
본 글은 Delta Lake 2.2.0 Change data feed 을 번역 및 정리하였습니다.
💡 이 기능은 Delta Lake 2.0.0 이상에서 사용할 수 있습니다. 이 기능은 실험적인 지원 모드에 있습니다.Change Data Feed (CDF) 기능은 Delta 테이블이 버전 간에 행 수준 변경을 추적할 수 있게 합니다. Delta 테이블에서 이 기능을 활성화하면 런타임은 테이블에 쓰여진 모든 데이터에 대해 "변경 이벤트"를 기록합니다. 이는 행 데이터와 함께 해당 행이 삽입, 삭제 또는 업데이트되었는지를 나타내는 메타데이터를 포함합니다.
변경 이벤트를 배치 쿼리에서 DataFrame API(df.read)를 사용하여 읽을 수 있으며, DataFrame API(df.readStream)를 사용하여 스트리밍 쿼리에서도 읽을 수 있습니다.
Use cases
변경 데이터 피드는 기본적으로 활성화되지 않습니다. 다음과 같은 사용 사례에서 변경 데이터 피드를 활성화해야 합니다.
- Silver and Gold tables(Silver 및 Gold 테이블): 초기 MERGE, UPDATE 또는 DELETE 작업에 따라 행 수준 변경 사항만 처리하여 ETL 및 ELT 작업을 가속화하고 단순화하여 Delta 성능을 향상시킵니다.
- Transmit changes(변경 사항 전송): 변경 데이터 피드를 Kafka 또는 RDBMS와 같은 하위 시스템에 전송하여 데이터 파이프 라인의 나중 단계에서 점진적으로 처리할 수 있습니다.
- Audit trail table(감사 추적 테이블): Delta 테이블로 변경 데이터 피드를 캡처하면 영구적인 저장소를 제공하며 삭제가 발생한 시점과 업데이트된 내용을 포함하여 시간 경과에 따른 모든 변경 사항을 효율적으로 조회할 수 있습니다.
Enable change data feed
변경 데이터 피드(Change Data Feed) 옵션은 다음 중 하나의 방법을 사용하여 명시적으로 활성화해야 합니다:
- New table(새 테이블): CREATE TABLE 명령에서 테이블 속성 delta.enableChangeDataFeed = true를 설정합니다.
CREATE TABLE student (id INT, name STRING, age INT) TBLPROPERTIES (delta.enableChangeDataFeed = true)- Existing table(기존 테이블) : ALTER TABLE 명령에서 delta.enableChangeDataFeed 속성을 true로 설정합니다.
ALTER TABLE myDeltaTable SET TBLPROPERTIES (delta.enableChangeDataFeed = true)- All new tables
set spark.databricks.delta.properties.defaults.enableChangeDataFeed = true;한번 테이블에 대해 변경 데이터 피드 옵션을 활성화하면 Delta Lake 1.2.1 이하 버전으로 테이블에 쓸 수 없게됩니다. 테이블을 읽을 수는 있습니다.
변경 데이터 피드를 활성화한 후에만 변경 사항이 기록됩니다. 테이블의 이전 변경 내역은 기록되지 않습니다.
Change data storage
Delta Lake는 UPDATE, DELETE 및 MERGE 작업에 대한 변경 데이터를 Delta 테이블 디렉터리 아래의 _change_data 폴더에 기록합니다. Delta Lake가 트랜잭션 로그에서 변경 데이터 피드를 효율적으로 계산할 수 있는 경우 이러한 레코드를 건너뛸 수 있습니다. 특히, insert-only 작업과 전체 파티션 삭제는 _change_data 디렉터리에 데이터를 생성하지 않습니다.
_change_data 폴더의 파일은 테이블의 유지 보수 정책을 따릅니다. 따라서 VACUUM 명령을 실행하면 변경 데이터 피드 데이터도 삭제됩니다.
Read changes in batch queries
시작점과 끝점에 대해 버전 또는 타임스탬프를 제공할 수 있습니다. 쿼리에서 시작 버전과 끝 버전, 시작 타임스탬프와 종료 타임스탬프는 모두 포함됩니다. 특정 시작 버전에서 테이블의 최신 버전까지의 변경 사항을 읽으려면 시작 버전 또는 타임스탬프만 지정하면 됩니다.
버전은 정수로, 타임스탬프는 yyyy-MM-dd[ HH:mm:ss[.SSS]] 형식의 문자열로 지정합니다.
변경 데이터 피드가 활성화된 이후 기록된 변경 이벤트보다 버전이 낮거나 타임스탬프가 오래된 경우, 즉 변경 데이터 피드가 활성화되지 않은 경우 오류가 발생하여 변경 데이터 피드가 활성화되지 않았다는 메시지가 표시됩니다.
# version as ints or longs
spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion", 0) \
.option("endingVersion", 10) \
.table("myDeltaTable")
# timestamps as formatted timestamp
spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingTimestamp", '2021-04-21 05:45:46') \
.option("endingTimestamp", '2021-05-21 12:00:00') \
.table("myDeltaTable")
# providing only the startingVersion/timestamp
spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion", 0) \
.table("myDeltaTable")
# path based tables
spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingTimestamp", '2021-04-21 05:45:46') \
.load("pathToMyDeltaTable")Read changes in streaming queries
# providing a starting version
spark.readStream.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion", 0) \
.table("myDeltaTable")
# providing a starting timestamp
spark.readStream.format("delta") \
.option("readChangeFeed", "true") \
.option("startingTimestamp", "2021-04-21 05:35:43") \
.load("/pathToMyDeltaTable")
# not providing a starting version/timestamp will result in the latest snapshot being fetched first
spark.readStream.format("delta") \
.option("readChangeFeed", "true") \
.table("myDeltaTable")변경 데이터를 읽으려면 readChangeFeed 옵션을 true로 설정하십시오. startingVersion 또는 startingTimestamp는 선택 사항입니다. 제공하지 않으면 스트림은 최신 스냅샷을 INSERT로 반환하고 변경 사항은 변경 데이터로 반환됩니다. 변경 데이터를 읽을 때 rate limits (maxFilesPerTrigger
, maxBytesPerTrigger)및 excludeRegex와 같은 옵션도 지원됩니다.
기본적으로 사용자가 테이블에서 마지막 커밋을 초과하는 버전이나 타임스탬프를 전달하면, timestampGreaterThanLatestCommit 오류가 발생합니다. 그러나 사용자가 다음 구성을 true로 설정하면 CDF는 범위를 벗어난 버전 케이스를 처리할 수 있습니다.
set spark.databricks.delta.changeDataFeed.timestampOutOfRange.enabled = true;만약 테이블의 마지막 커밋보다 더 큰 시작 버전이나 더 최근 커밋보다 더 최근의 시작 타임스탬프를 제공하는 경우, 이전 구성이 활성화되면 빈 읽기 결과가 반환됩니다.
끝 버전이 테이블의 마지막 커밋보다 크거나 끝 타임스탬프가 테이블의 마지막 커밋보다 최근인 경우, 이전 구성이 일괄 읽기 모드에서 활성화되면 시작 버전과 마지막 커밋 사이의 모든 변경 사항이 반환됩니다.
Change data event schema
데이터 열 외에도, 변경 데이터에는 변경 이벤트 유형을 식별하는 메타데이터 열이 포함됩니다.
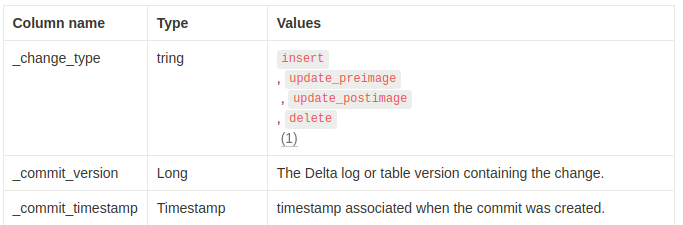
(1) preimage는 업데이트 전의 값이며, postimage는 업데이트 후의 값입니다.
Frequently asked questions (FAQ)
change data feed 기능을 활성화하는 것의 오버헤드는 어떻게 되나요?
상당한 영향은 없습니다. 변경 데이터 레코드는 쿼리 실행 과정에서 생성되며, 전체 파일의 총 크기보다 훨씬 작습니다.
변경 레코드의 보관 기간은 어떻게 되나요?
변경 레코드는 구식 테이블 버전과 동일한 보관 기간을 따르며, 지정된 보관 기간을 벗어나면 VACUUM을 통해 삭제됩니다.
새 레코드가 변경 데이터 피드에서 언제 사용 가능해지나요?
변경 데이터는 Delta Lake 트랜잭션과 함께 커밋되며, 새 데이터가 테이블에서 사용 가능한 것과 동시에 사용 가능해집니다.
알려진 제한 사항
Delta Lake 2.0.0에서 열 매핑이 활성화된 테이블에 대한 CDF 읽기는 배치 및 스트리밍 모두 명시적으로 차단됩니다. Delta Lake 2.1.0에서는 DROP COLUMN 및 RENAME COLUMN이 사용되지 않은 열 매핑이 활성화된 테이블에서 CDF 배치 읽기가 지원됩니다.
