
React는 CRS(클라이언트 사이드 렌더링)을 사용하기 때문에, 렌더링되기 전까지 내용이 비어있어서 검색 엔진이 웹사이트의 내용을 확인할 수 없어 SEO(검색 엔진 최적화)측면에서 단점이 있다.
React에서 SEO가 어렵다하더라도, 개발자라면 기능 구현을 위해 답을 찾아야하기에 React로 진행한 프로젝트를 진행하면서 공부하고 사용한 검색엔진 최적화 방법에 대해 적어보려한다.
React에서 SEO하는 방법
- SSR (Server Side Rendering)
- 프리 렌더링을 구현하는 패키지등 이용
- 검색 엔진을 위한 메타 태그 최적화
4.robots.txt 활용하기
SSR (Server Side Rendering)
서버사이드 렌더링은 웹페이지를 서버에서 렌더링하여 클라이언트에게 전송하는 방식으로 서버에서 이미 웹페이지가 완성되어져서 전송하기 때문에 검색엔진의 크롤링이 쉽다.
React에서 SSR을 사용하는 대표적인 방법은 Next.js를 사용하는 것이다.
Next.js는 React 기반의 웹 프레임 워크로 SSR과 SSG(정적 사이트 생성)를 지원하고 내장된 head컴포넌트를 통해 SCO 메타 정보를 관리할 수 있다.
아직 Next.js를 공부하지 못해서 프로젝트에서는 Next.js를 이용한 SSR은 진행하지 않았다.
프리 렌더링 패키지 : react-snap
react-snap은 웹 애플리케이션을 정적 HTML로 사전 렌더링 하는 라이브러리이다.
reactSnap이라는 옵션을 통해 라우트별로 사전 렌더링 파일을 만들 수 있다.
“reactSnap”: { “include”: [ “/”, “/about”, “/contact” ] }그러나 문제는 마지막 업데이트가 3년전으로 업데이트가 멈추어 있고 react18 버전과 충돌이 생길 수 있어 이를 위해서는 react17로 다운 그레이드를 해야한다. 그리고 해당 패키지를 빌드 후에 앱을 크롤링하고 각 페이지의 HTML을 스냅샷으로 저장하기 때문에 서버 측에서 데이터를 받아오는 경우에는 적합하기 않다.
notion 프로젝트와 react-snap
프로젝트에서 react-snap을 시도했지만, 원하는대로 페이지별로 HTML이 사전 렌더링 되지 않는 오류가 있었다.
react18로 진행된 notion 프로젝트는 유저가 페이지를 생성하는 기능을 제공하기 때문에 route가 정적으로 있는 것이 아니라 페이지에 대한 route가 페이지들을 담고 있는 상태의 변화에 따라 생성되거나 삭제되며, useEffect를 사용해 렌더링 시 화면에 표시되는 페이지(즐겨찾기 페이지나 유저가 작성한 첫 페이지)를 결정해 화면에 구현하도록 했다.
useEffect(()=>{
if(화면을_처음_열었을때){
if(즐겨찾기_페이지_유무){
navigate(즐겨찾기_페이지_중_첫_페이지 )
}else{
navigate(첫_페이지)
}
}
},[])
//....
<Routes>
{pages.map((p) => (
<Route
key={`page_${p.id}`}
path={makeRoutePath(p.id)}
element={<EditorContainerprops={...props} />}
/>))
}
//페이지 경로가 유효하지 않을 경우, NonePage로 이동
<Route path={"*"} element={<NonePage addPage={addPage} />} />
</Routes>추정컨대, react-snap이 재대로 실행되지 않은 이유는 해당 프로젝트가 react18을 사용했거나 reducx상태로 가져오는 pages상태와 map을 이용해 Route를 구성한 것에 있지 않을까 한다.
react-snap의 오류를 해결하려고 노력했지만, react18과 충돌이 있으며 3년간 업데이트가 없는 패키지를 사용하려고 시간을 쏟는게 맞는 걸까 하는 의구심이 들어서 react-snap을 사용하지 않기도 했다.
사전 렌더링을 위해 react-snap을 사용하는 것이기 때문에 Next.js를 공부한 후 Next.js를 이용해 사전 렌더링을 시도해보고 싶다는 생각을 했다.
메타 태그 최적화 :react-helmet-async
메타 태그와 SEO
메타 태그를 웹 페이지에 대한 설명으로 검색엔진에게 페이지에 대한 설명을 제공한다.
메타 태그는 HTML의 head 태그 안에 위치하고, name과 contents로 메타 정보를 명시한다.
| 태그 | 설명 |
|---|---|
| title 태그 | 페이지의 제목으로 meta tag의 name="title"도 있지만, 보통 title 태그를 많이 사용 |
<meta name="keyword" content=""/> | 페이지의 주요 키워드 |
<meta name="description" content=""/> | 페이지에 대한 간단한 설명 |
<meta name="robots" content=""/> | 검색엔진이 페이지를 크롤링하거나 인덱싱할수 있는지 여부를 지정 |
<link rel="canotical" href=""/> | 검색 엔진에서 중복되는 페이지를 하다로 취급하도록 지시해서 중복 콘텐츠 문제를 해결하여 웹 페이지의 신뢰성을 높임 |
| 오픈 그래프 태그 | 소셜 미디어에서 링크를 공유할 때 나타나는 미리보기 정보를 제공한다. ex : <meta property="ogtitle" content=""/> |
react-helmet, react-helmet-async
페이지별로 다른 meta 태그를 작성하고 싶었기 때문에 React에서 head를 관리하고 변경할 수 있는 기능을 제공하는 react-helmet-async 패키지를 사용했다.
react-helmet-async는 react-helmet의 단점을 보완한 라이브러리이다.
- react-helemt-async 사용 방법
import React from 'react';
import ReactDOM from 'react-dom';
import { Helmet, HelmetProvider } from 'react-helmet-async';
const app = (
<HelmetProvider>
<App>
<Helmet>
<title> Hello World </title>
<link rel="canonical" href="(https://www.tacobell.com/)" />
</Helmet>
<h1> Hello World </h1>
</App>
</HelmetProvider>
);
ReactDOM.hydrate(app, document.getElementById('app'));-
react-helmet-async를 사용해 메타 태그 생성
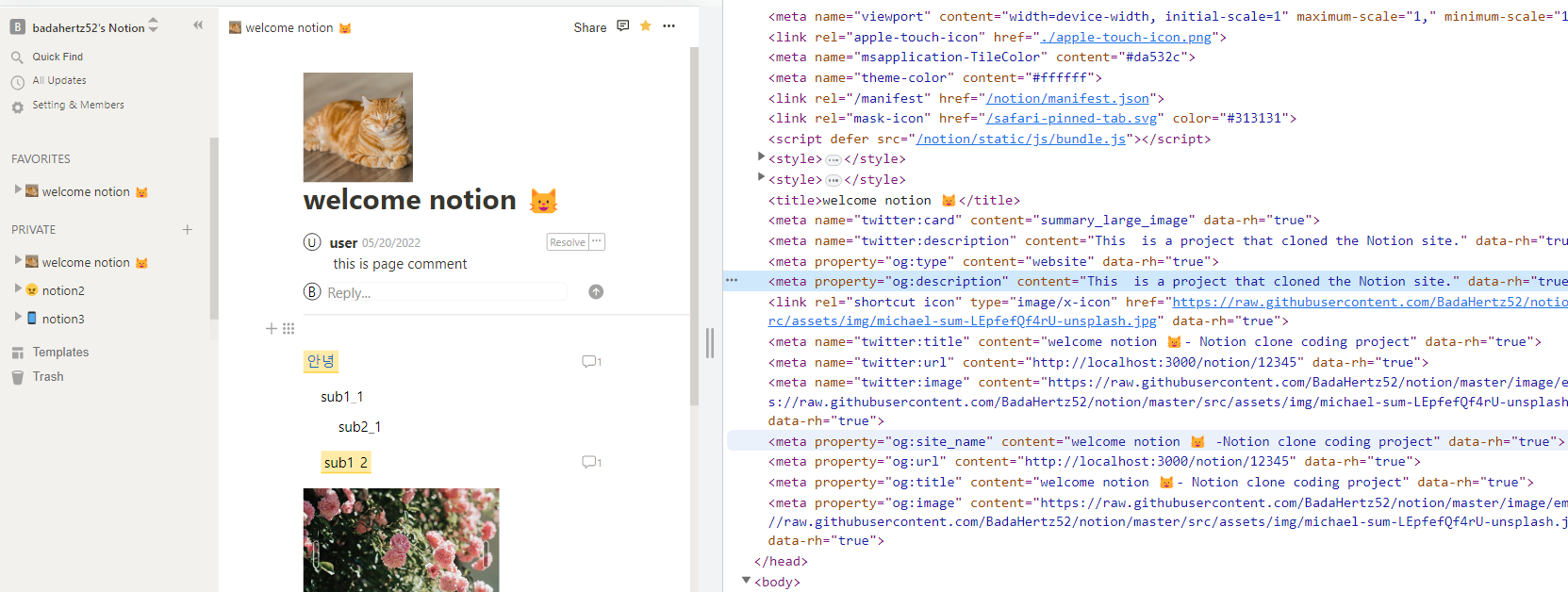
-
react-helmet-async를 사용해 페이지별로 다른 메타 태그
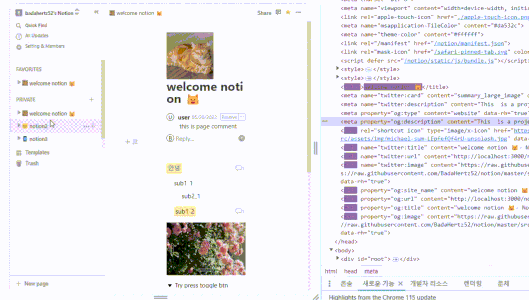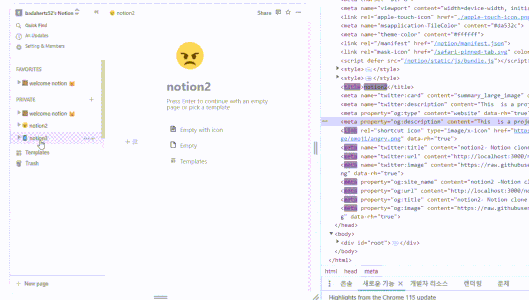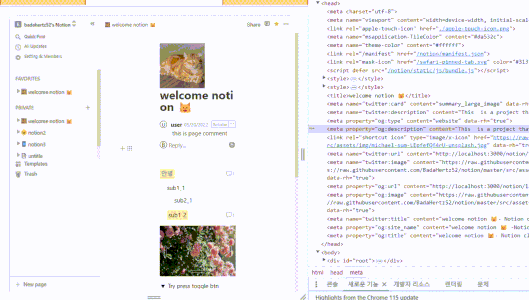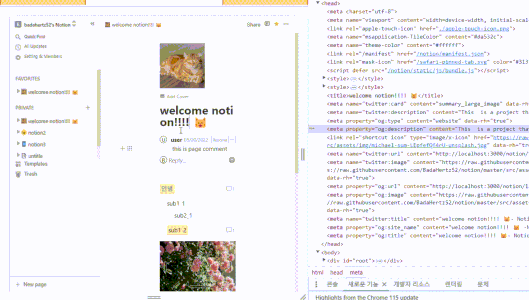
robots.txt
robots.txt는 웹페이지에 대한 검색엔진 크롤러에게 페이지 정보 수집에 대한 규칙을 담은 파일이다.다음의 것들을 사용해 규칙을 만들 수 있다.
- User-agent: 크롤링 규칙을 적용한 검색 로봇을 지정하고 모든 검색로봇을 대상으로 할 경우
*을 작성하면 된다. - Allow: 크롤링을 허용하는 경로를 지정하고 모든 페이지에 대한 크롤릴를 허용할 경우
/을 사용하면 된다. - Disallow : 크롤링을 제한할 경로를 지정한다.
- Sitemap: 사이트에 있는 페이지 목록을 담고 있는 XML 파일인 사이트맵의 위치를 지정한다.
프로젝트에서 사용한 SEO 방법
notion 프로젝트에서 사용한 SEO 방법은 사전렌더링을 할 수 없어서 검색 엔진이 페이지에 대한 정보를 읽을 수 없다는 문제점을 해결하기 위해 public/index.html에 기본적인 해당 프로젝트에 대한 정보를 메타 태그를 작성했고이후에 페이지가 렌더링되면 react-helemt-async라이브러리를 사용해 해당 페이지에 대한 메타태그로 변형하도록 했고 robots.txt로 검색엔진이 해당 프로젝트 내의 모든 페이지에 대해 크롤링 할 수 있도록 했다.
public/index.html : 기본적인 메타 태그 작성
🔽페이지 렌더링🔽
react-helemt-async를 이용해 오픈된 페이지에 맞는 메태 태그로 수정
아쉬운 점 또는 보완하고 싶은 부분은 앞에서 언급했던 사전 렌더링을 하지 못한다는 점이다. index.html에 메타 태크를 작성하였지만 이는 프로젝트에 대한 메타 태그라서, 검색 엔진이 페이지별로 메타 태그를 크롤링할 수 있게 하는 것에는 한계가 있다.
그래서 Next.js를 공부한 후에 만약에 사전 렌러딩을 시도할 기회가 된다면 시도해보고 싶고 이번 계기로 Next.js를 많이 사용해서가 아니라 그 필요성을 느끼고 공부해 보고 싶은 욕심이 생긴것 같다.
자료 출처
검색엔진 최적화 On-page SEO
