머신러닝
: 컴퓨터가 스스로 학습하여 인공지능의 성능을 향상시키는 기술 방법
머신러닝이 유용한 분야
- 대량의 데이터에서 통찰을 얻어야 하는 문제
- 새로운 데이터에 적응해야 하는 유동적인 환경
- 기존 솔루션으로는 많은 수동 조정과 규칙이 필요한 문제
- 전통적인 방식으로는 전혀 해결 방법이 없는 복잡한 문제
머신러닝 종류
- 지도학습(Supervised Learning)
- 비지도학습(Unsupervised Learning)
- 강화학습(Reinforcement Learning)
지도학습(Supervised Learning)
- 데이터에 대한 Label(명시적인 답)이 주어진 상태에서 컴퓨터를 학습시키는 방법
- 분류(Classification)와 회귀(Regresssion)
- ex. 스팸메일분류, 집 가격 예측
지도학습 - 분류
- 미리 정의된 여러 클래스 레이블 중 하나를 예측하는 것.
- 속성 값을 입력, 클래스 값을 출력으로 하는 모델.
- 이진분류, 다중분류 등
지도학습 - 회귀
- 연속적인 숫자를 예측하는 것.
- 속성 값을 입력, 연속적인 실수 값을 출력으로 하는 모델
- 예측 값의 미묘한 차이가 크게 중요하지 않음.
- 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득 예측 등을 할 수 있다.
비지도학습(Unsupervised Learning)
- 데이터에 대한 Label(명시적인 답)이 없는 상태에서 컴퓨터를 학습시키는 방법.
- 데이터의 숨겨진 특징, 구조, 패턴을 파악하는데 사용.
- 데이터를 비슷한 특성끼리 묶는 클러스터링(Clustering, 군집화)과 차원축소(Dimensionality Reduction)등.
- 이미지 감색 처리, 소비자 그룹 발견을 통한 마케팅 등
강화학습(Reinforcement Learning)
- 지도학습과 비슷하지만 완전한 답(Label)을 제공하지 않음
- 기계는 더 많은 보상을 얻을 수 있는 방향으로 행동을 학습
- 주로 게임이나 로봇을 학습시키는데 많이 사용
- ex. 고양이 급식기
머신러닝 과정
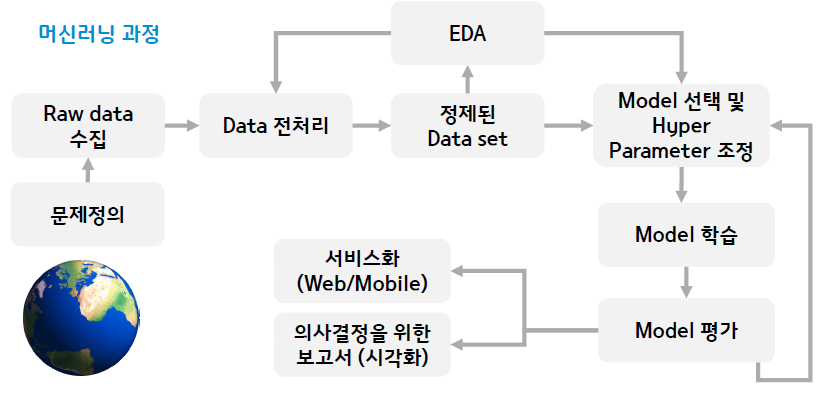
1. Problem Identification(문제 정의)
2. Data Collect(데이터 수집)
3. Data Preprocessing(데이터 전처리)
4. EDA(탐색적 데이터분석)
5. Model 선택, Hyper Parameter 조정
6. Training(학습)
7. Evaluation(평가)
1. Problem Identification(문제 정의)
- 비즈니스 목적 정의모델을 어떻게 사용해 이익을 얻을까?
- 현재 솔루션의 구성 파악
- 지도 vs 비지도 vs 강화
- 분류 vs 회귀
2. Data Collect(데이터 수집)
- File(CSV, XML, JSON)
- Database
- Web Crawler(뉴스, SNS, 블로그)
- IoT 센서를 통한 수집
- Survey
3. Data Preprocessing(데이터 전처리)
- 결측치, 이상치 처리
- Feature Engineering(특성공학) : Scaling(단위 변환),
Encoding(범주형 → 수치형), Binning(수치형 → 범주형),
Transform(새로운 속성 추출)
4. EDA(탐색적 데이터분석)
- 기술통계, 변수간 상관관계
- 시각화 : pandas, matplotlib, seaborn
- Feature Selection(사용할 특성 선택)
5. Model 선택, Hyper Parameter 조정
- 목적에 맞는 적절한 모델 선택
- KNN, SVM, Linear Regression, Ridge, Lasso, Decision Tree, Random forest, CNN, RNN 등
- Hyper Parameter : model의 성능을 개선하기위해 사람이 직접 넣는 parameter
6. Training(학습)
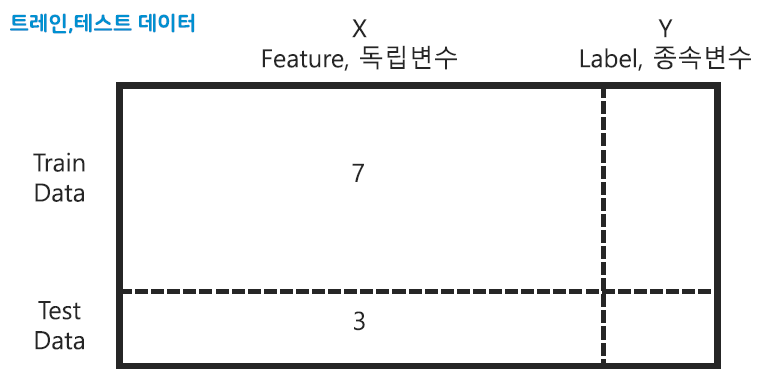
- model.fit(X_train, y_train) : train데이터와 test데이터를 7:3 정도로 나눔
- model.predict(X_test)
7. Evaluation(평가)
분류
- accuracy(정확도)
- recall(재현율)
- precision(정밀도)
- f1 score
회귀
- MSE(Mean Squared Error)
- RMSE(Root Mean Squared Error)
- R^2(R Square)

asdf