정렬 알고리즘이란?
정렬 알고리즘이란 원소들을 번호순이나 사전 순서와 같이 일정한 순서대로 열거하는 알고리즘이다.
대표적인 정렬 알고리즘 종류
- O()
- 버블 정렬- 선택 정렬
- 삽입 정렬
- O()
- 병합 정렬- 퀵 정렬
버블 정렬
- 서로 인접한 두 원소를 검사하여 정렬하는 알고리즘
- 인접한 2개의 레코드를 비교하여 정렬되어 있지 않으면 서로 교환한다.
과정
- 1회전에 첫 번째 원소와 두 번째 원소를, 두 번째 원소와 세 번째 원소를, 세 번째 원소와 네 번째 원소를, … 이런 식으로 (마지막-1)번째 원소와 마지막 원소를 비교하여 조건에 맞지 않는다면 서로 교환한다.
- 1회전을 수행하고 나면 가장 큰 원소가 맨 뒤로 이동하므로 2회전에서는 맨 끝에 있는 원소는 정렬에서 제외되고, 2회전을 수행하고 나면 끝에서 두 번째 원소까지는 정렬에서 제외된다. 이렇게 정렬을 1회전 수행할 때마다 정렬에서 제외되는 데이터가 하나씩 늘어난다.
버블 정렬은 인접한 두 수를 비교하며 정렬해나가는 방법으로 O()의 느린 성능을 가짐
파이썬 예제 코드
array = [9,8,7,6,5,4,3,2,1]
def bubble_sort(array):
n = len(array)
for i in range(n - 1):
for j in range(n - i - 1):
if array[j] > array[j + 1]:
array[j], array[j + 1] = array[j + 1], array[j]
print(array)
print("before: ",array)
bubble_sort(array)
print("after:", array)결과

선택 정렬
- 데이터에서 가장 작은 데이터를 선택하여 앞으로 보내는 정렬
과정
- 주어진 배열 중에서 최솟값을 찾는다
- 그 값을 맨 앞에 위치한 값과 교체한다
- 맴 처음 위치를 뺀 나머지 리스트를 같은 방법으로 교체한다
- 하나의 원소만 남을 때까지 위의 1~3 과정을 반복한다

파이썬 예제 코드
array = [8,4,6,2,9,1,3,7,5]
def selection_sort(array):
n = len(array)
for i in range(n):
min_index = i
for j in range(i + 1, n):
if array[j] < array[min_index]:
min_index = j
array[i], array[min_index] = array[min_index], array[i]
print(array[:i+1])
print("before: ",array)
selection_sort(array)
print("after:", array)결과
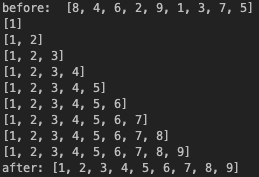
선택 정렬도 버블 정렬과 마찬가지로 O()의 복잡도를 가진다.
삽입 정렬
- 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘
과정
- 두 번째 자료부터 시작해서 그 앞의 자료들과 비교하여 삽입할 위치를 지정한 후, 자료를 뒤로 옮기고 지정한 자리에 자료를 삽입하여 정렬한다.
- 두 번째 자료는 첫 번째 자료, 세 번째 자료는 두 번째와 첫 번째 자료, 네 번째 자료는 세 번째, 두 번째, 첫 번째 자료와 비교한 후 자료가 삽입될 위치를 찾는다.
- 자료가 삽입될 위치를 찾았다면 그 위치에 자료를 삽입하기 위해 자료를 한 칸씩 뒤로 이동시킨다.

파이썬 예제 코드
array = [8,4,6,2,9,1,3,7,5]
def insertion_sort(array):
n = len(array)
for i in range(1, n):
for j in range(i, 0, - 1):
if array[j - 1] > array[j]:
array[j - 1], array[j] = array[j], array[j - 1]
print(array[:i+1])
print("before: ",array)
insertion_sort(array)
print("after:", array)결과
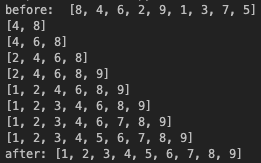
삽입 정렬 또한 선택 정렬과 버블 정렬과 마찬가지로 O()의 시간복잡도를 가진다.
병합 정렬
- 분할 정복과 재귀를 이용한 알고리즘이다.
- 반으로 쪼개고 다시 합치는 과정에서 그룹을 만들어 정렬하게 되며 이 과정에서 개의 공간이 필요하다.
분할 정복:문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략
과정
- 리스트의 길이가 0 또는 1이면 이미 정렬된 것으로 본다.
- 정렬되지 않은 리스트를 절반으로 잘라 비스스한 크기의 두 부분 리스트로 나눈다.
- 각 부분 리스트를 재귀적으로 병합 정렬을 이용해 정렬한다.
- 두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.
파이썬 예제 코드
array = [8,4,6,2,9,1,3,7,5]
def merge_sort(array):
if len(array) < 2:
return array
mid = len(array) // 2
low_arr = merge_sort(array[:mid])
high_arr = merge_sort(array[mid:])
merged_arr = []
l = h = 0
while l < len(low_arr) and h < len(high_arr):
if low_arr[l] < high_arr[h]:
merged_arr.append(low_arr[l])
l += 1
else:
merged_arr.append(high_arr[h])
h += 1
merged_arr += low_arr[l:]
merged_arr += high_arr[h:]
print(merged_arr)
return merged_arr
print("before: ",array)
array = merge_sort(array)
print("after:", array)결과
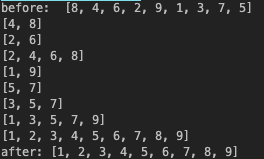
병합 정렬은 O()의 빠른 속도를 가진다.
퀵 정렬
- 병합 정렬과 같이 분할 정복 알고리즘 중 하나이나, 병합 정렬과 달리 퀵 정렬은 리스트를 pivot을 기준으로 비균등하게 분할한다.
- 추가적인 메모리 공간이 필요 없다는 장점을 가졌다.
과정
- 리스트 안에 있는 한 요소를 선택한다. 이렇게 선택된 요소를 피벗(pivot)이라고 한다.
- 피벗을 기준으로 피벗보다 작은 요소들은 모두 피벗의 왼쪽으로 옮겨지고 피벗보다 큰 요소들은 모드 피벗의 오른쪽으로 옮겨진다.
- 피벗을 제외한 왼쪽 리스트와 오른쪽 리스트를 다시 정렬한다.
- 분할된 부분 리스트에 대하여 순환 호출을 이용하여 정렬을 반복한다.
- 부분 리스트에서도 다시 피벗을 정하고 피벗을 기준으로 2개의 부분 리스트로 나누는 과정을 반복한다.
- 부분 리스트들이 더이상 분할이 불가능할 때까지 반복한다.
- 리스트의 크기가 0이나 1이 될 때까지 반복한다.
파이썬 예제 코드
array = [8,4,6,2,5,1,3,7,9]
def quick_sort(array):
if len(array) <= 1:
return array
pivot = len(array) // 2
front_arr, pivot_arr, back_arr = [], [], []
for value in array:
if value < array[pivot]:
front_arr.append(value)
elif value > array[pivot]:
back_arr.append(value)
else:
pivot_arr.append(value)
print(front_arr, pivot_arr, back_arr)
return quick_sort(front_arr) + quick_sort(pivot_arr) + quick_sort(back_arr)
print("before: ",array)
array = quick_sort(array)
print("after:", array)결과

- 병합 정렬과 마찬가지로 O()의 시간 복잡도를 가진다.
- 다른 정렬 알고리즘보다 빠르며, 많은 언어의 정렬 내장 함수로 퀵 정렬을 사용한다.
파이썬 정렬 라이브러리
sorted()
파이썬은 기본 정렬 라이브러리인 sorted() 함수를 제공한다.
특징
- 병합 정렬을 기반으로 만들어졌다.
- 병합 정렬은 일반적으로 퀵 정렬보다 느리지만 최악의 경우에도 시간 복잡도 O()을 보장한다.
- 정렬된 결과를 리스트 자료형으로 반환한다.
sort()
- 리스트 객체의 내장 함수
- 리스트 변수가 있을 때 내부 원소를 바로 정렬한다.
- 별도의 정렬된 리스트가 반환되지 않고 내부 원소가 바로 정렬된다.
array = [ 7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
# sorted() 정렬 : 정렬된 리스트가 반환됨, array 는 그대로
result = sorted(array)
print(result)
print(array)
# sort() 정렬 : 내부 원소가 바로 정렬됨
array.sort()
print(array)# sorted() 정렬 반환 결과를 담은 result 와 array
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
# sort() 정렬된 array
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]key 값
- sorted()나 sort()를 이용할 때는 key 매개변수를 입력으로 받을 수 있다.
- key 값으로는 하나의 함수가 들어가야 하며 이는 정렬 기준이 된다.
array = [('바나나', 2), ('사과', 5), ('당근', 3)]
# 방법 1 : 함수를 정의한 후 key 값에 넣어주기
def setting(data):
return data[1] # 인덱스 1에 위치한 원소가 반환된다 (key 값 = 2, 5, 3)
result = sorted(array, key = setting)
print(result)
# 방법 2 : 람다함수를 key 값에 넣어주기
result = sorted(array, key = lambda data: data[1])
print(result)[('바나나', 2), ('당근', 3), ('사과', 5)]
[('바나나', 2), ('당근', 3), ('사과', 5)]정렬 라이브러리의 시간 복잡도
- 정렬 라이브러리는 항상 최악의 경우에도 시간 복잡도 O()을 보장한다.

chick! chick!