
Process Synchronization(프로세스 동기화)
Concurrency Control(병행 제어)라고도 한다.
데이터의 접근
Race Condition 상황을 살펴보기 전
컴퓨터 시스템에서 데이터를 어떻게 접근하는지 보자.

데이터가 저장되어 있는 위치로부터 데이터를 읽어와서 연산한 후, 연산 결과를 이전에 저장되어있던 그 위치에 다시 저장하게 된다.
Execution-Box(E-box)와 Storage-Box(S-box)의 예시를 보면 이해가 될 것이다.
| E-box | S-box |
|---|---|
| CPU | Memory |
| 컴퓨터 내부 | 디스크 |
| 프로세스 | 그 프로세스의 주소 공간 |
데이터를 읽기만 하면 문제가 없는데, 데이터를 수정하게 되면 무엇이 먼저 읽었는지 중요하게 된다.
Race Condition
- Race Condition이란 동시에 여러 개의 프로세스가 동시에 공유 데이터를 접근하는 상황
- 데이터의 최종 연산 결과는 그 데이터를 마지막에 다룬 프로세스에 따라 달라진다. 동시에 접근했더라도 연산의 수행이 더 늦게 끝나는 프로세스의 연산 결과를 따른다.
- ex) 데이터를 가져와 count를 1 증가시키는(
count++) 도중에, 다른 곳에서 그 count를 가져가 1 감소시키면(count--), (count--) 의 결과만 반영된다.
OS에서의 Race Condition
1. kernel 수행 중, 인터럽트 발생 시
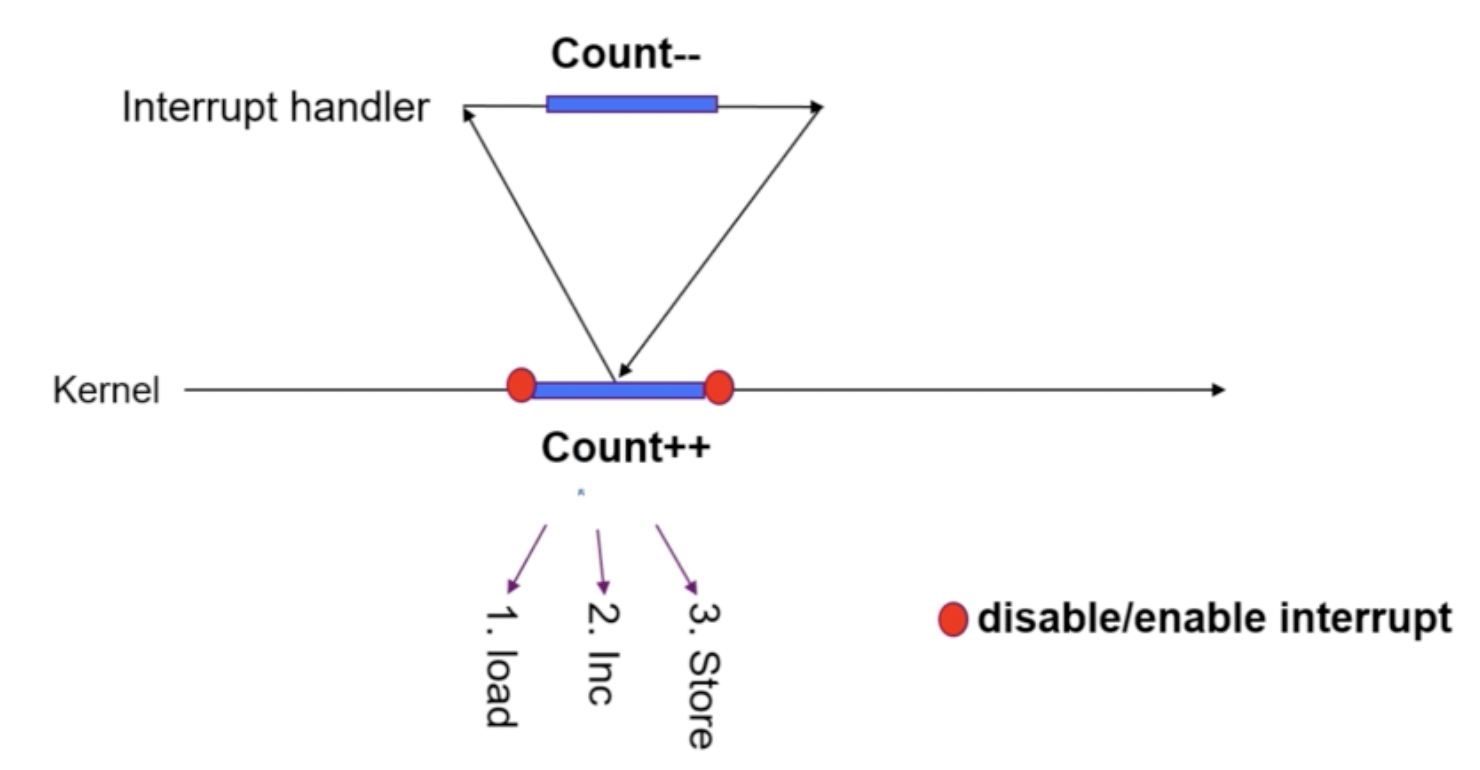 : 커널 모드 running 중 interrupt가 발생하여 인터럽트 처리 루틴이 수행
: 커널 모드 running 중 interrupt가 발생하여 인터럽트 처리 루틴이 수행
-> 양쪽 다 커널 코드이므로 kernel address space 공유
다음 그림을 봤을 때, 논리적으로는 Count 값이 원래 10이었다면 결과도 10이 되어야 한다. 10 -> 9 -> 10 or 10->11->10)하지만 이 연산의 결과는 11이 된다.
과정을 살펴보자.
- load로 데이터를 읽어 온 후 인터럽트 발생한 상태
- Context에 Count = 10을 저장해두고, 인터럽트를 진행한다.
- Interrupt Handler 과정에서
Count--이 되어 Count 값은 9가 될 것이다. - 다시 되돌아오면 Context에 저장된 Count 값을 가져온다 (10) : Interrupt Handler 과정에서 연산한 결과가 무시된다.
Count++수행 Count 값은 11이 된다.
2. Process가 system call을 하여 kernel mode로 수행 중인데, context switch가 일어나는 경우
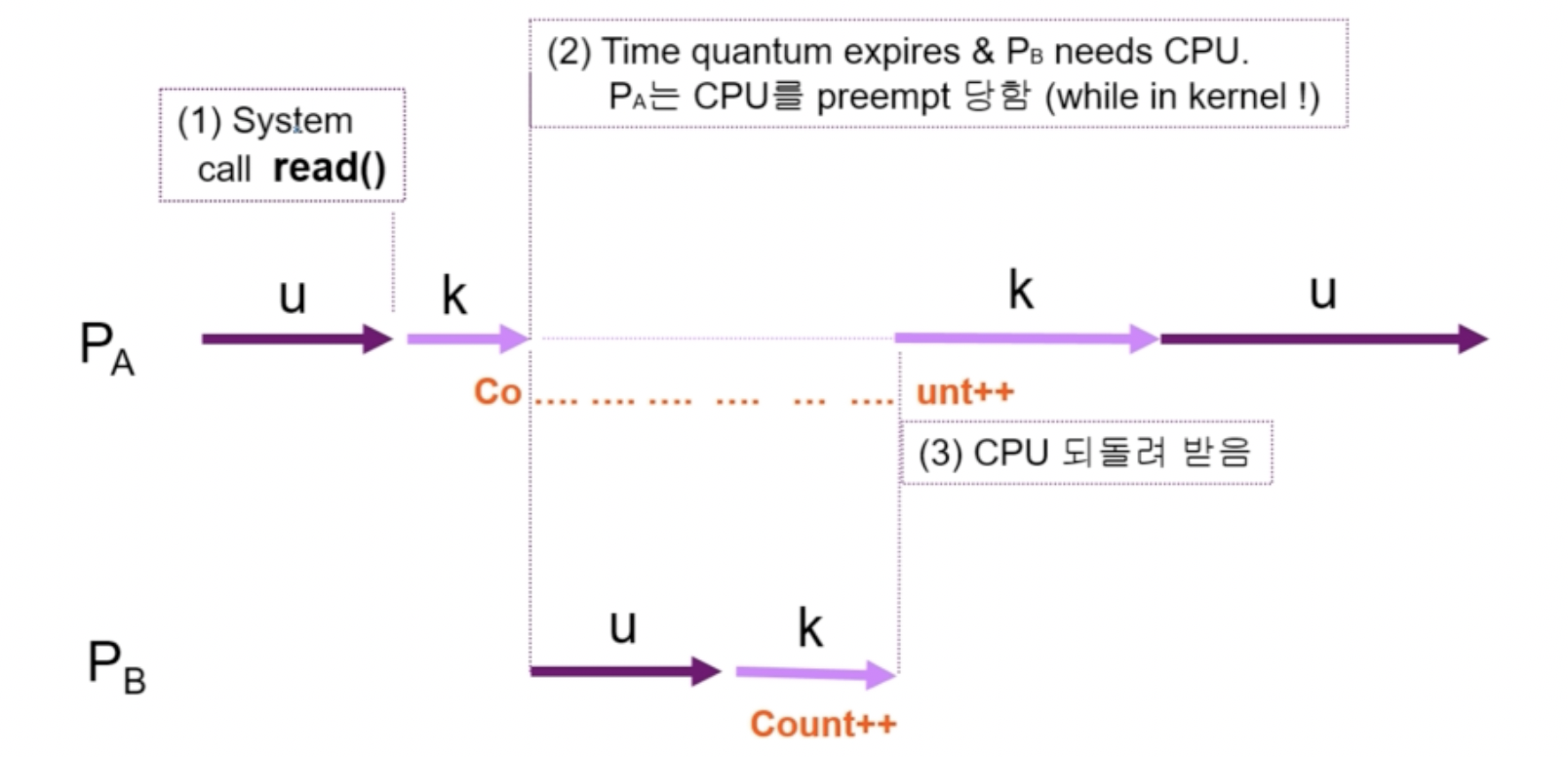
- 두 프로세스의 address space 간에는 data sharing이 없지만, 시스템 콜을 하는 동안에는 kernel address space의 data를 access하게 된다 (share)
- 이 작업 중간에 CPU를 preempt 해가면 race condition이 발생한다.
- 해결책 : 커널 모드에서 수행 중일 때는 CPU를 preempt하지 않는다. 커널 모드에서 사용자 모드로 돌아갈 때 preempt한다.
3. Multiprocessor에서 shared memory 내의 kernel data
어떤 CPU가 마지막으로 count를 store 했는가 -> race condition
멀티프로세서의 경우에는 interrupt enable/disable로 해결되지 않는다.
- 방법 1 : 한 번에 하나의 CPU만이 커널에 들어갈 수 있게 한다 (성능이 떨어지게 된다.)
- 방법 2 : 커널 내부에 있는 각 공유 데이터에 접근할 때마다 그 데이터에 대한 lock/unlock을 한다.
Process Synchronization 문제
- 공유 데이터의 동시 접근(concurrent access)은 데이터의 불일치 문제(inconsistency)를 발생시킬 수 있다.
- 일관성(consistency) 유지를 위해서는 협력 프로세스(cooperating process) 간의 실행 순서(orderly execution)를 정해주는 메커니즘이 필요하다.
- race condition을 막기 위해서는 concurrent process는 동기화되어야 한다.
The Critical-Section Problem
정확히 개념을 이해하자!
각 프로세스의 code segment에는 공유 데이터를 접근하는 코드인 critical section이 존재한다. 공유 데이터를 접근하는 부분을 critical section이라고 한다.
👉 하나의 프로세스가 critical section에 있을 때 다른 모든 프로세스는 critical section에 들어갈 수 없어야 한다.
프로그램적 해결법의 충족 조건
Mutual Exclusion
프로세스 Pi가 critical section 부분을 수행 중이면 다른 모든 프로세스들은 그들의 critical section에 들어가면 안 된다.
Progress
아무도 critical section에 있지 않은 상태에서 critical section에 들어가고자 하는 프로세스가 있으면 critical section에 들어가게 해줘야 한다. (아무도 없을 땐 들어오는 프로세스는 바로 들어가게 해줘야 한다.)
Bounded Waiting
프로세스가 critical section에 들어가려고 요청한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 critical section에 들어가는 횟수에 한계가 있어야 한다. (기다리는 시간이 무한이 되지 않도록 구현해야 한다.)
두 개의 프로세스가 있다고 가정하자 (P0, P1)
- 프로세스들의 일반적인 구조
do { entry section critical section exit sectiojn remainder section } while (1);
- 프로세스들은 수행의 동기화(synchronize)를 위해 몇몇 변수를 공유할 수 있다. (synchronization variable)
소프트웨어적으로 lock을 설정하는 방법
✔️ Algorithm 1
하나의 flag를 사용하는 알고리즘
두 프로세스 P0, P1 있다고 가정하자
Synchronization variable
int turn;
initially turn = 0; // Pi can enter its critical section if (turn == i)Process P0
do {
while (turn != 0); // My turn(turn == 0)이 될 때까지 반복
critical section
turn = 1; // Set P1 trun
remainder section
} while (1);Process P1
do {
while (turn == 0); // My turn(turn != 0)이 될 때까지 반복
critical section
turn = 0; // Set P0 trun
remainder section
} while (1);👎 문제점
이 알고리즘은 Mutual exclusion은 만족하지만,
Progress는 만족하지 않는다.
과잉 양보
- 반드시 한번씩 교대로 들어가야 한다. (swap-turn)
- 상대가 turn을 내 값으로 바꿔줘야만 내가 들어갈 수 있다.
- 특정 프로세스가 더 빈번하게 Critical Section에 들어가야한다면 문제가 생긴다.
ex) 만약 P0의 remainder section 부분이 너무 긴 경우, P1에서 turn 을 0으로 바꾸고 다시 while문을 반복할 때, 아무도 critical section에 수행하고 있는 프로세스가 없는데 Process가 진입을 하지 못한다.
✔️ Algorithm 2
하나의 flag를 사용하는 알고리즘
Synchronization variables
boolean flag[2];
initially flag[all] = false; // no one in CS(Critical Section)
// Pi ready to enter its critical section if (flag[i] == true)Process Pi
do {
flag[i] = true; // Pretend I am in
while (flag[j]); // 상대 프로세스를 기다린다. (false가 될 때까지)
critical section
flag[i] = false; // I am out now
remainder section
} while (1);👎 문제점
Mutual exclusion은 만족하지만, Progress는 만족하지 않는다.
flag[i] = true;까지 수행 후, context switch가 발생하는 경우, 끊임 없이 양보하는 상황이 발생가능하다.
✔️ Algorithm 3(Peterson's Algorithm)
Synchronization variables
Algorithm 1과 2의 synchronization variables를 결합했다.
Process Pi
do {
flag[i] = true; // My intention is to enter (cs에 들어가고 싶다.)
turn = j; // 상대 프로세스 먼저 Set
while (flag[j] && turn == j); // 2개 동시 만족하는 상황일 때만 기다림
critical section
flag[i] = false;
remainder section
} while (1);문제점
이 알고리즘은 Mutual exlusion, Progress, Bounded waiting 모두 충족하지만
Busy Waiting 문제가 있다.
계속 CPU와 memory를 쓰면서 wait한다.
CMP flag
CMP turn
jmp start-> 비효율적
Synchronization Hardware
하드웨어적으로 Test & Modify를 atomic하게 수행할 수 있도록 지원하는 경우 앞의 문제가 간단히 해결된다.
atomic : 하나의 operation인 것처럼 수행한다.
=> 위에서 문제가 생겼던 이유는 데이터를 읽는 것과 데이터를 쓰는 것을 하나의 Instruction으로 처리할 수 없었기 때문에 발생한 것이다.
(Ex. Count++ 연산 => 기계어로는 Load + Inc + Store 3단계로 구성)
// Synchronization variable
boolean lock = false;
// Process Pi
do {
while (Test_and_Set(lock));
critical section
lock = false;
remainder section
}
/*
Test할 때 lock이 false이면, 자기 프로세스 차례 -> lock = true로 Set
-> Test, Set이 하나의 어셈블리 명령어처럼 처리된다.
*/Algorithm 2에서는 context-switch할 때 문제가 발생하는데, 이것은 문제가 생기지 않는다.
하지만 Busy Waiting 문제는 발생한다.
Semaphores
앞의 방식들을 추상화시킴(like oop)
Semaphore S
- integer variable (정수 변수)
- 아래의 두 가지 atomic 연산에 의해서만 접근이 가능하다. (운영체제가 보장해주기 때문에 context switch 문제가 발생하지 않는다.)
// P(S)
while (S <= 0) do no-op; // 아무것도 하지 않는 조건
S--; // S가 0보다 크면 S--
/*
if 양수 : decrement & enter
Otherwise : wait until Positive(busy-wait)
*/
// V(S)
S++;Critical Section of n Processes
- mutex : 상호 배제(mutual exclusion)
// Synchronization variable
semaphore mutex; // initially 1 : 1개가 CS에 들어갈 수 있다.
// Process Pi
do {
P(mutex); // +이면 -- & enter, 아니면 wait
critical section
V(mutex); // Increment semaphore
remainder section
} while (1);운영체제가 2개의 API에 대해 atomic한 연산을 보장해주기 때문에, Algorithm 2의 문제가 발생하지 않는다.
Busy-Wait은 해결하지 못했다.
Block / Wakeup Implementation
Busy Wait보다 더 잘 쓰인다.
Semaphore 정의
typedef struct
{
int value; // semaphore
struct process *L; // process wait queue
} semaphore;- block
- 커널은 block을 호출한 프로세스를 suspend 시킨다.
- 이 프로세스의 PCB를 semaphore에 대한 wait queue에 넣는다.
- wakeup(P)
- block된 프로세스 P를 wakeup 시킨다.
- 이 프로세스의 PCB를 ready queue로 옮긴다.
Semaphore 연산
// P(S)
// wait(suspend) 시킬 수 있음.
S.value--; // cs에 들어갈 준비
if (S.value < 0) // 들어갈 수 없는 조건
{
add this process to S.L; // wait queue에 넣는다.
block(); // suspend
/*
나중에 필요할 때 wake up 하기 때문에
busy wait 상태 X, CPU 낭비 X
*/
}
// V(S)
// wakeup 시킬 수 있음
S.value++;
if (S.value <= 0) // LinkedList(wait queue)에 process가 대기하고 있음을 의미
{
remove a process P from S.L;
wakeup(P);
}Busy Wait VS Block/Wakeup
Block/wakeup overhead vs Critical section 길이
- Critical section의 길이가 긴 경우, Block/Wakeup이 적당하다
- Critical section의 길이가 매우 짧은 경우, Block/Wakeup 오버헤드가 busy-wait 오버헤드보다 더 커질 수 있다.
(Block/Wakeup 방식은 기본적으로 Context Switch가 일어난다.) - 일반적으로는 Block/wakeup 방식이 더 좋다.
Two Types of Semaphores
- Counting semaphore
- 도메인이 0 이상인 임의의 정수값
- 주로 resource counting에 사용
- Binary semaphore(=mutex) (보통 많이 쓰임)
- 0 또는 1 값만 가질 수 있는 semaphore
- 주로 mutual exclusion (lock(P)/unlock(V))에 사용된다
: critical section에는 프로세스 하나만 들어갈 수 있고, 그게 빠져나와야지 다른 프로세스가 들어갈 수 있는 것
Deadlock and Starvation
- Deadlock
- 둘 이상의 프로세스가 서로 상대방에 의해 충족될 수 있는 event를 무한히 기다리는 현상
- Context Switch가 발생했을 경우 생기는 문제를 뜻한다.
- Starvation
- indefinite blocking. 프로세스가 suspend된 이유에 해당하는 세마포어 큐에서 빠져나갈 수 없는 현상
- 교착 상태(Deadlock)이 일어나면 생기는 현상이다.
