LG Aimers 해커톤을 준비할 때 사용한 train데이터가 이게 실제 공정에서 사용된 데이터이다 보니 품질에 적합한 데이터가 훨씬 많고 품질에 부적합한 데이터가 비교적 적게 분포되어있었다. 즉 레이블 분포가 불균형했던 것. 이를 해결할 수 있는 방법을 찾아보다가 알게 된 방식이 바로 오버 샘플링이었다.
오버 샘플링은?
: 낮은 비율을 가진 클래스 데이터 수를 늘려 불균형을 해소하는 아이디어
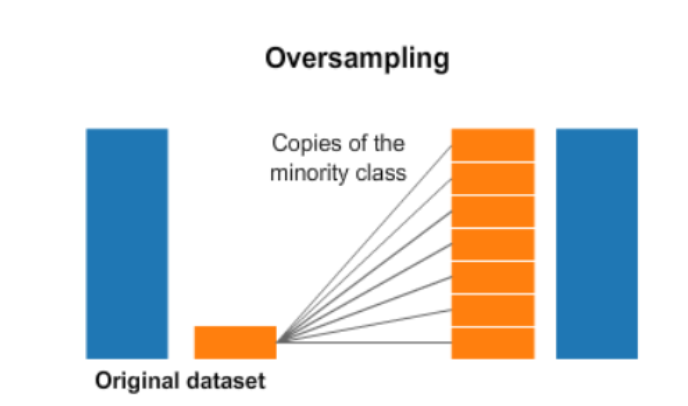
이렇게 데이터 수를 늘리는 거에도 KNN 알고리즘이 활용되어 부족한 데이터를 늘릴 수 있다.
파이썬에서는 SMOTE 패키지를 이용해 사용할 수 있다.
활용 예시 코드 : https://github.com/azzbc7819/test_igaimers/blob/develop/XGBoost_sample.ipynb
