K-Nearest Neighbors(KNN)
K-최근접 이웃 알고리즘
KNN이란?
- 유유상종의 개념과 유사
- 새로운 데이터 포인트와 가장 가까운 훈련 데이터셋의 데이터 포인트를 찾아 예측
- k 값에 따라 가까운 이웃의 수가 결정
- 분류와 회귀에 모두 사용가능
- k = n_neighbors
- 모든 거리를 이용해서 가까운 이웃을 찾는다.
- 유클리디안 공식을 이용
컴퓨터가 계산할 때는 특성 개수만큼 차원이 커짐. 차원 때문에 피타고라스의 정리로 계산할 수 없음. 차원의 문제를 해결한 거리공식인 유클리디안 거리공식을 이용함.
: 특성이 많아도 계산할 수 있는 공식 = 유클라디안 거리공식- 클래스가 여러 개일 때 = 분류
- 연속적인 값을 예측할 때 = 회귀
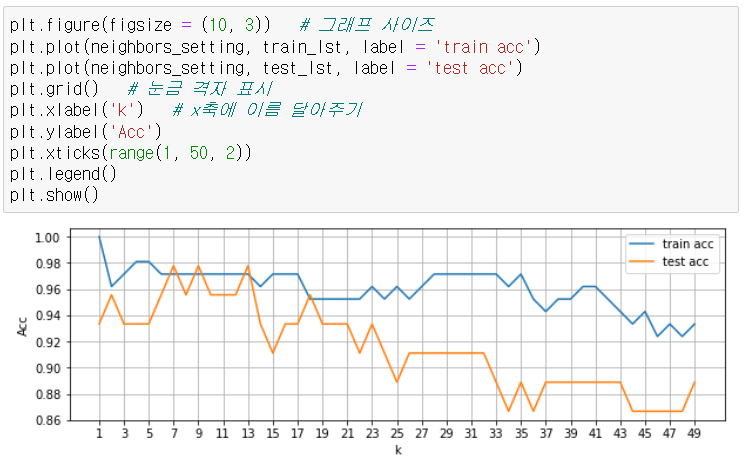
- k값에 따라서 결과가 바뀔 수 있다.
KNN개념정리
- k값이 작을 수록 모델의 복잡도가 상대적으로 증가(noise 값에 민감)
noise = 이상치
복잡도가 상대적으로 증가 = 과대적합일 확률이 높다.- 반대로 k의 값이 커질수록 모델의 복잡도가 낮아진다.
모델의 복잡도가 낮아짐 = 과소적합일 확률이 높다. 트레인데이터에 대한 성능이 떨어지고, 테스트데이터에 대한 성능도 떨어짐.
장단점 및 키워드
- n_neighbors : 이웃의 수, metrics : 유클라디안 거리 방식
- 이해하기 쉬운 모델
- 새로운 테스트 데이터 세트가 들어오면 훈련데이터 세트와의 거리를 계산해서 훈련 데이터세트가 크면 (특성, 샘플의 수) 예측이 느려짐
= 거리를 계산해야해서 데이터가 많아지면 시간이 오래걸린다.- 수백개의 많은 특성을 가진 데이터 세트와 특성 값 대부분이 0인 희소(sparse)한 데이터세트에는 잘 동작하지 않음
- 거리를 측정하기 때문에 같은 scale을 같도록 정규화 필요
= 변수끼리 데이터의 규모차이가 크면 scale을 같도록 만들어줌(단위를 줄여줌)
iris 실습
라이브러리 가져오기
from sklearn.datasets import load_iris # 붓꽃 데이터
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier # 분류 예측기
from sklearn.metrics import accuracy_score # 정확도 측정 도구
#{'키' : '벨류'} # 딕셔너리
# 머신러닝 데이터셋 구조 : 번치객체(bunch)
# 딕셔너리랑 똑같이 생김, 사용법도 같음, 근데 번치객체라고 부름.
# 데이터 확인
iris_data = load_iris()
iris_data# iris_data 의 키값들 확인
iris_data.keys()
# 'DESCR' : 정보를 알려줌.

문제데이터 프레임화
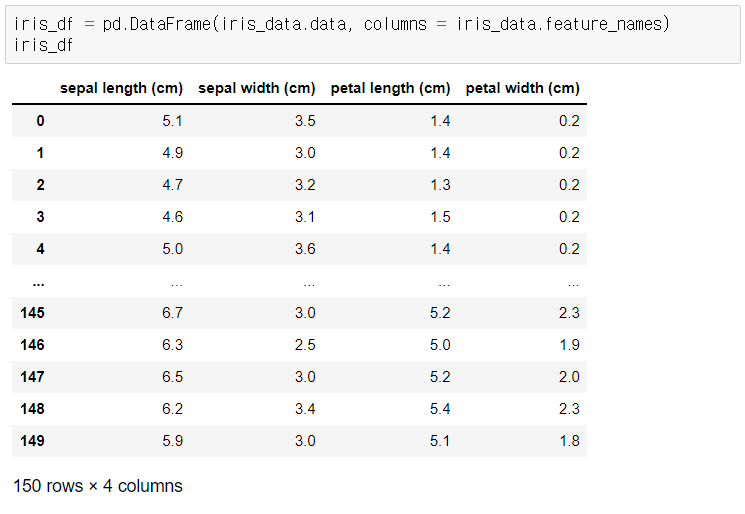
문제와 답 분리

훈련셋, 테스트셋으로 분리
# 분리하는 도구
from sklearn.model_selection import train_test_split
# test_size = 0.3(30%)
# random_state : 데이터를 랜덤하게 섞는 기준
# trian_test_split 기능 : 1. **랜덤샘플링**(랜덤하게 섞음), 2. train/test 분리
# X_train, X_test, y_train, y_test = train_test_split(문제, 답, test_size = , random_state = ) # test_size를 train_size = 0.7로 입력해도된다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 65)
X_train
# random_state 랜덤이 계속 바뀌지 않게(계속실행하면 계속 섞임). 숫자는 그냥 고정하는 숫자임. 숫자 크기는 상관 없음.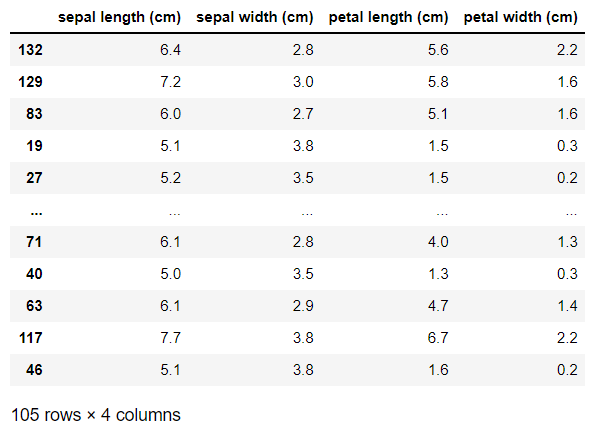
EDA
산점도 행렬 그려보기
: 한꺼번에 변수간의 관계를 파악
: 어떤 특성 데이터가 품종을 잘 분류하고 있는가?
pd.plotting.scatter_matrix(iris_df, figsize = (8, 8), c = y, alpha = 1) # 세 개의 색에 대해 각각 다른 색이 찍히도록 c = y
plt.show() # 그래프만 출력
# 같은품종끼리 뭉쳐져 있으면(밀집도↑) 변수간의 관계성 높음.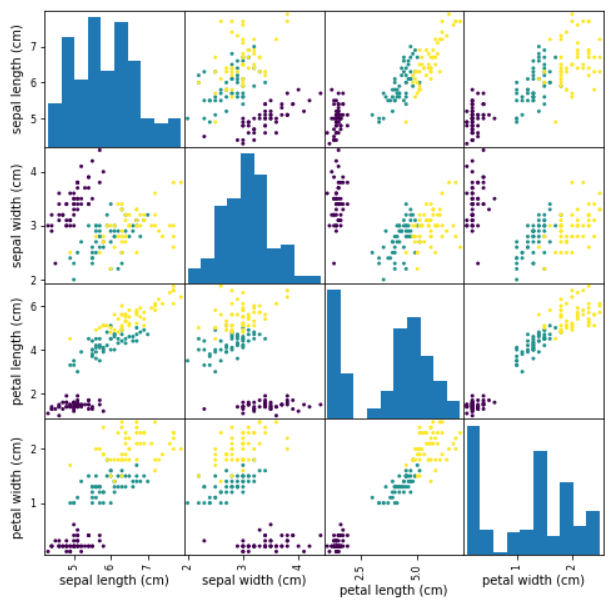
모델링
1. 모델 객체 생성
knn_model = KNeighborsClassifier(n_neighbors=5)홀수를 써주는게 더 명확함. 두 개 중에 어떤것이 더 가까운지.
(보통은 3~7으로 많이 설정한다.)
2. 모델학습 (fit)
knn_model.fit(X_train, y_train)
3. 모델 예측 (predict)
pre = knn_model.predict(X_test)숫자가 아닌 품종의 이름으로 확인해보기(인덱싱 활용)
iris_data['target_names'][pre]
4. 모델의 성능 평가 (score / accuracy_score)
knn_model.score(X_test, y_test) # score(테스트 문제, 테스트 답)
accuracy_score(y_test, pre) 두 가지 모두 결과는 똑같음.
둘 중 어떤것을 사용해도 상관 없음.
하이퍼 파라미터 튜닝
knn 에서 하이퍼 파라미터 = k
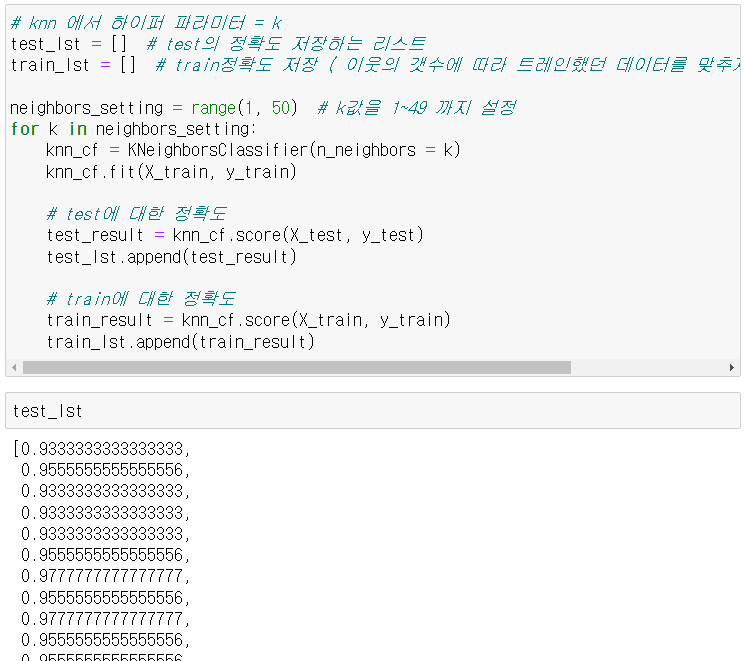
복잡도 곡선 그려보기

asdf