[Contents]
- Python Data Structure
- Pythonic code
- Generator & Iterator
[Python Data Structure]
- 파이썬에서 많이 사용되는 자료구조에 대해서 배운다
- 자료구조는 어떤 데이터를 저장할 때, 그 데이터에 특징에 따라 컴퓨터에 효율적으로 정리하기 위한 데이터의 저장 및 표현 방식을 이야기한다
- 어떤 데이터는 순서가 있다거나, 그 데이터의 나타내는 ID 값과 쌍으로 이룬다던가 하는 등의 특징이 나타나게 된다
- 일반적으로 사용되는 정수, 문자열등의 변수 타입보다는 이러한 특징들에 잘 맞는 형태로 데이터를 저장하게 된다면 훨씬 효율적으로 컴퓨터의 메모리를 사용하고, 프로그래머가 코드를 작성하기에도 용이하게 해준다.
파이썬 기본 데이터 구조
- 스택과 큐 (stack & queue with list)
- 튜플과 집합 (tuple & set)
- 사전 (dictionary)
- Collection 모듈
Stack (스택)
-
나중에 넣은 데이터를 먼저 반환하도록 설계된 메모리 구조
-
Last In First Out (LIFO)
-
Data의 입력을 Push, 출력을 Pop이라고 한다
-
리스트를 사용하여 스택 구조를 구현 가능
-
Push를 append(), pop 을 pop()을 사용
-
스택 example
- 스택 구조를 활용, 입력된 글자를 역순으로 출력
word = input('input a word: ')
word_list = list(word)
for i in range(len(word_list)):
print(word_list.pop())queue
- 먼저 넣은 데이터를 먼저 반환하도록 설계된 메모리 구조
- First In First Out (FIFO)
- Stack 과 반대되는 개념
- 리스트를 사용하여 큐 구조를 구현 가능
- push를 append(), get 을 pop(0)을 사용
배열
- (정적)배열
- 연속된, 정해진 크기의 메모리 공간을 할당
- 같은 타입의 원소만을 담을 수 있다 (정해진 크기의 메모리 공간을 할당하고, 이를 원소 타임, 원소 개수에 맞춰서 분할하기 때문이.)
- queue 구현에 사용되는 자료형이다
| 장점 | 단점 |
|---|---|
| 어느 위치에나 O(1)에 조회가 가능 | 한 번 생성한 배열은 크기 변경이 불가능 |
| 배열 시작 주소 + (원소 타임에 따른 byte 크기 * 원소 인덱스)로 해당 배열 원소 값의 주소 계산 및 메모리 접근이 가능 | 원소의 삭제나 삽입 등의 작업은 최악의 경우 O(n)의 시간복잡도를 갖는다 |
| 예를 들어 원소의 가장 첫번째 원소를 삭제한다고 가정하면 나머지 모든 원소를 하나씩 override해야 하므로 n-1개 만큼의 작업을 수행해야한다. |
- (동적)배열
- 실제로 정적 배열을 활용하기엔 비효율적인 경우가 많아서 크기를 사전에 지정하지 않는 동적배열을 알아보자
- 파이썬에서는 정적배열을 지원하지 않고 동적 배열만 지원한다
- 동적 배열의 구현
- 미리 초기값을 작게 잡아 배열을 생성하고, 데이터가 추가되면서 배열이 채워지게 되면 배열을 새로운 메모리 공간에 할당하고 기존 데이터를 모두 복사한다. (시간 복잡도 : O(n))
- 배열의 사이즈 증가는 대부분 2배씩 이루어진다
- 파이썬의 doubling 구조는 아래와 같다
- 처음은 2배씩 증가하지만 점점 감소한다
- 이러한 재할당 비율은 growth factor 라고 하며, 파이썬의 growth factor는 전체적으로 1.125배로 다른 언어에 비해 작다 (C++ : 2배, Java : 1.5배)

-
동적 배열 메모리 구조
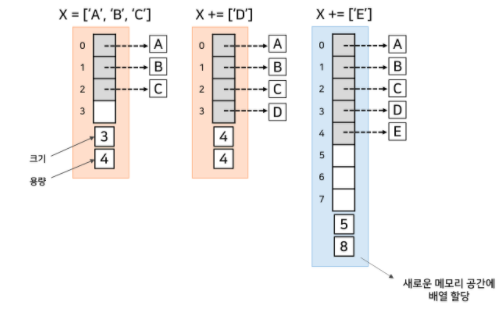
- 크기와 용량도 같이 저장되어 있다
- 더블링을 해야할 만큼 공간이 차게 되는 경우, 위에 말했듯이 최악의 경우 O(n)의 비용이 발생한다. 하지만 이는 자주 일어나지 않으므로 "분할 상환 분석"에 따른 입력 시간은 여전히 O(1)이다.
연결리스트
- 연결리스트는 배열과 달리 물리 메모리를 연속적으로 사용할 필요가 없다
- 따라서 동적으로 새로운 노드를 삽입 및 삭제하는 것이 간편하다
- 데이터를 구조체로 묶어서 포인터로 연결하는 개념 (연속된 메모리 공간에 할당되는 것이 아니므로 메모리 내에 scattered되어 있다고 생각)
- 연결리스트 메모리 구조
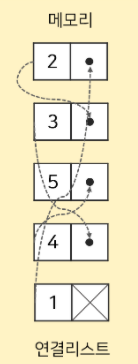
- 연결리스트는 원소가 메모리 공간에 연속적으로 존재하지 않아 특정 인덱스(원소)에 접근하기 위해서는 전체를 순서대로 읽어야한다 (배열 원소 개수에 dependent이므로 O(n)에 조회 가능)
- 연결리스트의 아이템을 추가하거나 삭제, 추출하는 작업은 O(1)에 가능 (포인터만 바꿔주면 되기 때문)
- 연결리스트는 stack 구현에 쓰이는 자료형
tuple
- 값의 변경이 불가능한 리스트
- 선언이 '[]' 가 아닌 "()" 를 사용
- 리스트의 연산, 인덱싱, 슬라이싱 등을 동일하게 사용
- 프로그램을 작동하는 동안 병경되지 않는 데이터의 저장
- 예: 학번, 이름, 우편번호 등등
- 함수의 반환 값등 사용자의 실수에 의한 에러를 사전에 방지
집합(set)
- 값을 순서없이 저장, 중복 불허 하는 자료형
- set 객체 선언을 이용하여 객체 생성
s = set([1,2,3,1,2,3]) # set 함수를 사용 1,2,3을 집합 객체 생성, a={1,2,3,4,5}도 가
s.add(1) # 한 원소 1만 추가, 추가, 중복불허로 추가 되지 않음
s.update([1,4,5,6,7]) # [1,4,5,6,7] 추가
s.discard(3) # 3 삭제
s.clear() # 모든 원소 삭제- 수학에서 활용하는 다양한 집합연산 가능
s1 = set([1,2,3,4,5])
s2 = set([3,4,5,6,7])
s1.union(s2) # s1 과 s2의 합집합 = {1,2,3,4,5,6,7} 출력
s1 | s2 # 또 다른 합집합 기호
s1.intersection(s2) # s1과 s2의 교집합 = {3,4,5} 출력
s1 & s2 # 또 다른 교집합 기호
s1.difference(s2) # s1과 s2의 차집합 = {1,2} 출력
s1 - s2 # 또 다른 차집합 기호dict
- 데이터를 저장 할 때는 구분 지을 수 있는 값을 함께 저장
- 예: 주민등록번호, 제품 모델 번호
- 구분을 위한 데이터 고유 값을 Identifier 또는 Key 라고함
- Key 값을 활용하여, 데이터 값 (Value)를 관리함
collections
- List, Tuple, Dict에 대한 Python Built-in 확장 자료 구조(모듈)
- 편의성, 실행 효율 등을 사용자에게 제공함
- 아래의 모듈이 존재함
- from collections import deque
- from collections import Counter
- from collections import OrderedDict
- from collections import defaultdict
- from collections import namedtuple
deque 모듈
- stack 과 queue를 지원하는 모듈
- list에 비해 효율적인=빠른 자료 저장 방식을 지원함
- rotate, reverse 등 linked list의 특성을 지원함
- 기존 list 형태의 함수를 모두 지원함
- 사용가능한 명령
- appendleft() # 0번째 인덱스에 append
- rotate(1) # 한칸씩 앞으로, 맨뒤는 맨앞으로
- extendleft() # 앞에 리스트가 붙는다
defaultdict 모듈
- Dict type의 값에 기본 값을 지정, 신규값 생성시 사용하는 방법
Counter 모듈
- sequence type의 data element 들의 갯수를 dict 형태로 반환
- dict type, keyword parameter 등도 모두 처리 가능
c = Counter({'red' : 4, 'blue' : 2}) # a new counter from a mapping
print(c) # Counter({'red' : 4, 'blue' : 2})
print(list(c.elements())) # {'blue', 'blue', 'red', 'red', 'red', 'red}
c = Counter(cats = 3, dogs = 2) # a new counter from keyword args
print(c) # Counter({'dogs': 2, 'cats' : 3})
print(c.elements())) # {'dogs','dogs','cats','cats','cats'}- set의 연산들을 지원함
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
print(c - d) # Counter({'a':3, 'b':0, 'c':-3, 'd':-6})
print(c + d) # Counter({'a':5, 'b':4, 'c':3, 'd':2})
print(c & d) # Counter({'b':2, 'a':1})
print(c | d) # Counter({'a':4, 'd':4, 'c':3, 'b':2})- word counter의 기능도 손쉽게 제공함
text = """A press release is the quickest and easiest way to get free publicity. If
well written, a press release can result in multiple published articles about your
firm and its products. And that can mean new prospects contacting you asking you to
sell to them. ….""".lower().split()
print(Counter(text))
print(Counter(text)['a'])namedtuple 모듈
- tuple 형태로 data 구조체를 저장하는 방법
- 저장되는 data의 variable을 사전에 지정해서 저장함
from collections import namedtuple
# basic example
Point = namedtuple('Point', ['x', 'y'])
print(Point) # __main__.Point
P = Point(x= 11, y=22)
print(p[0], p[1]) # (11, 22)
print(p) # Point(x=11, y=22)
print(p.x + p.y) # 33[Pythonic code]
- 파이썬 특유 문법을 의미하는 pythonic code에 대해 배운다.
- 앞서 우리는 파이썬의 가장 큰 장점 중 하나가 인간이 이해하고 쓰기 쉬운 언어라고 이야기를 했다.
- 파이썬의 이러한 특징을 가장 잘 살린 파이썬의 문법적 특징을 우리는 pythonic code라고 한다.
- pythonic code는 데이터 구조와 달리 특별히 모듈이나 함수가 존재하는 것이 아니다.
- 단지 앞에서 배운 str이나 다양한 모듈들을 활용하여 파이썬 특유의 문법을 표현하는 것이다.
- 파이썬 문법의 가장 큰 특징은 짧고 이해하기 편하다는 것이다.
- 코드의 수를 줄여서 비록 컴퓨터의 시간은 증가할 수 있지만, 사람의 시간은 아낄 수 있다는 장점이 있다.
- 추가적으로 python 2.x 버전에서 많이 썼던 lambda, map, reduce 와 난이도가 있는 파이썬 코딩을 위해 반드시 필요한 asterisk의 활용에 대해서 배운다.
skills to write pythonic code
- split & join
- list comprehension
- enumerate & zip
- lambda & map & reduce
- generator
- asterisk
list comprehension
- 일반적으로 for + append 보다 속도가 빠름
- 예: 이중 for문
word1 = ['a','b','c']
word2 = ['d','e','a']
result = [i + j for i in word1 for j in word2]
## result(one dimensional) same as ==
## for i in word1:
## for j in word2:
## result.append(i+j)
print(result) # ['ad', 'ae', 'aa', 'bd', 'be','ba'...ca]
result2 = [i + j for i in word1 for j in word2 if not(i==j)]
print(result) # ['ad','ae','bd','be','ba','cd','ce','ca']- Two dimensional vs One dimensional
word1 = ['a','b','c']
word2 = ['d','e','a']
## result(two dimensional) same as ==
## for j in word2:
## tmp = []
## for i in word2:
## tmp.append(i+j)
## result.append(tmp)
result = [[i+j for i in word1] for j in word2]
print(result) # [['ad','bd','cd'],['ae','be','ce'],['aa','ba','ca']]enumerate
- list의 element를 추출할 때 번호를 붙여서 추출
# list의 있는 index와 값을 unpacking 하여 list로 저장
mylist = ['a','b','c','d'] # [(0,'a'), (1,'b'), (2,'c'), (3,'d')]lambda & map & reduce
- lambda function
- 함수 이름 없이, 함수처럼 쓸 수 있는 익명 함수
- 수학의 람다 대수에서 유래
# General Funcion
def f(x,y):
return x+y
print(f(1,4)) # 5
# Lambda Function
f = lambda x, y : x + y
print(f(1,4)) # 5- map function
- 두 개 이상의 list에도 적용 가능함, if filter 도 사용가능
a = [1,2,3]
b = [4,5,5]
res = list(map(lambda x,y : x + y if x == 1 or y == 5 else 'yay', a,b))
print(res) # [5, 7, 'yay']- python3 는 iteration을 생성 -> list를 붙여줘야 list 사용가능
- 실행시점의 값을 생성, 메모리 효율적
- reduce function
- map function과 달리 list에 똑같은 함수를 적용해서 통합
from functools import reduce print(reduce(lambda x,y : x+y, [1,2,3,4,5])) # 15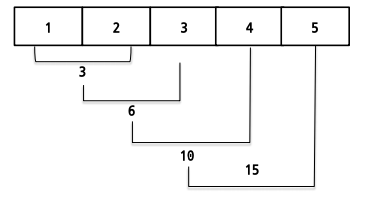
- map function과 달리 list에 똑같은 함수를 적용해서 통합
- 대용량의 데이터를 다룰때 reduce를 많이 사용한다. (딥러닝 대용량 데이터를 다룰때 map reduce 로 데이터를 핸들링 할때 많이 사용된다)
- summary
- lambda, map, reduce는 간단한 코드로 다양한 기능을 제곤
- 그러나 코드의 직관성이 떨어져서 lambda 나 reduce는 python3에서 사용을 권장하지 않음
- 하지만 legacy library나 다양한 머신러닝 코드에서 여전히 많이 사용중
[Iterator & Generator]
- Container
- 원소들을 가지고 있는 데이터 구조
- 메모리에 상주하는 데이터 구조로, 보통 모든 원소값을 메모리에 가진다
- 어떤 객체가 특정한 원소를 포함하고 있는지 아닌지를 판단할 수 있으면 컨터이너라고 한다
- 파이썬에서 잘 알려진 컨터이너는 다음과 같다:
- list, deque, ...
- set, ...
- dict, defaultdict, OrderedDict, Counter, ...
- tuple, namedtuple, ...
- str
iterable
- 대부분의 컨터이너는 또한 iterable하다
- sequence 형 자료형에서 데이터를 순서대로 추출하는 object
- iterable은 반드시 데이터 구조일 필요는 없으면 interator(모든 원소를 반환할 목적으로)를 반환할 수 잇는 모든 객체가 가능하다
- iterable과 iterator 사이에는 중요한 차이점이 있다
x = [1,2,3]
y = iter(x)
z = iter(x)
next(y) # 1
next(y) # 2
next(z) # 1
type(x) # <class 'list'>
type(y) # <class 'list_iterator'>- 여기서, y와 z는 각각 iterable x로부터 값을 생성해내는 iterator의 istance이고 x는 iterable이다
- y와 z는 예시에서 볼 수 있듯이 상태를 가진다
- 위 예시에서 x는 데이터 구조(리스트)이지만, 이는 필수 요건은 아니다
- iterable 객체로 만들면 메모리 다음 위치들에 대한 정보를 가질뿐 모든 정보를 아직 생성하지 않은 상태이다
cities = ["Seoul", "Busan",
"Jeju"]
iter_obj = iter(cities)
print(next(iter_obj))
print(next(iter_obj))
print(next(iter_obj))
next(iter_obj)Iterator
- iterator란 무엇인가?
- 이는 next()를 호출할 때 다음값을 생성해내는 상태를 가진 helper 객체이다.
- next()를 가진 모든 객체는 iterator이다
- 즉, iterator는 값 생성기이다. '다음'값을 요청할 때마다 내부 상태를 유지하고 있기 때문에 다음값을 계산하는 방법을 알고있다
generator
- 모든 generator는 iterator이다 (그 반대는 성립X)
- 모든 generator는 값을 그 때 그 때 생성한다
- iterable object를 특수한 형태로 사용해주는 함수
- element가 사용되는 시점에 값을 메모리에 반환
- yield를 사용해 한번에 하나의 element만 반환함
# 일반 리스트
def general_list(value):
result = []
for i in range(value):
result.append(i)
return result
# generator 리스트
def generator_list(value):
for i in range(value):
yield i- 평소에는 값을 메모리에 올려놓지 않고 메모리의 주소 값만 가지고 있는다.
- for 문으로 하나씩 print 할때 함수 안에 있는 yield 가 값을 하나씩 준다.
- yield 를 사용해서 generator 를 만들게 되면 훨씬 더 메모리를 절약 할 수 있다.
- 대용량 데이터 일때는 메모리를 한번에 다 올려놓는것 보다 대기를 하고 있다가 필요할때 불러쓰면 더 좋다.
- generate를 쓰는걸 권장함 왜냐하면 용량을 아낄 수 있다.
- generator comprehension
- list comprehension 과 유사한 형태로 generator 형태의 list 생성
- generator expression 이라는 이름으로도 부름
- [] 대신 ()을 사용하여 표현
gen_ex = (n*n for n in range(500))
print(type(g)) -
why generator?
- 일반적으로 iterator 는 generator에 반해 훨씬 큰 메모리 용량 사용
-
when generator?
- list 타입의 데이터를 반환해주는 함수는 generator로 만들어라!
- 읽기 쉬운 장점, 중간 과정에서 loop이 중단될 수 있을 때!
- 큰 데이터를 처리할 때는 generator expression을 고려하라!
- 데이터가 커도 처리의 어려움이 없음
- 파일 데이터를 처리할 때도 generator를 쓰자
- list 타입의 데이터를 반환해주는 함수는 generator로 만들어라!
-
precaution for generator
- list()로 만든 리스트와 list(generator())로 만든 리스트간의 메모리 사용량이 다른 이유?
- getsizeof가 return 되는 bytes의 값을 계산하는게 아니라 reference 크기를 계산하기 때문이다
- 더 자세한 설명은 이 페이지 에서 ‘A More Complex and a More Accurate Answer’ 파트를 참고
- list()로 만든 리스트와 list(generator())로 만든 리스트간의 메모리 사용량이 다른 이유?
import sys
def gen_func(x):
for i in range(x):
yield i
print(sys.getsizeof(list(gen_func(10)))) # 152
print(sys.getsizeof([i for i in range(10)])) # 182- 정리
- generator는 메모리/CPU 효율이 좋다
- 코드의 라인수를 줄여주는 경향도 있다
function passing argument
- 함수에 입력되는 arguments의 다양한 형태
i. keyword arguments
ii. default argument
iii. variable - length arguments
- 함수에 입력되는 parameter의 변수명을 사용, arguments를 넘김
def print_something(my_name, your_name):
print("Hello {0}, My name is {1}".format(your_name, my_name))
print_something("Sungchul", "TEAMLAB") # Hello Sungchul, my name is TEAMLAB
print_something(your_name="TEAMLAB", my_name="Sungchul")
# Hello Sungchul, my name is TEAMLAB가변인자(variable-length) using asterisk(*)
- 개수가 정해지지 않은 변수를 함수의 parameter로 사용하는 법
- keyword arguments와 함께, argument 추가가 가능
- Asterisk(*) 기호를 사용하여 함수의 parameter를 표시함
- 입력된 값 tuple type으로 사용할 수 있음
- 가변인자는 오직 한 개만 맨 마지막 parameter 위치에 사용가능
- 가변인자는 일반적으로 *args를 변수명으로 사용
- 기존 parameter 이후에 나오는 값을 tuple로 저장함
def asterisk_test(a, b,*args):
return a+b+sum(args) # 1 + 2 + sum(3,4,5)
print(asterisk_test(1, 2, 3, 4, 5)) # 15키워드 가변인자 (keyword variable - length)
- parameter 이름을 따로 지정하지 않고 입력하는 방법
- asterisk(*) 두개를 사용하여 함수의 parameter를 표시함
- 입력된 값은 dict type으로 사용할 수 있음
- 가변인자는 오직 한 개만 기존 가변인자 다음에 사용
def kwargs_test_3(one,two,*args,**kwargs):
print(one+two+sum(args)) # 3 + 4 + sum(5,6,7,8,9)
print(kwargs) # (3,4,5)
kwargs_test_3(3,4,5,6,7,8,9, first=3, second=4, third=5)asterisk
- 흔히 알고 있는 * 을 의미함
- 단순 곱셈, 제곱연산, 가변 인자 활용 등 다양하게 사용됨
- asterisk - unpacking a container
ex = [[1,2],[3,4],[5,6],[7,8],[9,10]]
print(*ex) # [1, 2] [3, 4] [5, 6] [7, 8] [9, 10]
for value in zip(*ex):
print(value)
# (1, 3, 5, 7, 9)
# (2, 4, 6, 8, 10) 
아기개발자