1. Overview
- Image segmentation에서 매우 활용도가 높은 네트워크이다.
- 의료영상 인식 쪽에서 top conference인 MICCAI에서 2015년도에 발표되었다.
- 나온지 꽤 되었으나 Image Segmentation 분야에서 baseline이 되어 기본적이면서도 좋은 구조를 제안함.
- U-Net: Convolutional Networks for Biomedical Image Segmentation
2. Background knowledge
이미지 내에서 사물을 인식하는 방법에는 다양한 유형이 존재한다.
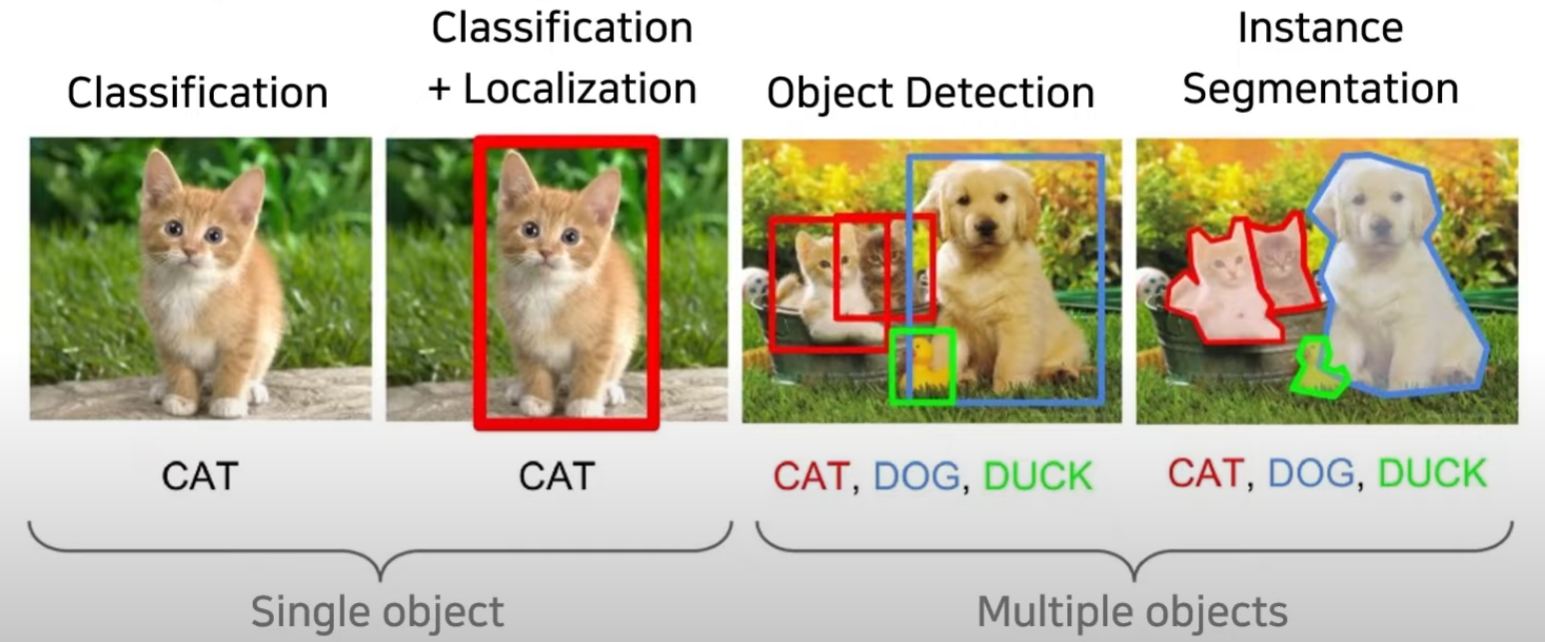
(https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852)
2.1. Classification
한 장의 이미지가 주어졌을 때 어떤 class에 해당하는지 하나의 class로 분류 하는 것
2.2. Localization
정확히 해당 객체가 어디에 있는지 예측하는 것
2.3. Object Detection
여러개의 객체가 존재할 수 있는 상황에서 각 객체마다 Classification과 Localization을 같이 수행하는 것
2.4. Instance Segmentation
여러개의 객체가 존재할 수 있는 상황에서 각 Object를 Pixel단위로 예측하는 것
- 해당 pixel이 어떤 class인지
Segmentation은 각 픽셀마다 클래스(class)를 할당하는 작업을 의미한다.
2.5. Semantic Segmentation
이미지 내에 있는 각 물체(object)들을 의미 있는(semantic) 단위로 분할(segmentation)하는 작업을 의미한다.
- 일반적으로 classification에서는 single image를 하나의 class로 classification했다.
- Segmentation에서는 각 pixel마다 하나의 class로 분류한다.
https://www.jeremyjordan.me/semantic-segmentation/
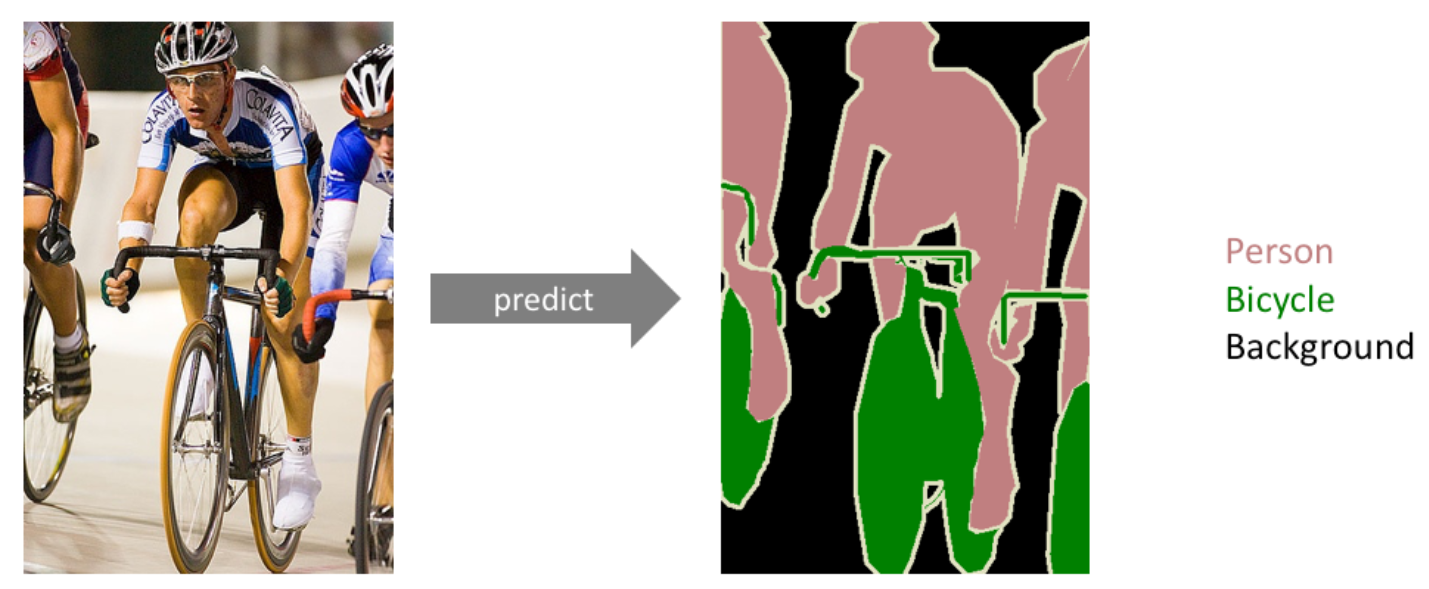
An example of semantic segmentation, where the goal is to predict class labels for each pixel in the image. -> 각 픽셀 포인트 하나하나 마다 클래스를 예측하는 것
2.5.1. goal of Semantic Segmentation
이미지가 주어졌을 때, (height x width x 1(channel)) 크기를 가지는 한 장의 분할 맵(segmentation map)을 생성한다.
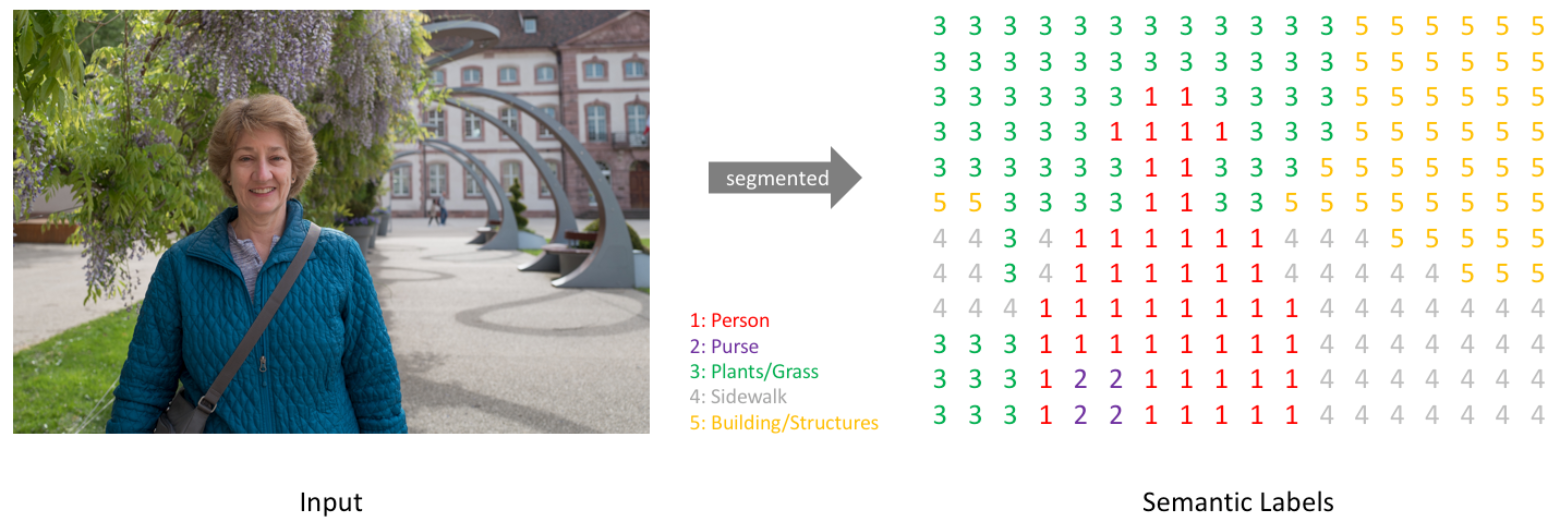
- 각 픽셀마다 N개의 클래스에 대한 확률(probability)를 뱉어야 하므로, 정답은(height x width x N)형태를 갖는다.
- 각 픽셀마다 one-hot encoding 형식을 따른다.
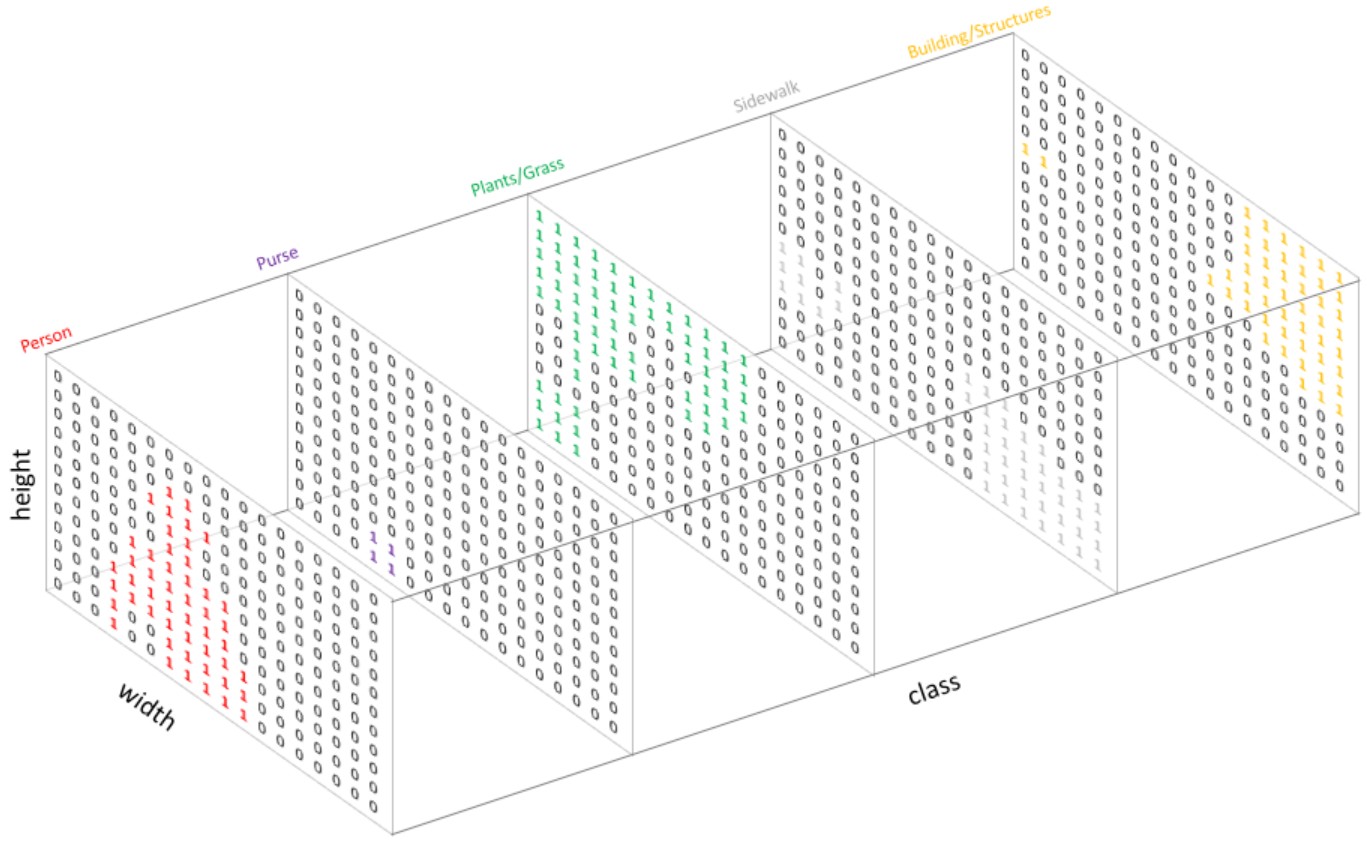
- 각 픽셀마다 one-hot encoding 형식을 따른다.
2.5.2 Semantic Segmentation 모델 학습
- Segmentation 작업을 위한 데이터 세트 생성 비용은 매우 비싸다.
- 각 픽셀마다 어떤 클래스로 분류되는지 일일이 지정해야 하기 때문이다.
- 하지만 일반적인 CNN 분류 모델의 형식을 크게 바꾸지 않고 학습할 수 있다.
- 일반적으로 DL network의 구조가 크게 어렵지 않은 편이라는 장점이 있다.
- 예를 들어 object detection 분야의 network 구조가 대개 더 복잡한 편이다.
2.6. CNN
2.6.1. CNN의 동작 과정
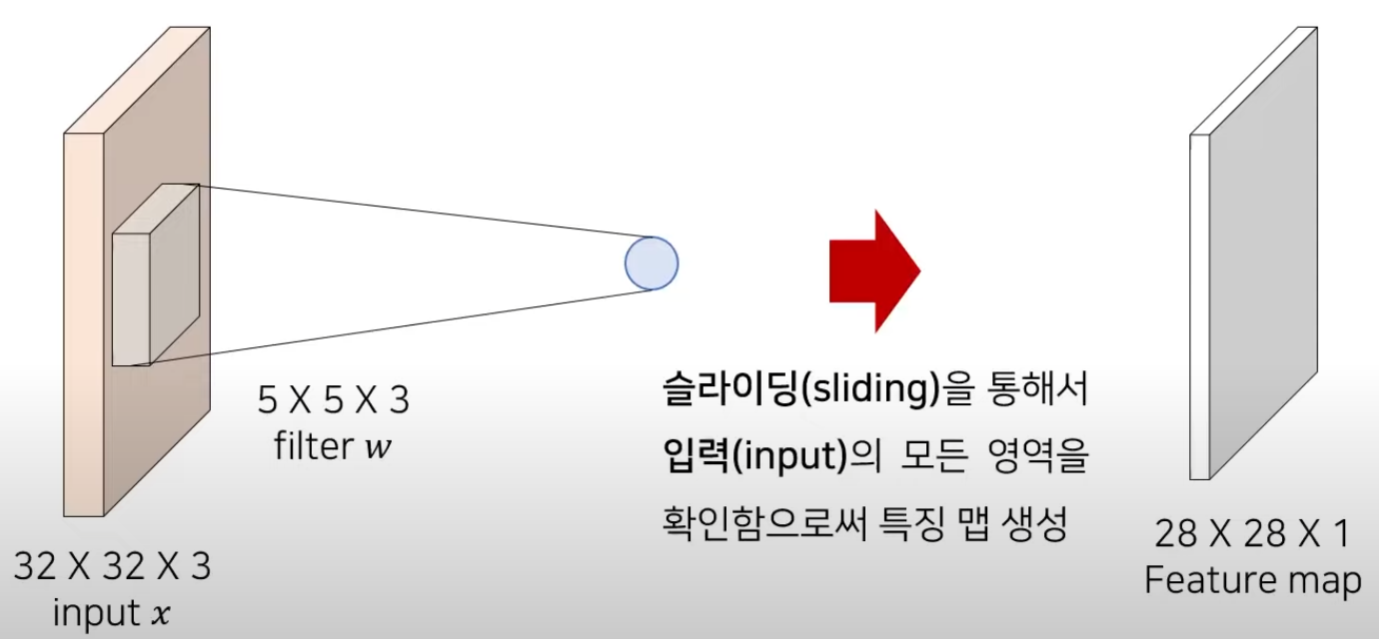
CNN에서는 Filter or Kernel 이라고 불리는 것을 사용한다.
각 필터는 입력에서 특정한 feature를 잡아내어 feature map을 생성한다.
filter는 하나의 특징에 초점을 맞추어 input을 전반적으로 스캔해가며 feature map을 뽑아내는 것이다.
하나의 필터는 슬라이딩 하면서 convolution 연산을 통해 feature map을 계산한다.
input과 filter의 channel은 같아야함.
입력 이미지의 로컬 영역과 filter 사이에서 내적(dot product)를 계산해 각 위치의 결과를 구한다.
Conv 연산은 해당 영역을 Vector로 만들 수 있다면 사실상 Vector의 내적을 하는 것과 마찬가지의 연산이다!!
- 동일한 위치에 대해서 각각 곱셈을 수행해서 그 합을 구하는 것과 마찬가지
각 위치에서의 Conv 연산 결과를 모아서 feature map을 생성- padding을 넣지 않는다면 해상도가 줄어 든다.
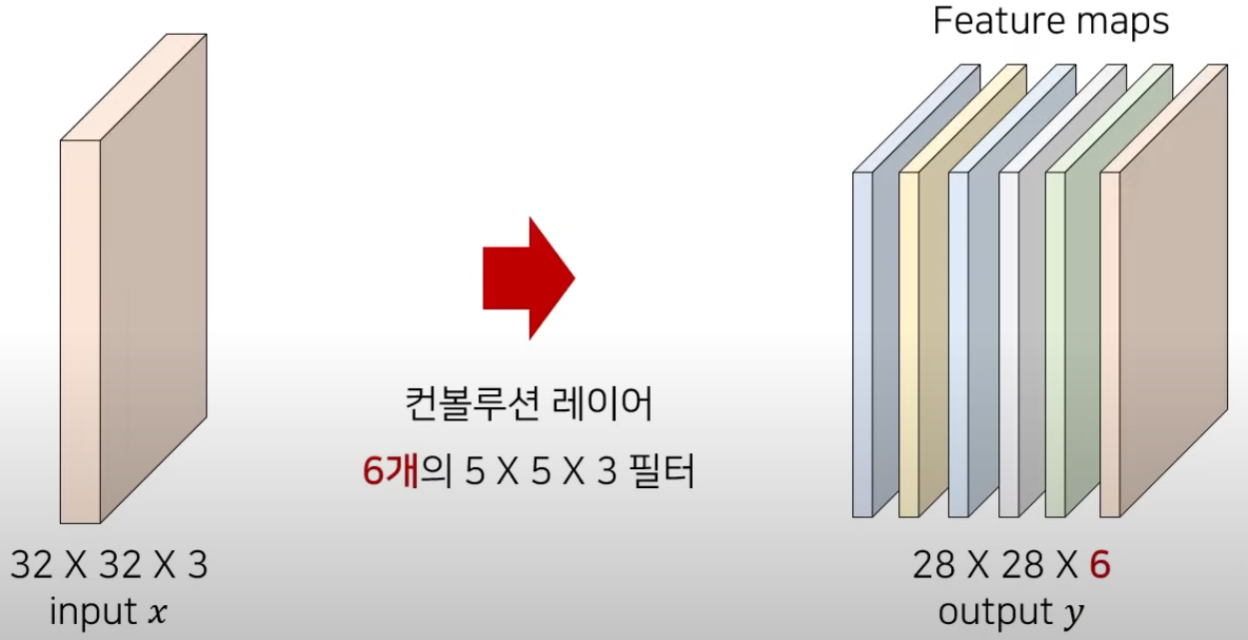
6개의 개별적인 filter를 가진 Conv layer를 이용하면 위와 같다. (filter 개별적으로 input tensor에 대해 적용되기 때문이다)
output tensor의 channel size 는 filter의 개수와 동일하다.
실제 CNN Layer는 여러 번 중첩되어 사용될 수 있다.기본적으로 Conv layer를 깊게 쌓아서 DL model을 만들게 되면 일반적으로 뒷 쪽으로 가면 갈 수록 filter의 개수는 커지고, width, height는 작아지고 channel은 커지게 구성하는 경우가 많다.

2.6.2. CNN의 Feature Maps
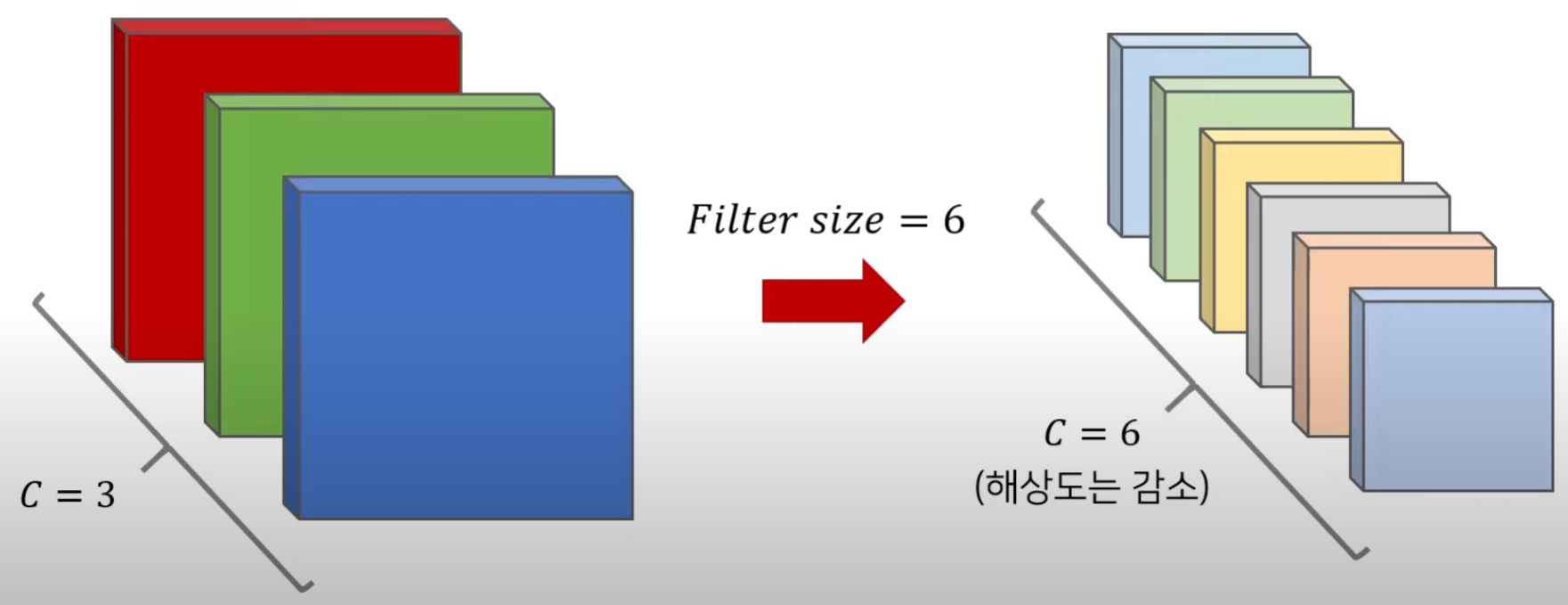
- 일반적으로 CNN classification model에서 깊은 layer로 갈수록 channel 증가, width, height는 감소
- Resnet, VGG는 위의 구조를 따름
- Conv layer의 서로 다른 filter들은 각각 적절한 feature 값을 추출하도록 학습된다.
- 각각의 filter는 각각의 특징들은 추출하는 것이 목적이므로 output인 activation map들은 서로 다른 특징의 결과로 이해할 수 있다.
- 각각의 filter는 각각의 특징들은 추출하는 것이 목적이므로 output인 activation map들은 서로 다른 특징의 결과로 이해할 수 있다.
2.6.3. Max Pooling
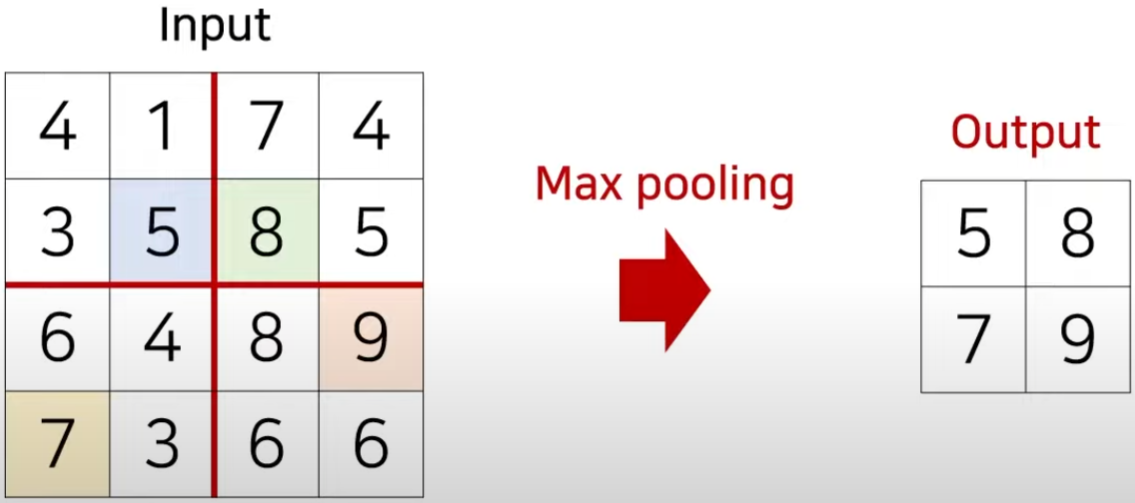
CNN classification model에서 중요한 정보는 유지한 상태로 해상도를 감소시키는 방법으로 Max pooling을 많이 사용한다.
- 처리해야하는 데이터의 차원을 효과적으로 줄일 수 있다.
가장 큰 값을 가지는 원소(element)만 남긴다.
2.6.4. Feature Maps

Visualizing and Understanding Convolutional Networks(ECCV 2014)
CNN의 각 filter는 특정한 feature를 인식하기 위한 목적으로 사용된다.
- 각 filter는 특징이 반영된 feature map을 생성한다.
얕은 층에서는 local feature, 깊은 층에서는 고차원적인 global feature를 인식하는 경향이 있다.
2.6.5. VGGNet (ICLR 2015)
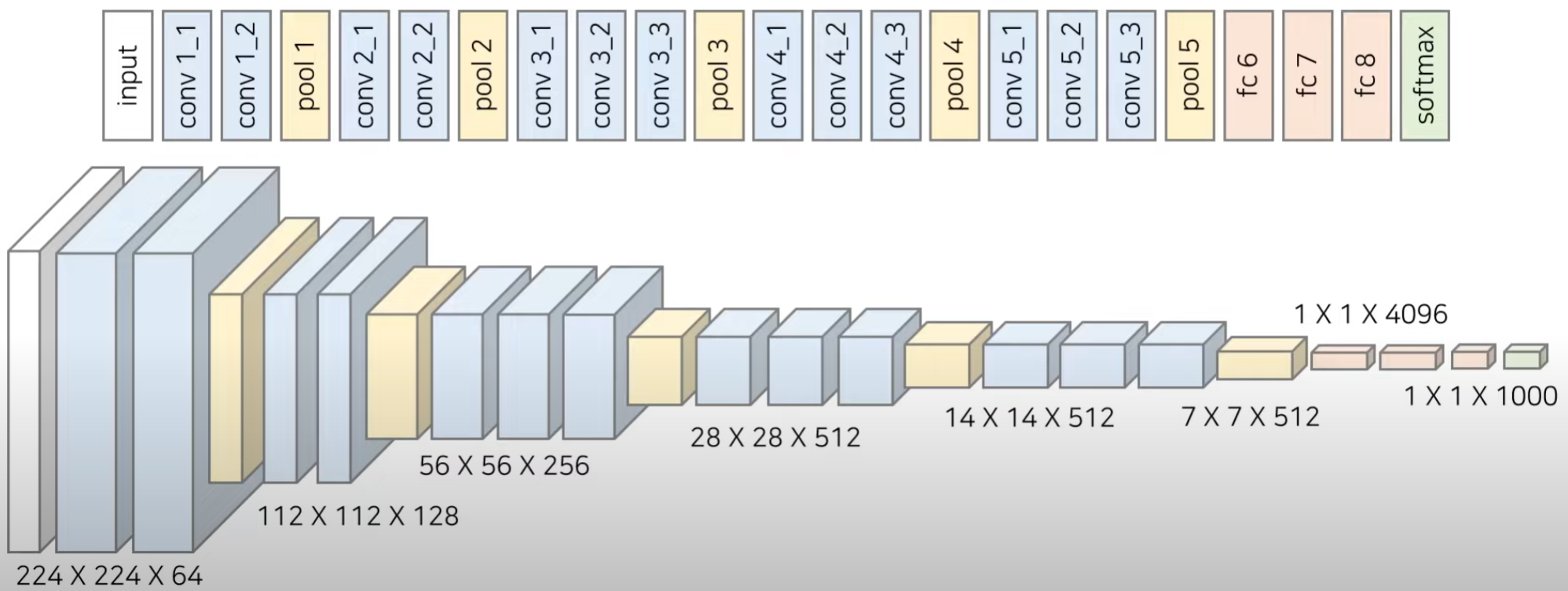
VGG Net은 작은 크기의 3x3 Conv filter를 이용해 layer의 깊이를 늘려 우수한 성능을 보였다.
- conv layer을 통해서 채널수를 증가시키는 방법을 취함
- 1000개의 class를 return할 수 있도록 architecture가 만들어져 있다. (imagenet이 1000개의 class를 구분해야 했기 때문)
3. U-Net (MICCAI 2015)
U자형으로 생긴 네트워크 U-Net
- 수축 경로(contracting path) : 이미지에 존재하는 넓은 문맥(context)정보를 처리한다.
- 확장 경로(expanding path) : 정밀한 지역화(precise localization)가 가능하도록 한다.
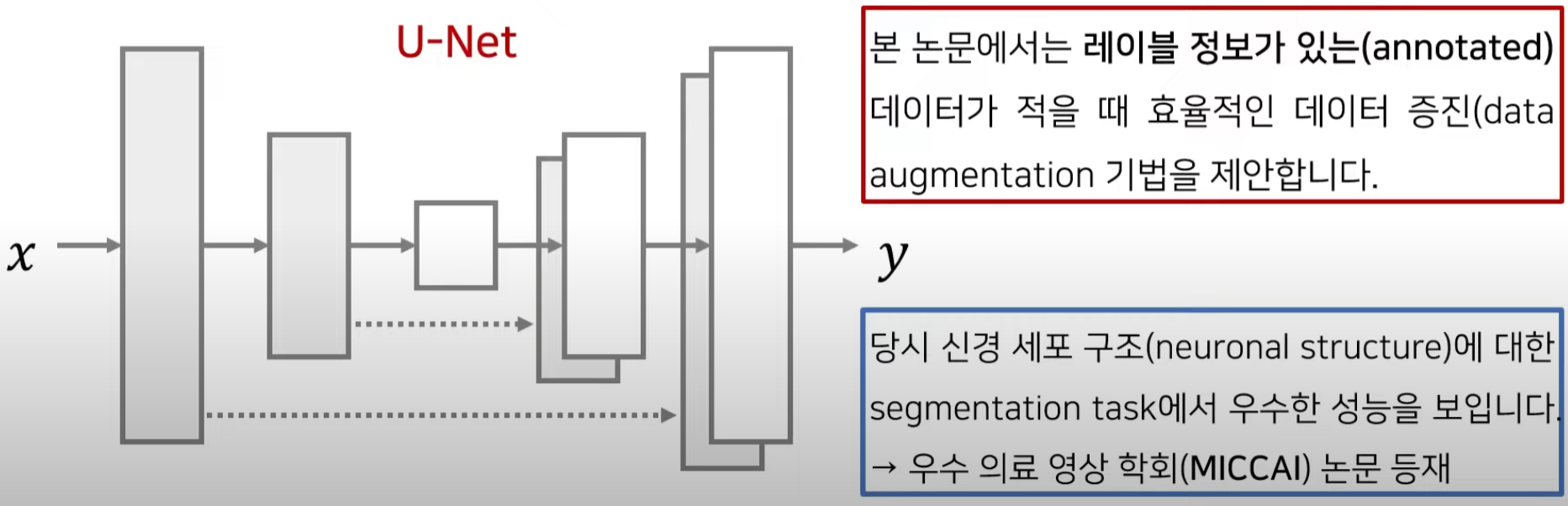
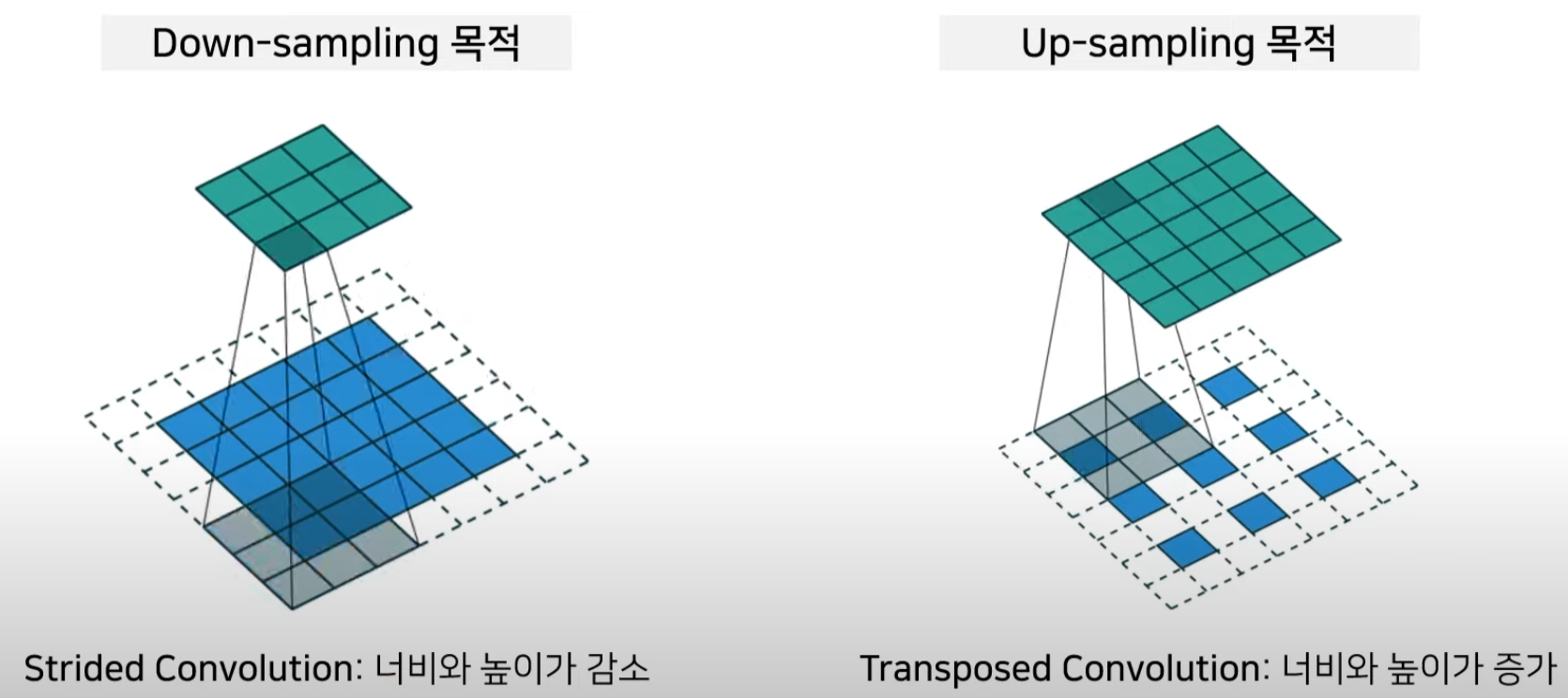
3.1 U-Net Architecture
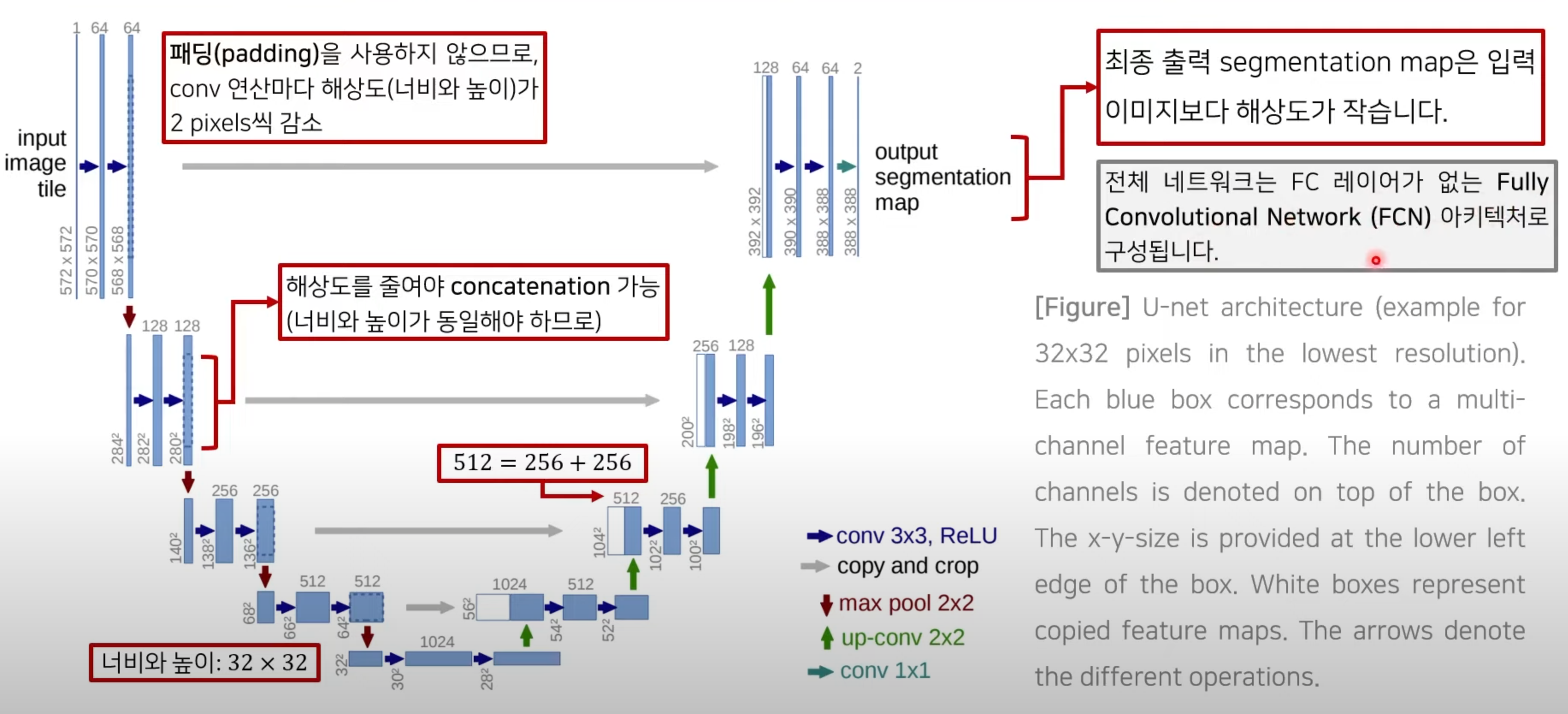
3.1.1 수축 경로(Contracting Path)
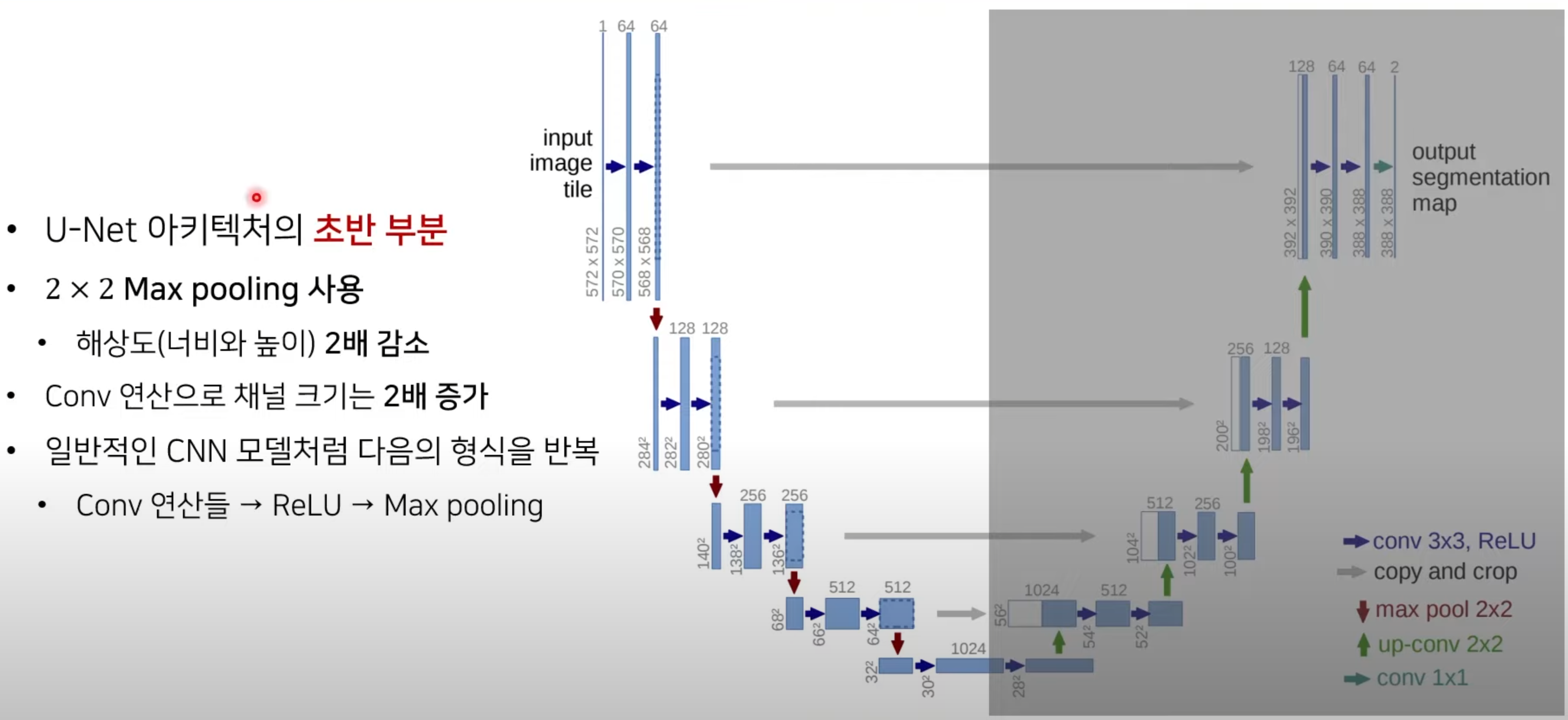 앞 부분을 그냥 encoder로 보고 다른 좋은 모델의 구조를 가져와서 사용하기도 한다.
앞 부분을 그냥 encoder로 보고 다른 좋은 모델의 구조를 가져와서 사용하기도 한다.
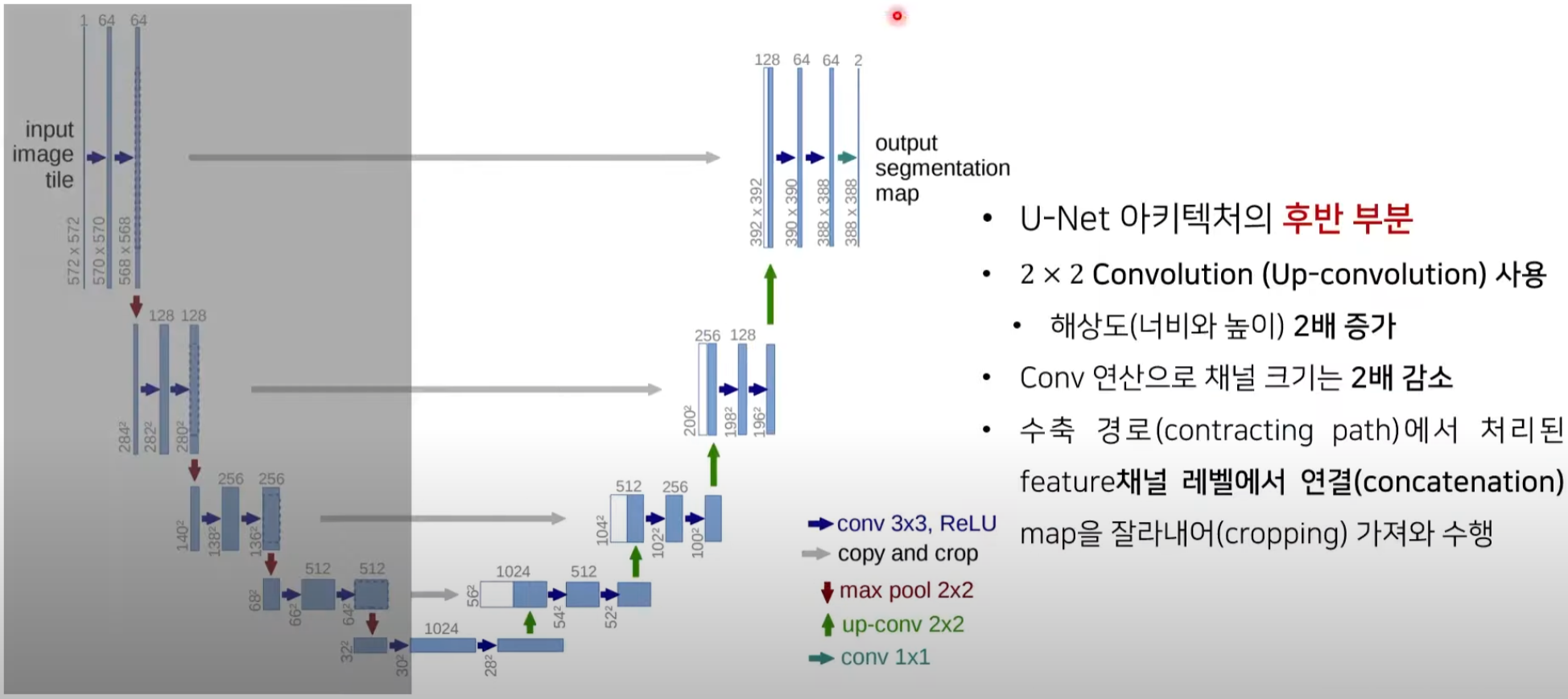
3.1.2 확장 경로(Expansive Path)
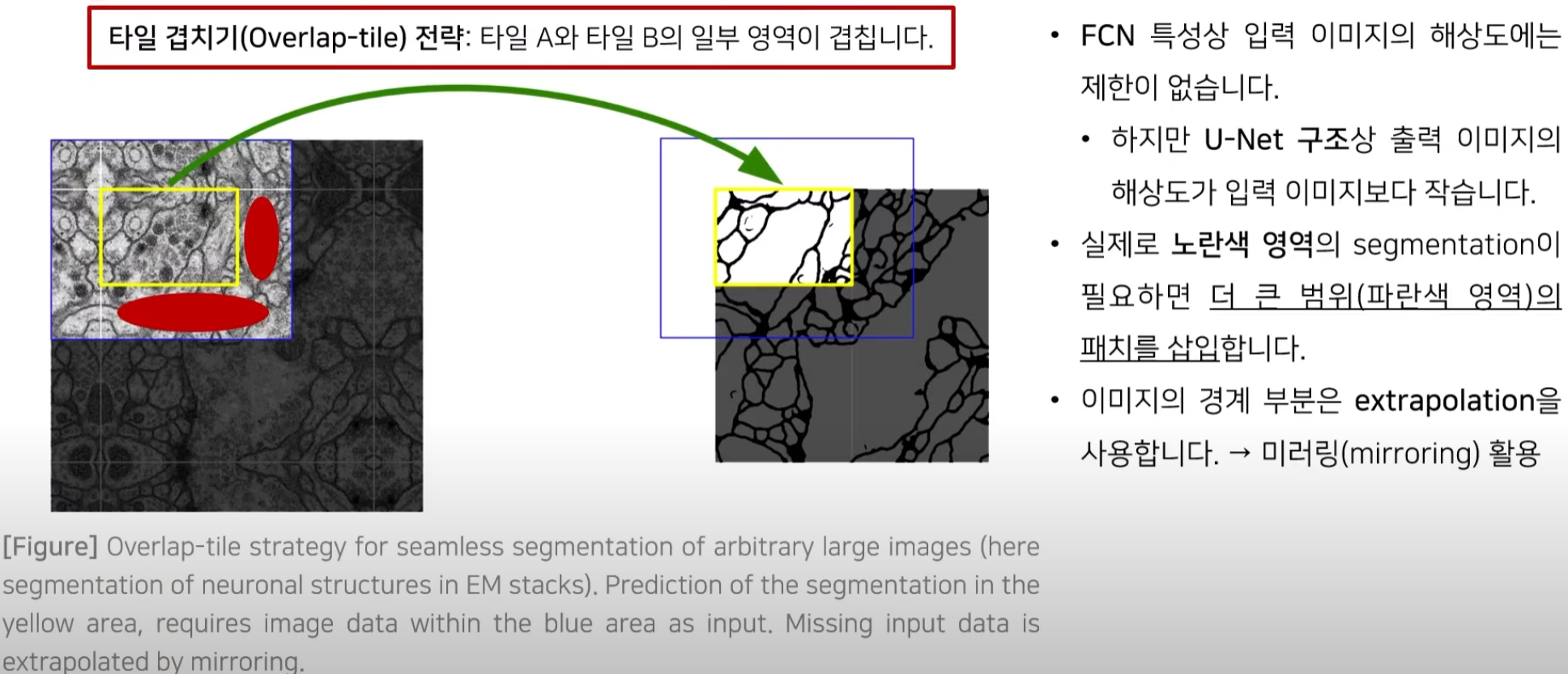
3.1.3 Overlap-tile 전략(strategy)
3.1.4 학습 방법 : Objective Function
- U-Net은 segmentation을 위한 네트워크이므로, 픽셀 단위(pixel-wise)로 softmax를 사용한다.

- 학습을 위해 다음의 corss-entropy 손실을 사용(true label만 고려하므로, 일반 corss entropy 공식과 동일)

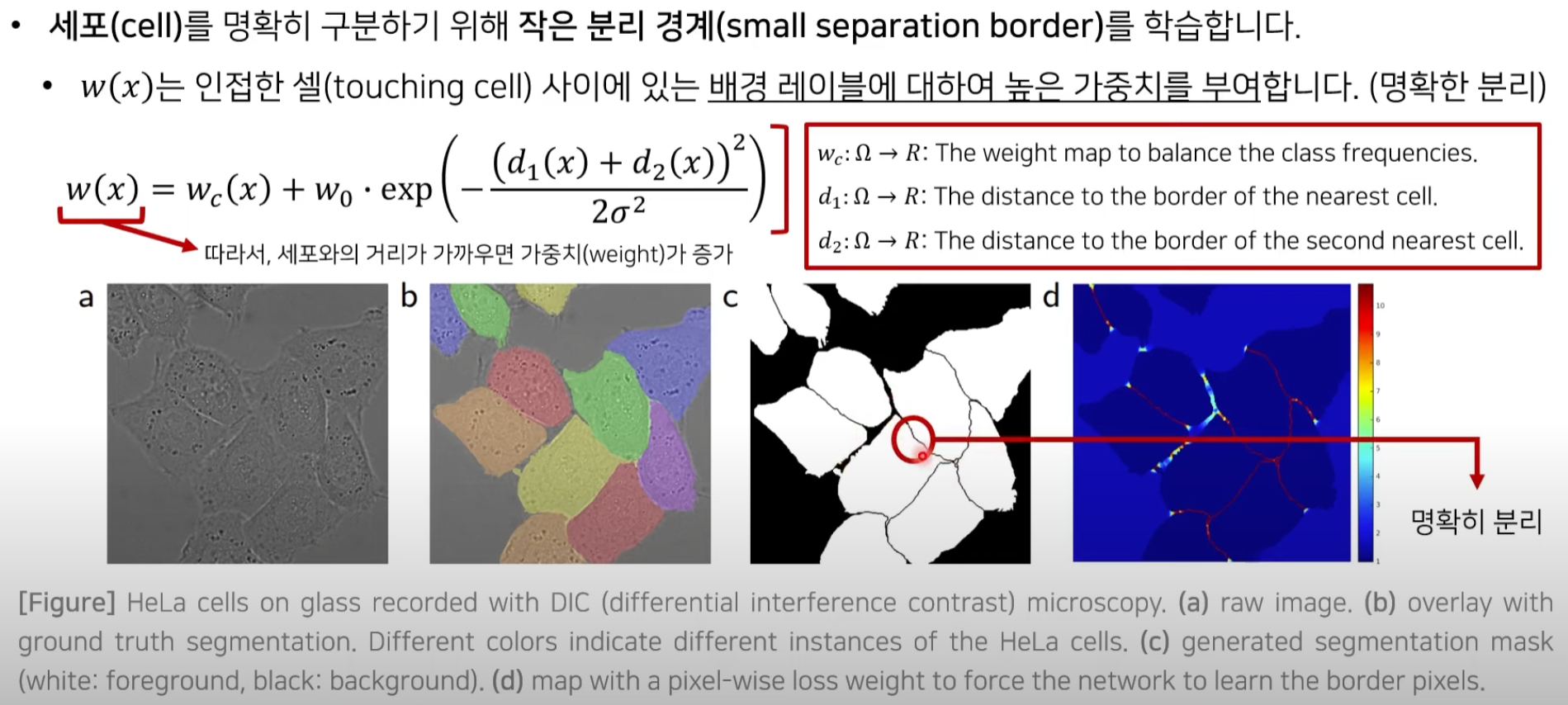 세포와의 거리가
세포와의 거리가
가까운 위치에서는 높은 가중치를 부여해서 이것이 확실히 배경이라는 것을 알려주는 것
5. 실험 결과
- EM(Electron Microscopy)segmentation 대회의 데이터 세트로 평가를 진행
- Warping error를 기준으로 정렬한 결과 U-Net이 우수한 정확도를 보인다.
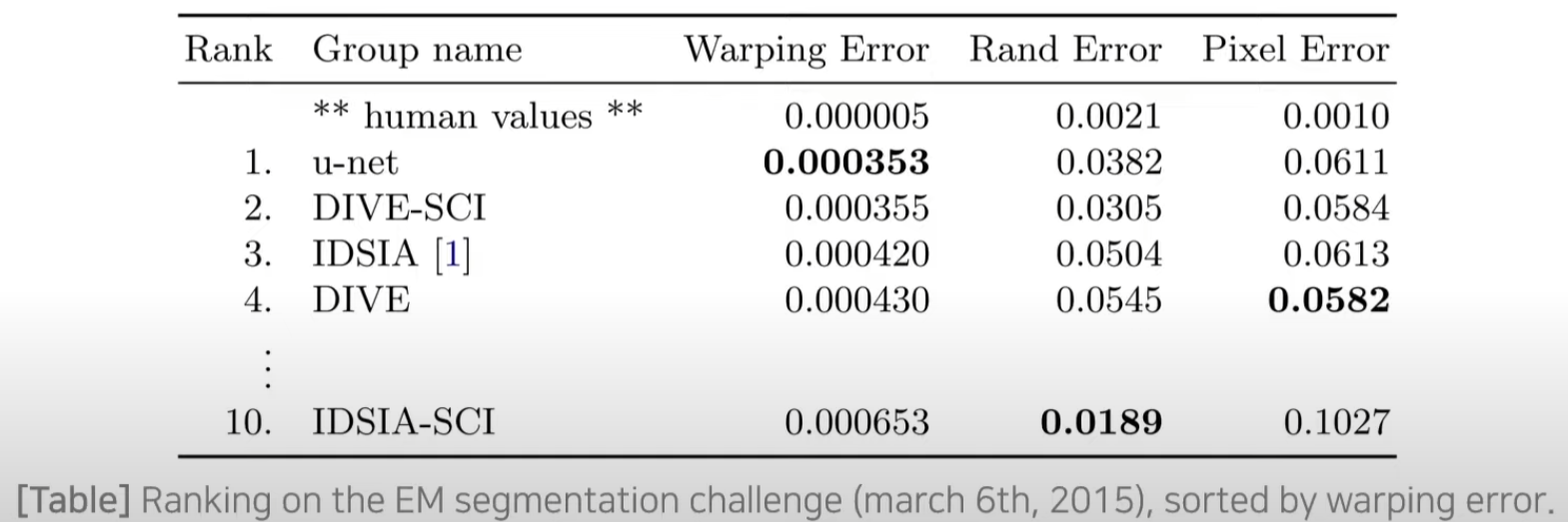
- Warping error를 기준으로 정렬한 결과 U-Net이 우수한 정확도를 보인다.
- 추가적인 두 개의 데이터 set(ISBI cell tracking challenge 2014 and 2015)에 대해서도 평가 진행
- PHC-U373
- DIC-HeLa
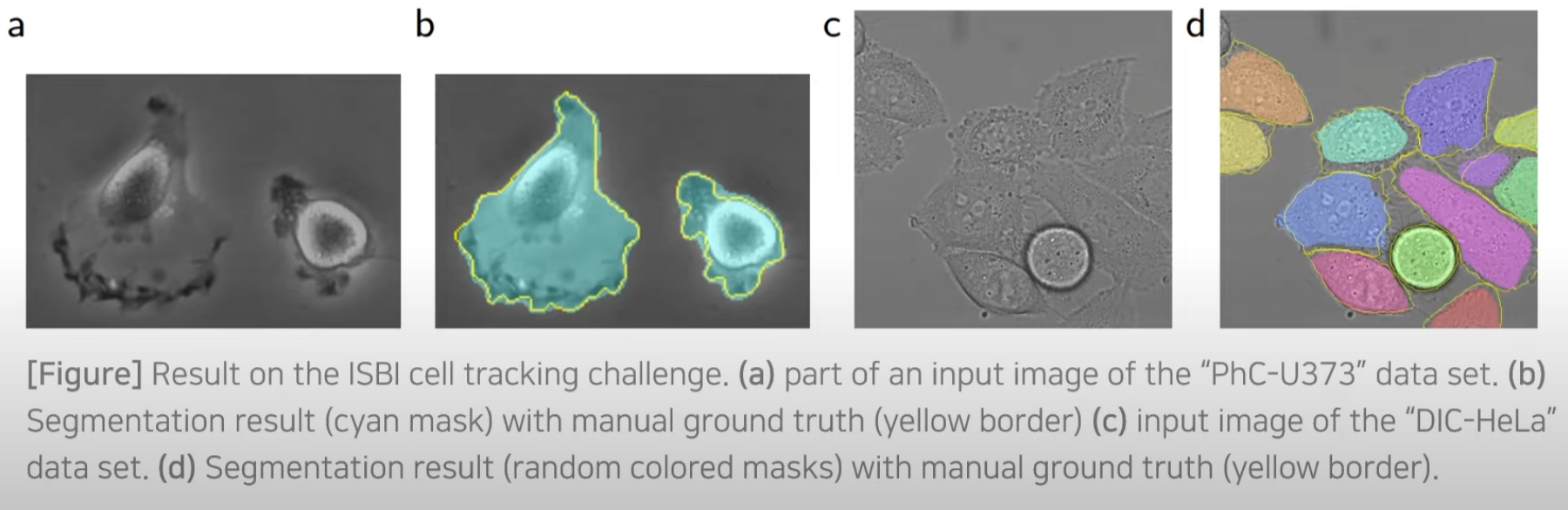 노란색 테두리(ground-truth)와 상당히 유사한 segmentation 결과를 보인다.
노란색 테두리(ground-truth)와 상당히 유사한 segmentation 결과를 보인다.
4. 참고 자료
