
본 글은 Delta Lake 2.2.0 Table utility commands 을 번역 및 정리하였습니다.
Delta 테이블은 여러 유틸리티 명령어를 지원합니다.
Delta Lake 작업에서 많은 경우, 새로운 SparkSession을 생성할 때 configurations을 설정하여 Apache Spark DataSourceV2 및 Catalog API와 통합을 활성화할 수 있습니다 (3.0부터). SparkSession 구성 방법은 Configure SparkSession을 참조하십시오.
Remove files no longer referenced by a Delta table
Delta 테이블에서 더 이상 참조되지 않고 rentention 기준을 충족시키는 파일은 vacuum 명령을 사용하여 제거할 수 있습니다. vacuum는 자동으로 트리거되지 않습니다. 파일의 기본 retention 기준은 7일입니다. 이 동작을 변경하려면 Data retention을 참조하십시오.
💡 중요한 점vacuum 명령은 _로 시작하는 디렉토리를 무시하고 Delta Lake에서 관리하지 않는 디렉토리의 모든 파일을 제거합니다. 만약 Delta table 디렉토리 내에 Structured Streaming checkpoints와 같은 추가적인 메타데이터를 저장하고 있다면, _checkpoints와 같은 디렉토리 이름을 사용해야 합니다.
vacuum 명령은 데이터 파일만을 삭제하며 로그 파일은 삭제하지 않습니다. 로그 파일은 체크포인트 작업 이후에 자동으로 비동기적으로 삭제됩니다. 로그 파일의 기본 보존 기간은 ALTER TABLE SET TBLPROPERTIES SQL 메서드를 사용하여 설정한 delta.logRetentionDuration 속성을 통해 조정할 수 있습니다. Table properties를 참조하세요.
vacuum을 실행한 이후 보존 기간보다 오래된 버전으로 시간여행을 할 수 없게 됩니다.
VACUUM eventsTable -- vacuum files not required by versions older than the default retention period
VACUUM '/data/events' -- vacuum files in path-based table
VACUUM delta.`/data/events/`
VACUUM delta.`/data/events/` RETAIN 100 HOURS -- vacuum files not required by versions more than 100 hours old
VACUUM eventsTable DRY RUN -- do dry run to get the list of files to be deletedfrom delta.tablesimport *
deltaTable = DeltaTable.forPath(spark, pathToTable) # path-based tables, or
deltaTable = DeltaTable.forName(spark, tableName) # Hive metastore-based tables
deltaTable.vacuum() # vacuum files not required by versions older than the default retention period
deltaTable.vacuum(100) # vacuum files not required by versions more than 100 hours oldVACUUM 명령을 사용할 때 파일을 병렬로 삭제하도록 Spark를 구성하려면 세션 구성 "spark.databricks.delta.vacuum.parallelDelete.enabled"를 "true"로 설정하면 됩니다.
Delta Lake API의 Scala, Java 및 Python 구문 세부 정보는 해당 언어의 문서에서 확인하실 수 있습니다.
💡 경고테이블에 대해 동시에 읽기 또는 쓰기 작업을 수행하는 사용자가 존재하는 경우, 오래된 스냅샷 및 커밋되지 않은 파일이 아직 사용 중인 것으로 나타날 수 있습니다. 따라서 VACUUM으로 파일을 청소할 때, 활성 파일을 청소하면 동시 읽기 작업이 실패할 수 있으며 더 나쁜 경우, VACUUM이 아직 커밋되지 않은 파일을 삭제하면 테이블이 손상될 수 있습니다. 따라서 동시 실행 트랜잭션이 가장 긴 시간과 가장 최근 업데이트에서 지연되는 가장 긴 스트림 기간보다 긴 간격을 선택해야 합니다. 적어도 7일 이상의 보존 간격을 설정하는 것이 좋습니다.
Delta Lake는 위험한 VACUUM 명령을 실행하는 것을 방지하기 위한 안전성 검사를 가지고 있습니다. 만약 지정할 보존 기간보다 더 긴 작업이 이 테이블에서 실행되지 않는 것이 확실하다면, Spark 구성 속성 spark.databricks.delta.retentionDurationCheck.enabled를 false로 설정하여 이 안전성 검사를 끌 수 있습니다.
Retrieve Delta table history
Delta 테이블에 대한 각 write에 대한 정보 (연산, 사용자, 타임스탬프 등)를 얻으려면 history 명령을 실행하면 됩니다. 연산은 역시간 순서로 반환됩니다. 기본적으로 테이블 히스토리는 30일간 보관됩니다.
DESCRIBE HISTORY '/data/events/' -- get the full history of the table
DESCRIBE HISTORY delta.`/data/events/`
DESCRIBE HISTORY '/data/events/'LIMIT 1 -- get the last operation only
DESCRIBE HISTORY eventsTablefrom delta.tablesimport *
deltaTable = DeltaTable.forPath(spark, pathToTable)
fullHistoryDF = deltaTable.history() # get the full history of the table
lastOperationDF = deltaTable.history(1) # get the last operationDelta Lake API의 Scala, Java 및 Python 구문 세부 정보는 해당 언어의 문서에서 확인하실 수 있습니다.
History schema
history 작업의 출력 결과는 다음 열을 가집니다.
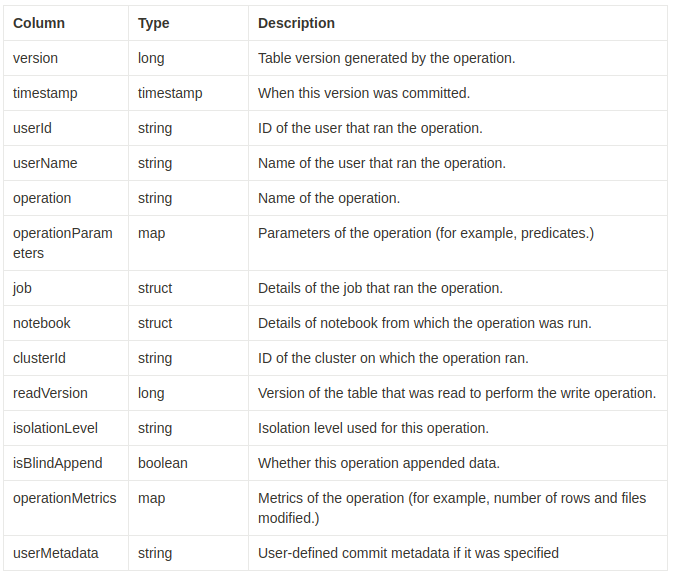
+-------+-------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+--------------------+
|version| timestamp|userId|userName|operation| operationParameters| job|notebook|clusterId|readVersion|isolationLevel|isBlindAppend| operationMetrics|
+-------+-------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+--------------------+
| 5|2019-07-29 14:07:47| null| null| DELETE|[predicate -> ["(...|null| null| null| 4| Serializable| false|[numTotalRows -> ...|
| 4|2019-07-29 14:07:41| null| null| UPDATE|[predicate -> (id...|null| null| null| 3| Serializable| false|[numTotalRows -> ...|
| 3|2019-07-29 14:07:29| null| null| DELETE|[predicate -> ["(...|null| null| null| 2| Serializable| false|[numTotalRows -> ...|
| 2|2019-07-29 14:06:56| null| null| UPDATE|[predicate -> (id...|null| null| null| 1| Serializable| false|[numTotalRows -> ...|
| 1|2019-07-29 14:04:31| null| null| DELETE|[predicate -> ["(...|null| null| null| 0| Serializable| false|[numTotalRows -> ...|
| 0|2019-07-29 14:01:40| null| null| WRITE|[mode -> ErrorIfE...|null| null| null| null| Serializable| true|[numFiles -> 2, n...|
+-------+-------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+--------------------+일부 열은 해당 정보가 환경에서 사용할 수 없기 때문에 널 값이 될 수 있습니다.
앞으로 추가되는 열은 항상 마지막 열 이후에 추가됩니다.
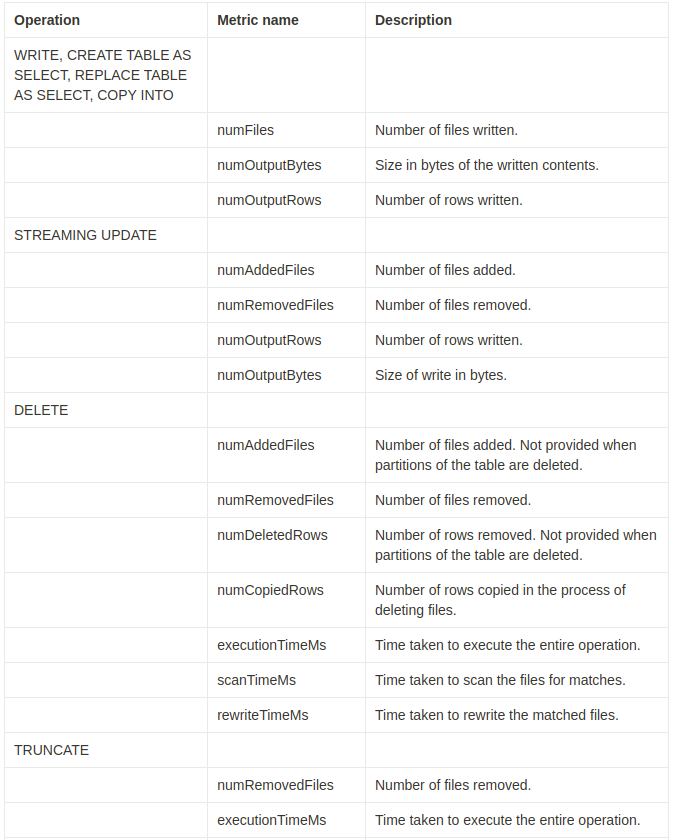
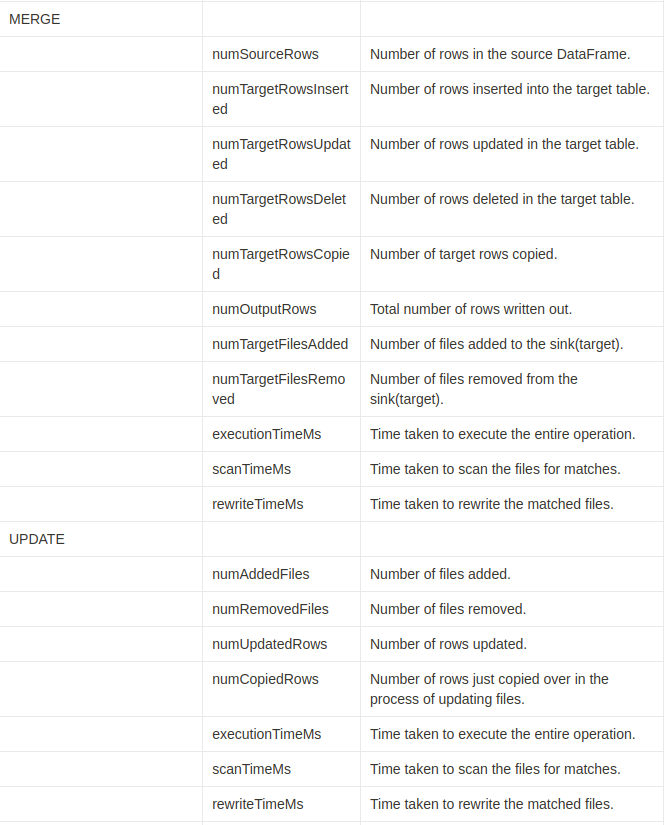
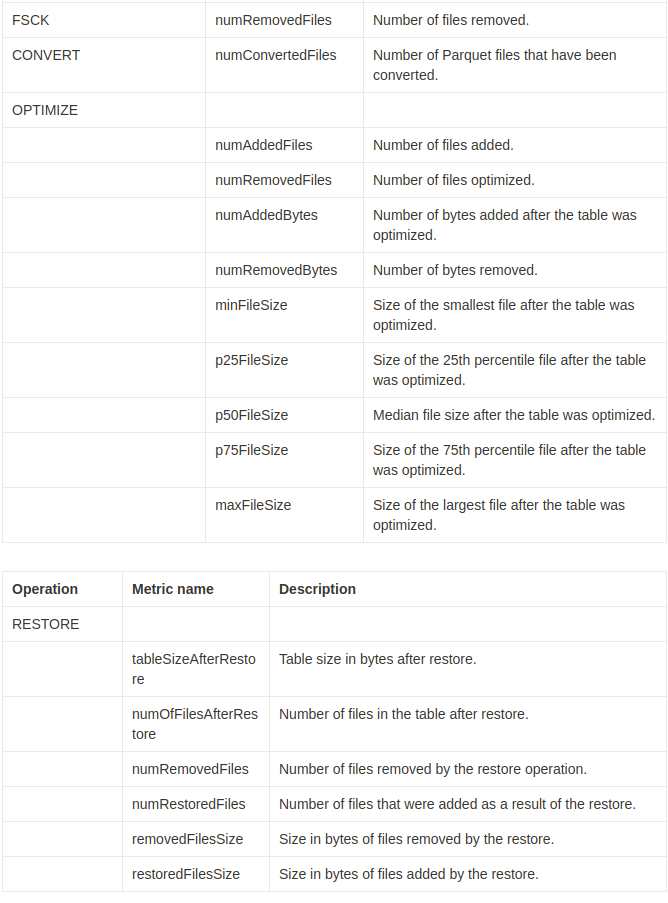
Operation metrics keys
'history' 동작은 operationMetrics 열 맵에서 운영 지표(operation metrics)의 컬렉션을 반환합니다.
다음 표는 운영에 따른 맵 키(key) 정의를 나열합니다.
Retrieve Delta table details
DECRIBE DETAIL를 사용하면 Delta 테이블의 세부 정보 (예: 파일 수, 데이터 크기)를 검색할 수 있습니다.
DESCRIBE DETAIL '/data/events/'
DESCRIBE DETAIL eventsTablefrom delta.tablesimport *
deltaTable = DeltaTable.forPath(spark, pathToTable)
detailDF = deltaTable.detail()Delta Lake API의 Scala, Java 및 Python 구문 세부 정보는 해당 언어의 문서에서 확인하실 수 있습니다.
Detail schema
이 작업의 출력은 다음 스키마를 가진 하나의 행만 가지고 있습니다.
| Column | Type | Description |
|---|---|---|
| format | string | Format of the table, that is, delta. |
| id | string | Unique ID of the table. |
| name | string | Name of the table as defined in the metastore. |
| description | string | Description of the table. |
| location | string | Location of the table. |
| createdAt | timestamp | When the table was created. |
| lastModified | timestamp | When the table was last modified. |
| partitionColumns | array of strings | Names of the partition columns if the table is partitioned. |
| numFiles | long | Number of the files in the latest version of the table. |
| sizeInBytes | int | The size of the latest snapshot of the table in bytes. |
| properties | string-string map | All the properties set for this table. |
| minReaderVersion | int | Minimum version of readers (according to the log protocol) that can read the table. |
| minWriterVersion | int | Minimum version of writers (according to the log protocol) that can write to the table. |
+------+--------------------+------------------+-----------+--------------------+--------------------+-------------------+----------------+--------+-----------+----------+----------------+----------------+
|format| id| name|description| location| createdAt| lastModified|partitionColumns|numFiles|sizeInBytes|properties|minReaderVersion|minWriterVersion|
+------+--------------------+------------------+-----------+--------------------+--------------------+-------------------+----------------+--------+-----------+----------+----------------+----------------+
| delta|d31f82d2-a69f-42e...|default.deltatable| null|file:/Users/tuor/...|2020-06-05 12:20:...|2020-06-05 12:20:20| []| 10| 12345| []| 1| 2|
+------+--------------------+------------------+-----------+--------------------+--------------------+-------------------+----------------+--------+-----------+----------+----------------+----------------+Generate a manifest file
Delta 테이블에 대한 매니페스트 파일을 생성하여 다른 처리 엔진 (즉, Apache Spark가 아닌 다른 엔진)에서 Delta 테이블을 읽을 수 있습니다. 예를 들어, Delta 테이블을 Presto 및 Athena에서 읽을 수 있는 매니페스트 파일을 생성하려면 다음을 실행합니다:
GENERATE symlink_format_manifest FOR TABLE delta.`<path-to-delta-table>`deltaTable = DeltaTable.forPath(<path-to-delta-table>)
deltaTable.generate("symlink_format_manifest")Convert a Parquet table to a Delta table
이 명령을 사용하면 Parquet 테이블을 Delta 테이블로 바꿀 수 있습니다. 이 명령은 디렉토리의 모든 파일을 나열하고 이러한 파일을 추적하는 Delta Lake 트랜잭션 로그를 생성하며 모든 Parquet 파일의 푸터를 읽어 데이터 스키마를 자동으로 추론합니다. 데이터가 파티셔닝된 경우 파티션 열의 스키마를 DDL 형식의 문자열( , , ...)로 지정해야 합니다.
이 명령은 기본적으로 파일당 통계 정보(예: 각 열의 최소값 및 최대값)를 수집합니다. 이 통계 정보는 쿼리 시간에 더 빠른 쿼리를 제공하기 위해 사용됩니다. SQL API에서 NO STATISTICS를 사용하여 이 통계 정보 수집을 비활성화할 수 있습니다.
💡 참고:Structured Streaming에 의해 생성된 Parquet 테이블의 경우, spark.databricks.delta.convert.useMetadataLog SQL 구성을 true로 설정하여 테이블에 포함된 파일의 근원을 나타내는 _spark_metadata 하위 디렉토리를 사용하여 파일 목록 작성을 회피할 수 있습니다.
-- Convert unpartitioned Parquet table at path '<path-to-table>'
CONVERTTO DELTA parquet.`<path-to-table>`
-- Convert unpartitioned Parquet table and disable statistics collection
CONVERTTO DELTA parquet.`<path-to-table>`NOSTATISTICS-- Convert partitioned Parquet table at path '<path-to-table>' and partitioned by integer columns named 'part' and 'part2'
CONVERTTO DELTA parquet.`<path-to-table>` PARTITIONEDBY (part int, part2 int)
-- Convert partitioned Parquet table and disable statistics collection
CONVERTTO DELTA parquet.`<path-to-table>`NOSTATISTICS PARTITIONEDBY (part int, part2 int)from delta.tablesimport *
# Convert unpartitioned Parquet table at path '<path-to-table>'
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`<path-to-table>`")
# Convert partitioned parquet table at path '<path-to-table>' and partitioned by integer column named 'part'
partitionedDeltaTable = DeltaTable.convertToDelta(spark, "parquet.`<path-to-table>`", "part int")Delta Lake에 추적되지 않는 파일은 보이지 않으며, vacuum을 실행할 때 삭제할 수 있습니다. 변환 과정에서 데이터 파일을 업데이트하거나 추가하는 것을 피해야 합니다. 테이블을 변환한 후에는 모든 쓰기 작업이 Delta Lake를 통해 이루어지도록 해야 합니다.
Convert a Delta table to a Parquet table
다음 단계를 수행하여 Delta 테이블을 쉽게 Parquet 테이블로 변환할 수 있습니다.
- 데이터 파일을 변경할 수 있는 Delta Lake 작업(예: 삭제 또는 병합)을 수행한 경우, 0 시간의 보존 기간으로 vacuum을 실행하여 테이블의 최신 버전에 속하지 않는 모든 데이터 파일을 삭제합니다.
- 테이블 디렉터리의 _delta_log 디렉터리를 삭제합니다.
Restore a Delta table to an earlier state
Delta 테이블은 내부적으로 히스토릭 버전을 유지하며, 이를 사용하여 이전 상태로 복원할 수 있습니다. RESTORE 명령을 사용하여 이전 상태로 복원할 수 있으며, 이전 상태에 해당하는 버전 또는 이전 상태가 생성된 타임스탬프를 옵션으로 지정할 수 있습니다.
💡 중요이미 복원된 테이블을 다시 복원할 수 있습니다.
수동으로 또는 VACUUM으로 데이터 파일을 삭제한 이전 버전으로 테이블을 복원하면 실패합니다. spark.sql.files.ignoreMissingFiles가 true로 설정된 경우에는 이전 버전으로 일부 복원하는 것이 여전히 가능합니다.
이전 상태로 복원하는 경우 타임스탬프 형식은 yyyy-MM-dd HH:mm:ss입니다. 날짜(yyyy-MM-dd) 문자열만 제공하는 것도 지원됩니다.
RESTORETABLE db.target_tableTOVERSIONASOF <version>
RESTORETABLE delta.`/data/target/`TOTIMESTAMPASOF <timestamp>from delta.tablesimport *
deltaTable = DeltaTable.forPath(spark, <path-to-table>) # path-based tables, or
deltaTable = DeltaTable.forName(spark, <table-name>) # Hive metastore-based tables
deltaTable.restoreToVersion(0) # restore table to oldest version
deltaTable.restoreToTimestamp('2019-02-14') # restore to a specific timestamp복원(RESTORE)은 데이터 변경 작업으로 간주됩니다. RESTORE 명령어에 의해 Delta Lake 로그 항목에 dataChange가 true로 설정됩니다. Delta Lake 테이블의 업데이트를 처리하는 Structured Streaming 작업과 같은 하류 애플리케이션이 있는 경우, 복원 작업에 의해 추가된 데이터 변경 로그 항목은 새로운 데이터 업데이트로 간주되어 중복 데이터가 발생할 수 있습니다.
예를 들어:
| Table version | Operation | Delta log updates | Records in data change log updates |
|---|---|---|---|
| 0 | INSERT | AddFile(/path/to/file-1, dataChange = true) | (name = Viktor, age = 29, (name = George, age = 55) |
| 1 | INSERT | AddFile(/path/to/file-2, dataChange = true) | (name = George, age = 39) |
| 2 | OPTIMIZE | AddFile(/path/to/file-3, dataChange = false), RemoveFile(/path/to/file-1), RemoveFile(/path/to/file-2) | (No records as Optimize compaction does not change the data in the table) |
| 3 | RESTORE(version=1) | RemoveFile(/path/to/file-3), AddFile(/path/to/file-1, dataChange = true), AddFile(/path/to/file-2, dataChange = true) | (name = Viktor, age = 29), (name = George, age = 55), (name = George, age = 39) |
이전 예제에서 RESTORE 명령은 Delta 테이블 버전 0 및 1을 읽을 때 이미 본 업데이트를 가져옵니다. 이 테이블을 읽는 스트리밍 쿼리가 있다면 이 파일은 새롭게 추가된 데이터로 간주되어 다시 처리됩니다.
Restore metrics
RESTORE 명령은 작업이 완료된 후 다음과 같은 지표를 담은 단일 로우 데이터프레임을 보고합니다:
- table_size_after_restore: 복원 후 테이블 크기
- num_of_files_after_restore: 복원 후 테이블의 파일 수
- num_removed_files: 테이블에서 삭제(논리적 삭제)된 파일 수
- num_restored_files: 롤백으로 복원된 파일 수
- removed_files_size: 테이블에서 삭제된 파일의 총 크기 (바이트 단위)
- restored_files_size: 복원된 파일의 총 크기 (바이트 단위)

