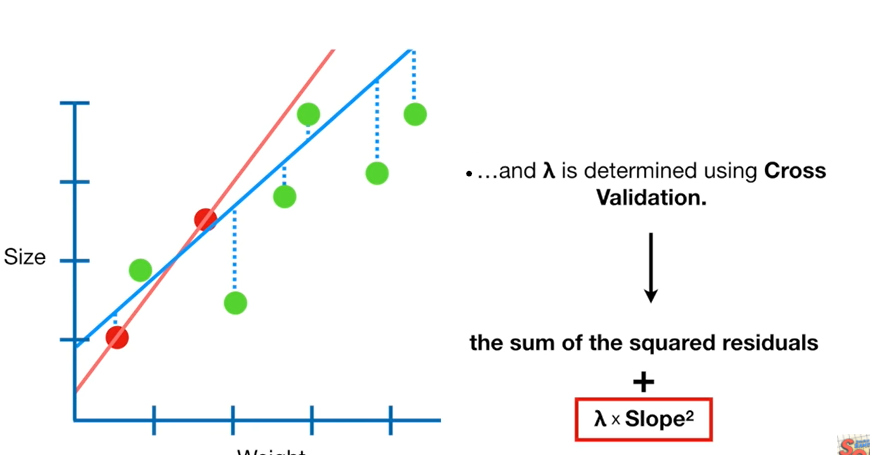
패널티값을 보다 효율적으로 구할 수 있는 방법이 있을까요?
어떤 특별한 공식이 있는 것은 아니며, 여러 패널티 값을 가지고 검증실험을 해 보는 방법을 사용해야한다
- 교차검증(Cross-validation)을 사용해 훈련/검증 데이터를 나누어 검증실험을 진행
RidgeCV를 통한 최적 패널티(alpha, lambda) 검증
from sklearn.linear_model import RidgeCV alphas = [0.01, 0.05, 0.1, 0.2, 1.0, 10.0, 100.0] ridge = RidgeCV(alphas=alphas, normalize=True, cv=3) ridge.fit(X_train, y_train) print("alpha: ", ridge.alpha_) print("best score: ", ridge.best_score_)


np.percentile 사용해 이상치 제거
상위 5%, 하위 5%인 데이터를 삭제
df = df[(df['price'] >= np.percentile(df['feature이름'], 0.05)) & (df['price'] <= np.percentile(df['feature이름'], 99.5))]
fix, transform, fix_transform
transform()
: 훈련 데이터에서 모델 파라미터를 학습
- 모델 머신러닝/딥러닝에서 사용되는 모델일 수도 있고, Imputer(결측치 대체), PolynomialFeatures(다항차수변환), VarianceThreshold(분산으로 특징 추출), MinMaxScaler(정규화), StandardScaler(표준화), LabelEncoder(인코딩), OneHotEncoder(원핫인코딩) 등과 같은 메소드일 수도 있다.
- room-서울이라고 학습하는 것을 fit
transform()
: 학습한 파라미터로 데이터를 변환
- room-서울이다를 1로 바꿔주는 것을 transfrom
fit_transform()
:fit() 과 transform() 메소드를 함께 사용하도록 한 것왜 test data에서는 fit_transform을 사용하지 않는가?
N213
pandas_profiling
pandas_profiling 설치
!pip install pandas-profiling==2.9.0 --userimport pandas_profiling from pandas_profiling import ProfileReport profile = ProfileReport(df, title="Pandas Profiling Report")
더 알아볼것
polynoimal(다항식)
- 다항식에 적용한 릿지 회귀모델

마루에 미친자