
🔎 5주차 학습 목표 및 개요
이번 주는 웹 자동화 도구와 정규표현식으로 다양한 데이터를 수집하고, 이를 SQL에 저장하는 실습을 하였습니다. 또한, 리눅스와 Docker를 활용해 웹 서버(Nginx), 데이터베이스(MySQL), 분석 환경(PySpark + Jupyter)의 컨테이너 기반 구성 방식을 학습하였습니다.
[웹 데이터 수집부터 저장, 가상환경 기반 분석 환경 구성까지 데이터 분석 실무의 전체 흐름을 경험하는 것] 을 목표로 삼았습니다
📚 주요 학습 및 진행 내용 정리 (5주차)
1. 웹 데이터 수집 및 자동화
웹에서 필요한 정보를 추출하고, SQL 데이터베이스에 저장하는 웹 수집부터 저장까지의 전체 흐름을 실습을 통해 익혔다.
- 정규표현식: 이메일, 전화번호 등 특정 패턴을 가진 문자열을 자동으로 추출하는 방법을 학습함.
- 웹 브라우저 자동화(Selenium): 동적 웹 페이지에서 데이터를 추출하는 실습을 하였고, 명시적·암시적 대기 등 안정적인 수집 방식도 배움.
- HTTP 요청 및 비동기 처리: GET, POST 요청의 구조를 이해하고, 동기/비동기 요청 방식 차이를 학습.
- RSS 피드 수집: XML 기반 데이터 포맷에서 필요한 정보를 자동으로 가져오는 실습 진행.
- 이미지 수집: 웹 페이지에서 이미지(URL) 데이터를 추출하고 저장하는 방식도 경험.
- CSV/SQL 저장: 수집한 데이터를 파일(csv)과 DB(SQL)로 저장하는 과정 실습.
2. 리눅스 기초와 파일 조작
가상머신 환경에서 리눅스 기반 시스템을 다루며 기초 명령어부터 파일 생성·전송까지의 흐름을 학습하였다.
- 기본 명령어 학습:
ls,cd,mkdir,vi,cp,mv,rm등 핵심 파일 관리 명령어 연습 - vi 편집기 실습: 리눅스에서 직접 파일을 작성하고 저장하는 편집기 사용법 익힘
- Xshell, Xftp 연동: 가상머신 내 파일을 외부로 내보내는 도구 사용법 실습
3. Docker와 컨테이너 기반 환경 구성
도커를 이용해 웹 서버, 데이터베이스, 분석 환경까지 구축하는 통합 실습을 경험하였다.
- 도커 기본 구조 이해: 이미지, 컨테이너, 볼륨 개념과 작동 방식 파악
- nginx 웹 서버 실습: 도커를 활용해 nginx 기반 웹 서버를 구동하고 HTML 파일을 수정해 보는 실습 진행
- MySQL 컨테이너 실행 및 연동: 도커를 통해 MySQL 컨테이너를 실행하고 SQL 쿼리를 직접 작성해 데이터 삽입
- 파이스파크 분석 환경 구성: 도커 환경에 주피터 노트북과 파이스파크를 포함시켜 분석 환경을 구축함
- GitHub 연동: 컨테이너 안에서 GitHub 레포지토리와 연동하여 개발 결과물을 관리하는 방법을 학습
4. 웹 서비스와 서버 동작 원리 이해
단순 웹 스크래핑을 넘어서, 웹서비스가 어떻게 동작하는지에 대한 전반적인 구조를 학습하였다.
- IP와 포트 개념: 클라이언트와 서버 간 통신이 어떻게 이루어지는지 이해
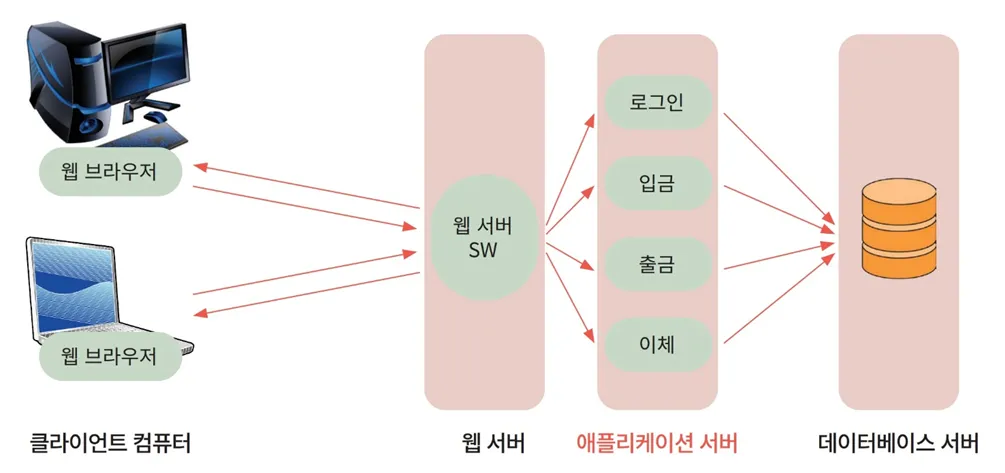
- 웹서버와 앱서버의 역할 분리: nginx는 정적 컨텐츠를, 앱서버는 동적 처리를 담당한다는 개념을 습득
- 전체 웹 서비스 흐름: 요청 → 라우팅 → 응답까지의 전체 구조를 nginx 실습을 통해 구체적으로 파악
🎮 실습/과제 수행 및 문제 해결 과정
이번 주에 실습하면서 겪었던 어려움이나 궁금증의 해결 과정을 기록하였습니다
다음은 웹크롤링 실습을 수행하면서 겪었던 문제점 입니다
Webull 사이트에서 주식 거래 데이터를 스크래핑하여 CSV 파일과 SQL 데이터베이스에 저장하는 실습을 진행하였습니다.
처음에는 단순히 웹 URL을 불러와 BeautifulSoup을 사용해 HTML에서 데이터를 추출하려고 했으나, 해당 페이지가 동적 웹페이지라는 점을 고려하지 못하였습니다. 이로 인해 데이터를 정상적으로 가져오지 못하는 문제가 발생하였습니다.
이후 웹페이지가 JavaScript로 렌더링되는 구조임을 파악하고, Selenium을 활용해 먼저 페이지를 로드한 뒤, BeautifulSoup을 통해 데이터를 추출하는 방식으로 접근을 수정하였습니다.
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
url = 'https://www.webull.com/quote/us/gainers/1m'
driver.get(url)
time.sleep(5)
# page source
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Company name - data check
company_tags = soup.select("p.tit.bold")
for tag in company_tags:
print(tag.text.strip())
driver.quit()데이터를 저장하기 전에는 속성별로 데이터를 직접 확인하여 어떤 형식으로 존재하는지 파악하였습니다. 특히 변동률, 시가총액 등의 값 뒤에 %, B(billion), M(million) 등의 단위가 붙어 있어, 실수형으로 저장하기 위해 문자열에서 단위를 제거할 필요가 있었습니다.
처음에는 이를 어떻게 처리해야 할지 막막했지만, 아래와 같은 전처리 함수를 작성하여 단위를 제거하고 실수형으로 변환하는 데 성공하였습니다.
# data preprocessing
def parse(text):
if text.endswith("B"):
return float(text[:-1]) * 1_000_000_000
elif text.endswith("M"):
return float(text[:-1]) * 1_000_000
elif text.endswith("K"):
return float(text[:-1]) * 1_000
else:
return float(text)데이터가 잘 정제된 것을 확인한 뒤, CSV 파일로 저장하고 SQL 데이터베이스에도 삽입하는 과정을 진행하였습니다. 이 실습을 통해 웹에서 데이터를 수집하고, 분석 가능한 형식으로 가공하여 저장하는 전 과정을 직접 경험할 수 있었습니다.
rows = soup.select("div.table-body > div.table-row")
for row in rows:
try:
name = row.select_one("p.tit.bold").text.strip()
price = row.select_one("div:nth-child(5) > span").text.strip()
change = parse(row.select_one("div:nth-child(4) > div > span").text.strip().replace("%", "").replace("+", ""))
high = row.select_one("div:nth-child(6)").text.strip()
low = row.select_one("div:nth-child(7)").text.strip()
volume = parse(row.select_one("div:nth-child(8) > div > span").text.strip())
market_cap = parse(row.select_one("div:nth-child(11) > div > span").text.strip())
print(f"회사: {name}, 현재가: {price}, 변동률:{change}, 고가: {high}, 저가: {low}, 거래량: {volume}, 시가총액: {market_cap}")
except AttributeError:
continue 다음은 Docker와 Nginx의 개념이 잘 이해되지 않아 따로 정리해 본 내용입니다.
Docker는 프로그램이나 운영체제의 차이에 관계없이, 누구나 동일한 환경에서 프로그램을 실행할 수 있도록 해주는 가상화 플랫폼입니다. 이를 통해 개발 환경 구성과 배포가 훨씬 간편해지며, 실행 오류나 버전 차이 문제를 줄일 수 있습니다.
Docker에서는 컨테이너를 통해 프로그램을 서로 독립된 환경에서 실행할 수 있어, 애플리케이션 간 충돌 없이 효율적인 관리가 가능합니다.
한편, Nginx는 대표적인 웹 서버로서, 다수의 컨테이너가 실행 중일 때 외부 요청을 받아 적절한 컨테이너로 라우팅하는 역할을 수행합니다.
즉, Docker 환경에서 Nginx는 프록시 서버로 동작하며, 클라이언트 요청을 각각의 컨테이너로 분산시켜주는 중간 연결자 역할을 합니다.
🔮5주차 주간 회고 (4L)
💎 Liked (좋았던 점)
- 평소 궁금했던 웹 데이터 수집부터 SQL 저장까지의 전체 흐름을 직접 실습하면서, 실무에 바로 적용 가능한 역량을 기를 수 있어 매우 만족스러웠다.
- 단순 텍스트뿐 아니라 이미지나 RSS 피드, 동적 웹까지 수집 가능하다는 것을 체험하면서 웹 크롤링의 확장성에 대한 감을 얻었다.
- 도커와 가상머신의 차이, 컨테이너의 개념, 그리고 nginx를 이용한 웹서버 구성 등의 시스템 관련 개념이 점점 명확해지고 있다는 점이 인상적이었다.
- 도커를 통해 MySQL, PySpark, GitHub 환경을 구성하고 연동하는 일련의 과정을 직접 따라해보면서 기술을 통합적으로 익힐 수 있었다.
🌱 Learned (배운 점)
- 정규표현식을 통해 텍스트 데이터에서 원하는 패턴을 추출하는 방법을 익힘.
- 웹 스크래핑 기초부터 고급 실습까지: 셀레니움을 통한 동적 웹 수집, HTTP 요청 방식(GET, POST), 명시적/암시적 대기 등 실전 크롤링 흐름 학습.
- SQL 연동 및 저장: 수집한 데이터를 CSV뿐 아니라 SQL DB로 저장하는 실습 경험.
- 도커 개념 및 활용: 이미지, 컨테이너, 볼륨, nginx 웹서버, MySQL 서버 등 Docker를 활용한 다양한 실습.
- 웹 구조 이해: 웹서버(Nginx), 앱서버, 클라이언트의 동작 원리를 기반으로 전체 서비스 구조 이해.
- GitHub와 가상환경 연동: Docker 환경에서도 GitHub와 연동해 코드 및 작업물을 관리하는 방법 학습.
💡 Lacked (부족했던 점)
- SQL 저장 시 데이터 타입 변환 전처리 실수 (예: 시가총액을 문자열로 저장)
- 일부 동적 웹페이지 처리 시 셀레니움 사용을 잊고 진행, 데이터 누락 발생
- nginx의 역할이나 리눅스 명령어에 대해 아직 낯선 점이 많았음
- Docker와 GitHub 연동 시 레포지토리 관리 실수로 기존 저장소의 파일까지 함께 업로드되는 문제 발생
📌 Longed for (바라는 점 / 다음 목표)
- 웹 크롤링, SQL 저장, GitHub 연동까지 전체 파이프라인을 직접 세팅해 재현해보며 반복 숙달
- 다른 한국 웹사이트나 비정형 구조 페이지를 직접 크롤링하며 실전 연습 강화
- 리눅스 명령어, nginx, Docker 구성 흐름을 노션에 정리하며 다시 복습
- Docker + PySpark + GitHub 세팅을 집 환경에서도 그대로 복제하고 활용하기
📆 이번 주말 학습 계획
이번 주말에는 정보처리기사의 필기 시험을 대비하여 5과목 이론 스터디와 5과목 기출문제 3개년을 풀 계획이며, 가상환경을 이용하여 Docker의 컨테이너에서 pyspark 활용법을 익힐 예정입니다. 추가로 C/Java의 문법기초를 스터디 할 계획입니다.

블로그 잘 봤어요! 친하게 지내요^^~