Elasticsearch 입문 공부
Elasticsearch는 Apache Lucene 기반의 Java 오픈소스 분산형 RESTful 검색 및 분석 엔진이다. 방대한 양의 데이터에 대해 실시간으로 저장과 검색 및 분석 등의 작업을 수행할 수 있다. Elasticsearch는 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 검색 및 분석 엔진으로 분산형 및 개방형을 특징으로 한다. Elasticsearch는 JSON 문서로 데이터를 저장할 수 있기 때문이다.
Elasticsearch는 단독 검색을 위해 사용하거나, ELK(Elasticsearch & Logstash & Kibana) 스택을 기반으로 사용한다.
이는 데이터를 행렬 데이터로 저장하는 것이 아니라, JSON 문서로 직렬화된 복잡한 자료 구조를 저장하는 방식을 채택하고 있다.
Elasticsearch는 특정 문장을 입력받으면, 파싱을 통해 문장을 단어 단위로 분리하여 저장한다. 또는 대문자를 소문자로 치환하거나 유사어 체크 등의 추가 작업을 통해 텍스트를 저장한다.
Elasticsearch는 역색인(Inverted Index)이라고 하는 자료 구조를 사용하는데, 이는 전문 검색에 있어서 빠른 성능을 보장한다. 책의 전반부에 위치한 일반적인 목차가 Index라면, 책 후반부에 키워드마다 내용을 찾아볼 수 있도록 돕는 목차가 Inverted Index이다.
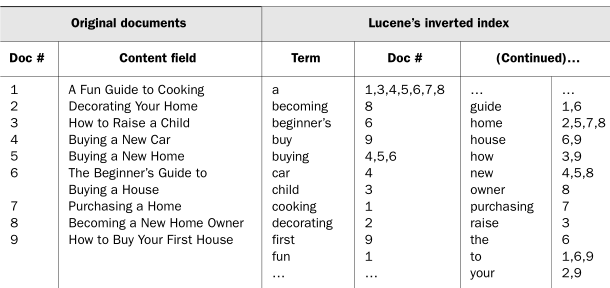
역색인은 각 Document에 등장하는 모든 고유한 단어들을 리스트업하고, 해당 단어들이 등장하는 Document들을 식별한다.
색인(Index)은 최적화된 Document 컬렉션이고, 각 Document는 데이터를 포함하고 있는 Key-Value 쌍으로 이루어진 Field의 컬렉션이다.
Elasticsearch는 모든 Field의 데이터를 인덱싱하는데, 인덱싱된 Field는 각각의 최적화된 자료구조를 사용한다. 텍스트 형식의 Field는 Inverted Index에 저장되며, 숫자 혹은 지리 관련 Field는 BKD 트리에 저장된다.
RDB는 데이터 수정/삭제의 편의성과 속도 면에서 강점이 있지만 다양한 조건의 데이터를 검색하고 집계하는 데에는 구조적인 한계가 존재한다. 특정 단어 검색 시 ROW 개수만큼 확인을 반복하기 때문이다.
반면 단어 기반으로 데이터를 저장하는 Elasticsearch는 특정 단어가 어디에 저장되어 있는지 이미 알고 있어 모든 Document를 검색할 필요가 없다.
반면 수정과 삭제는 내부적으로 굉장히 많은 리소스가 소요되는 작업이라, RDBMS를 대체하기 어렵다.
Elasticsearch 특징
- Scale out: Shard를 통해 규모가 수평적으로 늘어날 수 있다.
- 고가용성: Replica를 통해 데이터의 안정성을 보장하고, 단일 장애점을 극복한다.
- Schema Free: Json 문서를 통해 데이터를 검색하므로, 스키마의 개념이 없다.
- RESTful: CRUD 작업은 RESTful API를 통해 수행되며, 각각이 HTTP의 PUT / GET / POST / DELETE 메서드에 대응된다.
RDBMS와 Elasticsearch 용어 비교
| RDBMS | Elasticsearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | Querydsl |

잘읽고 갑니다. 덕분에 이해했습니다!