랜덤 포레스트는 수업시간에도 많이 배웠지만 LG Aimers 해커톤을 준비하면서 좀 더 공부하게 된 모델이다.
랜덤 포레스트는 기존에 있던 머신러닝 모델 '의사결정 리'를 여러 개 만들어 분류 결과를 취합하여 예측값을 결정하는 앙상블 머신러닝 모델이다.
배깅에 랜덤 과정을 추가한 방법으로 트리를 형성해가는 과정은 train데이터에서 부트스트랩하여 각 부트스트랩한 데이터들에 맞게 의사결정트리를 만들어 배깅과 비슷하다. 그리고 각 트리들이 어떤 변수를 보고 예측할지 랜덤하게 추출한다.
그렇다면 의사결정트리는?
- 특정 규칙을 트리 구조로 나타내어 전체 데이터를 몇 개의 소집단으로 분류하고 새로운 데이터에 대한 예측을 수행하는 분석 방법
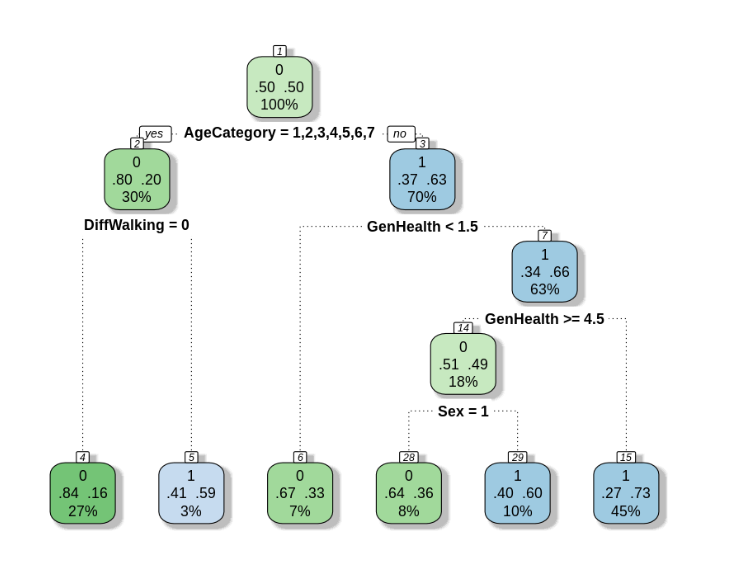
위 그림과 같은 구조가 의사결정트리이며 이러한 트리를 여러 개 만들어 결과를 취합하여 예측값을 결정하는 모델이 바로 랜덤포레스트이다.
랜덤포레스트의 성능을 높이기 위해 수정할 수 있는 파라미터는 다양하다. 파이썬에서 sklearn에서 randomforest를 사용할 때 변경할 수 있는 파라미터들을 보자.
- n_estimators : 모델에서 사용할 트리 갯수(학습시 생성할 트리 갯수)
- criterion : 분할 품질을 측정하는 기능 (default : gini)
- max_depth : 트리의 최대 깊이
- min_samples_split : 내부 노드를 분할하는데 필요한 최소 샘플 수 (default : 2)
- min_samples_leaf : 리프 노드에 있어야 할 최소 샘플 수 (default : 1)
- min_weight_fraction_leaf : min_sample_leaf와 같지만 가중치가 부여된 샘플 수에서의 비율
- max_features : 각 노드에서 분할에 사용할 특징의 최대 수
- max_leaf_nodes : 리프 노드의 최대수
- min_impurity_decrease : 최소 불순도
- min_impurity_split : 나무 성장을 멈추기 위한 임계치
- bootstrap : 부트스트랩(중복허용 샘플링) 사용 여부
- oob_score : 일반화 정확도를 줄이기 위해 밖의 샘플 사용 여부
- n_jobs :적합성과 예측성을 위해 병렬로 실행할 작업 수
- random_state : 난수 seed 설정
- verbose : 실행 과정 출력 여부
- warm_start : 이전 호출의 솔루션을 재사용하여 합계에 더 많은 견적가를 추가
- class_weight : 클래스 가중치
출처:https://inuplace.tistory.com/570
주어진 데이터의 특성에 따라 해당 파라미터들을 적절하게 수정하여 사용할 수 있다.
