[Contents]
1) Beam Search
2) BLEU score
Beam Search
- 문장을 decoding 하는 데에 사용하는 대표적인 알고리즘인 Beam Search를 소개
- 언어 모델이 문장을 generation할 때에는 확률값에 기반한 다양한 경우의 수가 존재한다
- 모든 경우의 수를 고려하는 것은 비효율적이며 너무 작은 확률값까지 고려한다면 생성된 문장의 quality가 떨어질 수 있다
- 가장 높은 확률값을 고려하는 방법 역시 모델이 단순한 generation을 하도록 하게 만드는 단점이 있을 수 있다
- 이러한 문제의 대안으로 제안된 Beam Search를 소개
Further Readings
Further Question
- BLEU score가 번역 문장 평가에 있어서 갖는 단점은 무엇이 있을까요?
Greedy decoding
- seq2seq w/ attention과 같은 자연어 생성 모델에서 바로 다음 단어만을 예측하는 task를 학습하고 모델 사용시 다음단어만을 순차적으로 생성한다
- 매 time step마다 가장 높은 확률을 가지는 단어 하나만을 택해서 decoding을 진행하는 이를 greedy decoding이라 부른다
- sequence로써의 전체적인 문장의 확률값을 보는것이 아니라 근시안 적으로 현재 time step 에서 가장 좋아보이는 단어를 그때그때 선택하는 방법
- 잘못 단어를 예측한 상황 이라도 뒤로 돌아갈수 없는 그래서 결국엔 최적의 예측값을 내지 못하는 상황이 발생한다
- 이를 해결할수 있는 방법은?
- exhaustive search (기하급수적으로 증가하는 계산량 때문에 현실적으로 불가능
- Beam Search (차선책)
Exhaustive search
- ideally, we want to find a (length ) translation that maximizes
- 주어진 문장 에 대한 출력 문장 이른바 joint probability (동시 사건)에 대한 확률분포를 수식으로 쓸 수 있다
- 출력문장 전체로써 확률값을 최대가 되도록 하는 답을 뽑는것이 최선이다
- 그러면 이 경우 첫번째 생성하는 단어가 그 당시에는 값이 가장 큰 확률값을 가지는 단어였다 하더라도 뒷부분에서 상대적으로 낮은 확률값을 가지게 되면 총 확률값은 크지 않을 경우가 발생될 수 있다
- 이런경우 첫번째 생성하는 단어의 확률값이 제일 큰 확률값이 아니더라도 뒷부분에서 상대적으로 더 큰 확률값들을 내어줄수 있는 선택을 하는것이 전체적인 joint probability의 값을 최대화 하는데 더 좋은 결과를 낼수 있다
- we could try computing all possible sequences y
- 그럼 결국 어떤 time step 까지의 가능한 모든 경우를 따진다면 그 경우는 매 time step 마다 고를수 있는 단어의 수가 vocab size 가 되고 매 time step마다 의 가짓 수 그리고 time step 가 있으면 로 가능한 가지 수를 다 고려해야한다
- 이 경우 기하급수적으로 증가하는 경우의 수를 현실적으로 다 계산하기에는 너무 많은 시간과 계산량이 필요로 하게 된다
- complexity
- 차선책으로 나온 방법이 Beam search 방법이다
Beam Search
- Core idea : decoder의 매 time step마다 하나의 candidate만을 고려하는것도 아니고 기하급수적으로 늘어나는 만큼 고려하는것도 아니라 사용자가 정의해놓은 개의 가능한 가지수를 고려하고 time step 이 진행함에도 개의 경우의 수를 유지하고 마지막 까지 decoding을 진행한 후 최종적으로 나온 개의 candidate중에서 가장 확률이 높은것을 택하는 방식이다
- 개의 경우의 수에 해당하는 decoding의 output을 hypothesis 라 부른다
- is the beam size(in practice around 5 to 10)
- A hypothesis has a score of its log probability:
- log log
- 로그를 씌워 곱셈을 덧셈으로 변경시킨다
- 로그함수는 단조증가하는 함수 이기 때문에 로그를 취하지 않은 확률값에서의 가장 큰 확률값이 로그를 취한 확률값에서의 가장 큰 확률값이다
- scores are all negative, and a higher score is better
- score가 가장 높은 개의 candidate을 고려하고 추적하는것이 beam search의 핵심 아이디어 이다
- 모든 경우의 수를 따져서 가장 높은 확률을 뽑는것이 아니기 때문에 global optimal solution을 찾는것이 보장되있지는 않다
- 하지만 모든 경우의 수를 따지는 exhaustive search보다 훨씬 효율적으로 계산할 수 있다
Beam Search: Example
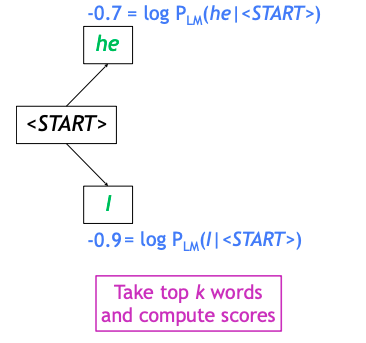
- beam size: = 2
- SOS 토큰에서 시작을 하고 첫번째 단어를 예측한다
- 그 예측값은 vocabulary 에 정의된 단어 상에서 확률분포로 output이 나타나게 되고 가장 확률값이 높은 2개의 단어를 뽑는다
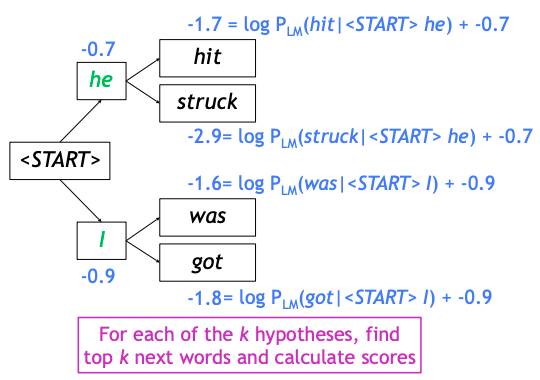
- 다음으로는 현재 가지고 있는 개의 hypothesis를 가지고 각각의 경우를 가지고 다음 단어를 예측하도록 한다
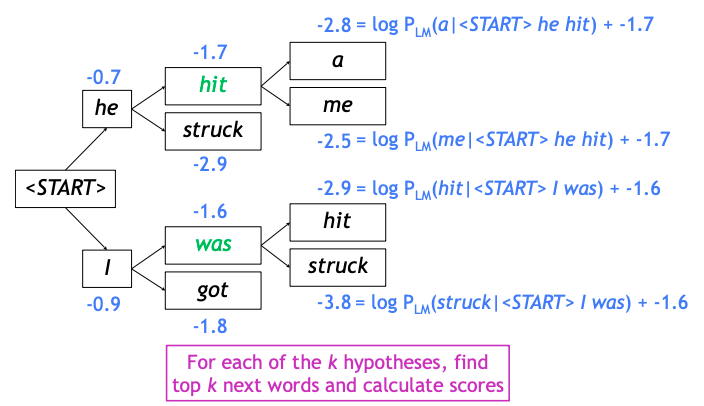
- 일시적으로 개의 결과 중에서 가장 확률이 큰 개 만의 hypothesis로 추리게 된다
Beam Search : Stopping criterion
- Greedy decoding의 경우 생성을 끝내는 시점은 모델이 EOS 토큰을 해당 time step의 예측단어로 예측했을때이다
- beam search decoding의 경우는 서로 다른 경로(hypothesis)가 존재하고 그것들은 각각 서로 다른 시점에서 EOS 토큰을 생성할수 있게 된다
- 그래서 hypothesis를 개 만큼씩 계속 추적해가면서 decoding과정을 진행할때 어느 hypothesis가 EOS 토큰을 어느 시점에서 생성했다면 그 hypothesis 에 대해서는 더이상 생성과정을 진행하지 않고 저장공간에 임시로 저장해둔다
- 그리고 남은 hypothesis에 대해서는 decoding을 수행해서 각각의 EOS 토큰을 발생할때까지 decoding을 수행한다
- usually we continue beam search until:
- 사용자가 정한 time step 만큼 decoding 을 하고 중단하거나
- 혹은 임시 저장공간에 저장해둔 EOS 토큰을 명시적으로 발생해서 완료된 hypothesis 로 저장된것이 총 사용자가 미리 정해둔 개 만큼 저장되면 beam search를 중단한다
Beam Search: Finishing up
- 완성된 hypothesis 의 리스트를 최종적으로 얻게되고 이중에서 가장 높은 score를 가지는 단 하나의 값을 뽑는다
- Problem with this : longer hypothesis have lower scores
- Fix: Normalize by length
- log
- Fix: Normalize by length
BLEU score
- 번역 task에서 번역된 문장을 평가하는 대표적인 metric인 BLEU score를 소개
- 자연어는 컴퓨터가 이해할 수 있는 방식으로 변환되어 모델의 입력 및 출력으로 활용되기 때문에 적절한 metric을 이용해 모델을 평가해야 한다
- 다양한 자연어처리 관련 metric이 있지만, 그중에서도 번역 task에서 가장 대표적인 BLEU score를 소개한다
- 번역에 있어서 BLEU score가 precision을 고려하는 이유에 대해서 고민해보자
Precision and Recall
- 특정 time step에서 어떤 특정 ground truth 단어가 나와야 하는 그러한 가정하에 평가를 진행하게 되면 전체적인 문장으로 볼때 단어를 중간에 하나 빼먹고 생성했다거나 혹은 추가적인 단어를 중간에 하나 더 많이 생성한 경우 평가의 신뢰도가 떨어진다
- 예)
- ground truth 문장 : I love you.
- 생성된 문장 : Oh I love you.
- 이 경우에는 첫번째 time step에서 나와야하는 단어는 I 였는데 Oh라는 단어가 생성되서 단어가 하나씩 밀리게 되기 때문에 어느 time step에서도 정답을 맞추지 못한 그래서 해당 정확도는 0% 로 계산이 된다
- 이는 생성된 문장 전체를 가지고 두 문장들을 비교하고 유사도를 평가하는 것이 아니라 고정된 위치에서 정해진 단어 하나가 나와야된다는 단순화된 평가방식 때문이다
- 예)
- 따라서 생성한 sequence 문장과 ground truth 문장 전체적인 차원에서 평가를 진행해야한다
- 이를 위해 두 가지 평가방법을 생각해볼 수 있다
1) Precision(정밀도) : 예측된 결과가 노출이 되었을때 실질적으로 느끼는 정확도
2) Recall(재현율) : 의도에 부합하는 정보의 갯수중에서 몇개를 사용자에게 노출 시켜주었는지 평가하는 척도 - example:
- Reference(ground truth) : Half of my heart is in Havana ooh na na
- Predicted : Half of my heart is in Obama ooh na
- #(correct words) = 예측한 문장과 ground truth 문장간의 겹치는 단어의 갯수
- precision 과 recall 을 조화평균을 내서 하나의 값으로 summarize 할때 작은 값에 좀 더 치중된 값으로 개선하겠다는 의도
- 정밀도와 재현율이 균등하게 반영될 수 있도록 정밀도와 재현율의 조화평균을 계산한 값으로 생성된 문장을 종합적으로 평가하는 지표이다
- 이 값이 높을수록 생성된 문장이 좋다고 말할 수 있다
자연어 생성의 ground truth 값 대비 예측값의 정확도를 개선하는 방식
- example)
- predicted (from model 1) : Half as my heart is in Obama ooh na
- reference (ground truth) : Half of my heart is in Havana ooh na na
- predicted (from model 2) : Havana na in heart my is Half ooh of na
-
Metric Model 1 Model 2 Precision 78% 100% Recall 70% 100% F-measure 73.78% 100$
- model 2가 예측한 값은 전혀 문법적으로 말이 되지 않는 문장이 된다 하지만 전체 sequence의 단어 갯수도 ground truth와 동일하고 또 각각의 단어들이 순서는 다르지만 ground truth에 있는 단어들과 정확하게 일치하기 때문에 precision, recall, f-measure 모두 100% 가 나온다
- 이러한 문제를 보안하기 위해서 기계번역 task 에서 제안된 성능평가 measure인 BLEU score를 사용한다
BLEU score
- brevity penalty
- BiLingual Evaluation Understudy (BLEU)
- 개별 단어 레벨에서 봤을때 얼마나 공통적으로 ground truth 문장과 겹치는 단어가 나왔는지에 대한 계산 뿐만 아니라 N-gram 이라 불리는 즉, 연속된 n개의 연속된 단어로 봤을때 phrase가 정확하게 ground truth와 얼마나 겹치는지를 계산해서 최종 평가 measure에 반영하는 것이 BLEU에 가장 큰 특징
- recall 은 무시하고 precision 만을 고려한다
- 가령 'I love this movie very much' 라는 문장이 있다고 생각할때 이를 한글로 번역하는 경우에 '나는 이 영화를 많이 사랑한다' 라고 번역을 한 경우에 ground truth 단어의 'very' 에 해당하는 '정말' 이라는 단어가 생략된것을 알수 있다
- 그렇지만 이 단어가 생략됬다 하더라도 이 문장이 충분히 좋은 정확도를 가지는 번역 결과라고 볼 수 있다
- 따라서 precision 이라는 것은 주어진 예측 문장에서 ground truth 단어와 얼마나 겹치는가 즉, 재현율에 해당하는 ground truth 에서 하나하나 다 빠짐없이 번역했는지에 대한 요소보다는 번역 결과만을 보고 몸소 느낄수 있는 정확도에 해당하는 precision만을 고려하는 measure가 된다
- compute precision for n-grams of size one to four
- 4-gram 까지를 단위로 해서 각 경우에 대해서 precision에 대해서 기하평균을 구한다
- 이 기하평균의 의미는 4개의 서로 다른 precision 값을 좀 더 값이 작은쪽에 더 많은 가중치를 부여한 형태로 평균값을 계산한다
- Add brevity penalty (for too short translations)
- reference 길이보다 좀 더 짧은 문장을 생성한 경우에 짧아진 비율만큼 precision 값을 낮춰주겠다는 의미가 된다
- recall의 최대값을 의미한다 즉, reference 문장에 10개의 단어가 있고 생성하는 문장의 길이가 10개면 실제 recall을 계산하기 이전에 10개 단어가 모두가 매칭이 된 이상적인 상황에선 100% recall을 기대할 수 있게 된다
- 마찬가지로 예측된 문장의 단어가 reference 단어보다 많은 경우에 ground truth에 있는 모두다 소환했다라는 이상적인 경우를 생각해보면 recall의 최대값으로써 1이 나오게된다
- recall 을 아이에 고려하지 않은 simple한 형태의 brevity penalty로써 recall의 요소도 고려하게 된다
BLEU score example
- predicted (from model 1) : Half of my heart is in Obama ooh na
- reference (ground truth) : Half of my heaert is in Havana ooh na na
- predicted (from model 2) : Havana na in heart my is Half ooh of na
| Metric | Model 1 | Model 2 |
|---|---|---|
| Precision (1-gram) | ||
| Precision (2-gram) | ||
| Precision (3-gram) | ||
| Precision (4-gram) | ||
| Brevity penalty | ||
| BLEU | 0 |
Reference
deeplearning.ai-Beam Search
deeplearning.ai-Refining Beam Search
OpenNMT-beam search
CS224n-NMT
Sequence to sequence learning with neural networks, ICML’14
Effective Approaches to Attention-based Neural Machine Translation, EMNLP 2015

아기개발자