[DB] replication
사용자가 점점 많아지면 DB는 많은 Query를 처리하기엔 너무 힘든 상황이 오게 된다.
DB의 과부화를 막고, Query의 대부분을 차지하는 Select를 어느 정도 해결하기 위해 Replication이란 방법이 나오게 되었다.
Replication
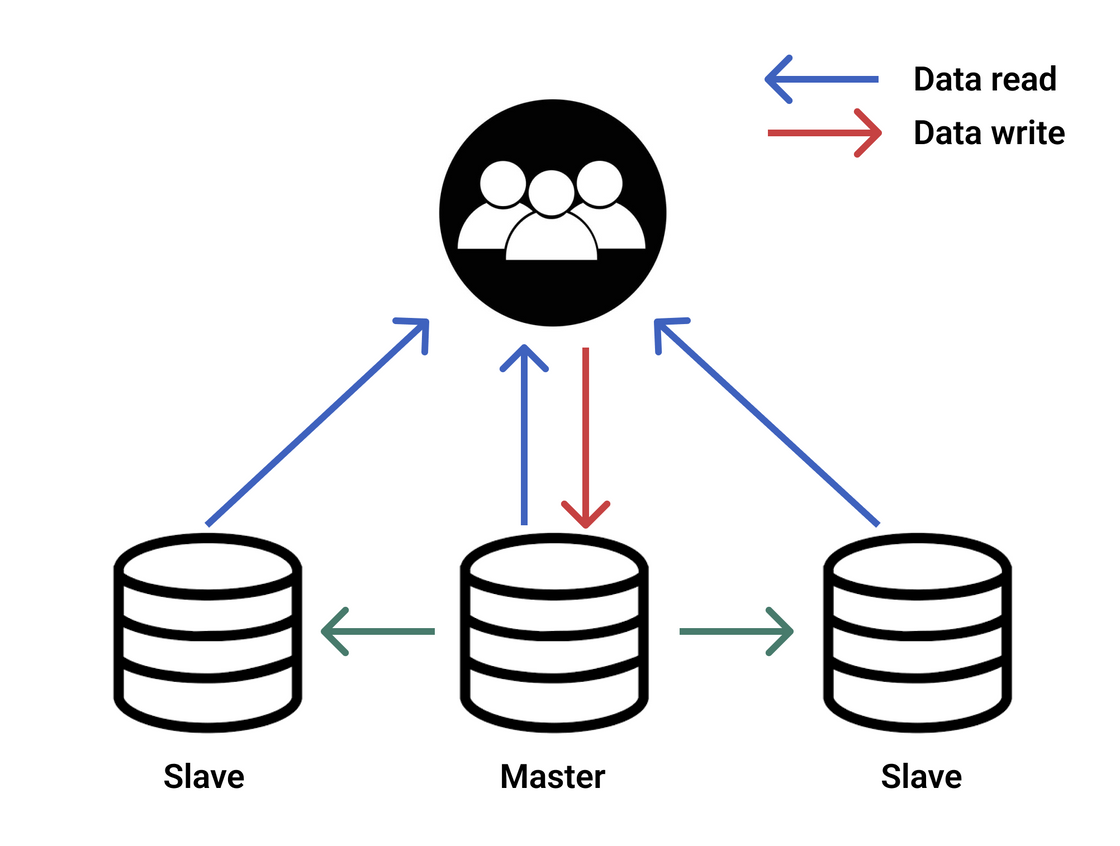
두 개의 이상의 DBMS 시스템을 Mater / Slave로 나눠서 동일한 데이터를 저장하는 방식이다.
Master에는 데이터의 수정사항을 반영만 하고 Replication을 하여 Slave에 실제 데이터를 복사한다.
Slave는 Master 서버로부터 복제된 데이터를 받아서 같은 (읽기) 요청에 대해 대응한다.
예를 들어, 주문 내역 데이터가 필요한 다른 서버들이 데이터를 요청하면, 원본 데이터가 쌓여있는 master 서버가 아닌 똑같은 데이터가 복제된 slave 서버가 데이터를 제공하는 식이다.
여기서 생기는 의문은
master와 slave 서버의 데이터 동기화는 어떤 방식으로 이루어질까?이다.
간단한 과정만 정리해보겠다.
복제 메커니즘
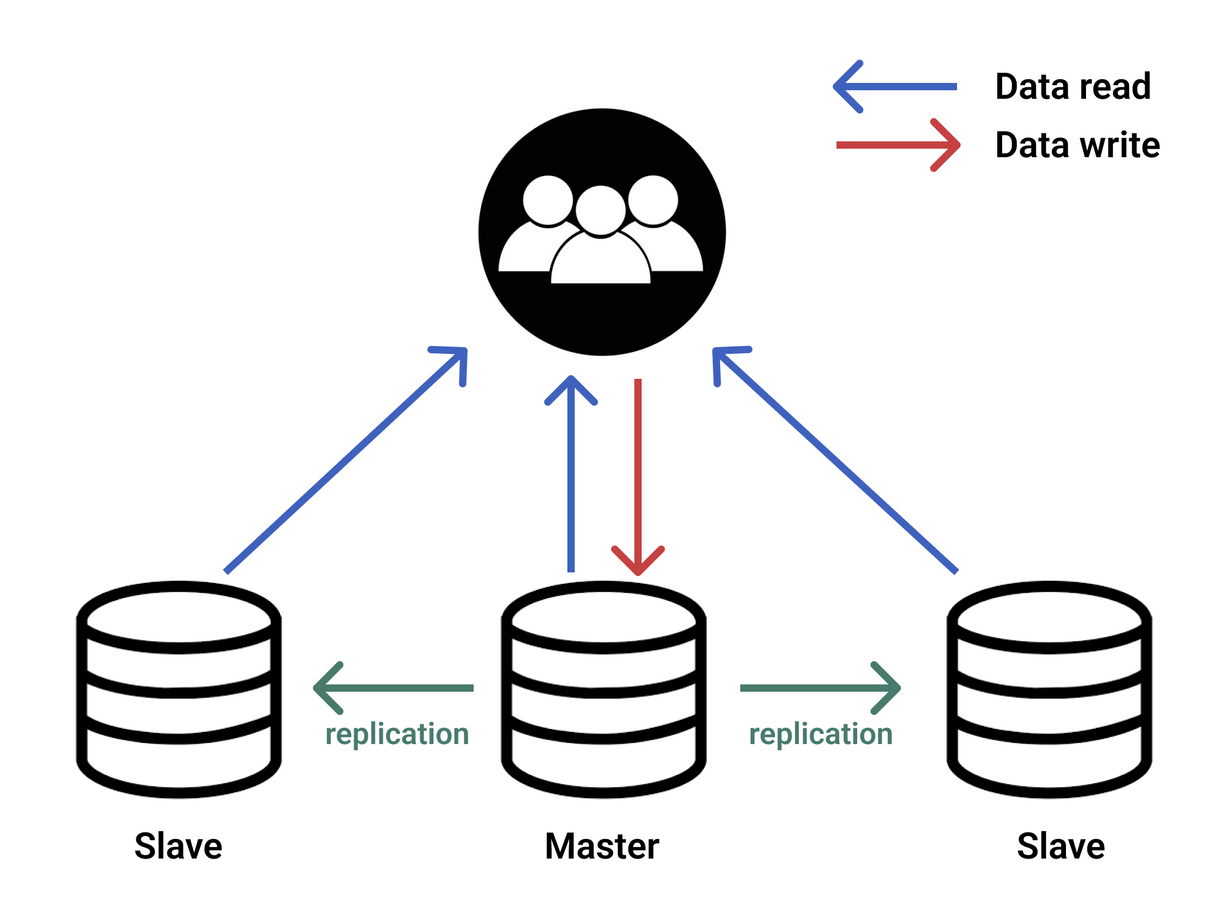
- client가 쓰기 쿼리 작업을 요청한다. 이는 db 서버 중 master 서버가 받는다.
- master 서버는 들어오는 데이터를 binary log라는 파일에 기록한 후, db에 반영한다(commit).
- slave는 현재까지 기록한 이벤트 정보 (GTID=1)를 가지고 다음 이벤트 정보를 master에게 요청한다.
[Slave Thread] - master는 binary log 파일에서 최신 이벤트 정보(GTID=2)를 읽어 slave에게 전송한다.
[Master Thread] - slave 서버는 이 정보들을 relay log에 적어둔다.
[Slave Thread] - slave는 최종 변경사항을 db에 반영한다(commit).
[SQL Thread]
master에게는 데이터 동시성이 아주 높게 요구되는 트랜잭션을 담당하고, slave에게는 데이터 동시성이 꼭 보장될 필요는 없는 경우에 읽기 전용으로 데이터를 가져오게 된다.
master에게는 데이터 동시성이 아주 높게 요구되는 트랜잭션을 담당하고, slave에게는 데이터 동시성이 꼭 보장될 필요는 없는 경우에 읽기 전용으로 데이터를 가져오게 된다.
Query의 대부분은 Select가 차지하고 있다.
이 부분의 부하를 낮추기 위해 많은 Slave를 생성하면 Read(Select) 성능 향상 효과를 얻을 수 있다.
참고 링크

로그를 남기자 〰️