1. head(n), limit(n) 차이
- pdf의 head(N)는 Dataframe의 선두 N개 Record를 가지는 DataFrame을 반환
- sdf의 head(N)는 DataFrame의 선두 N개 Row Object를 list로 반환.
- sdf의 limit(N)가 DataFrame의 선두 N개 Record를 가지는 DataFrame을 반환.
- pdf는 print() 적용 시 DataFrame의 내용을 출력하지만 sdf는 DataFrame의 schema만 출력
a. PDF에 head(n) 적용 = 선두 n개의 데이터프레임 형태 변환
pdf - head()
# pandas DataFrame.head(N)는 선두 N개 Record를 가지는 DataFrame 반환
print(type(titanic_pdf.head(10)))
# Pandas DataFrame은 print()로 DataFrame의 내용을 출력.
print(titanic_pdf.head(10))- 선두 n개를 데이터 프레임 형태로 반환

b. SDF에 head(n) 적용 = 선두 n개의 row object를 list로 반환
sdf - head()
# spark DataFrame의 head(N)는 DataFrame의 선두 N개 Row Object를 list로 반환.
print(type(titanic_sdf.head(10)))
print(titanic_sdf.head(10))- 선두 n개의 자바 로우 오브젝트를 리스트 형태로 반환

c. sdf에 limit(n) 적용 = 데이터 프레임의 스키마 출력
sdf - limit()
# spark DataFrame의 limit(N)은 DataFrame의 선두 N개 Record를 가지는 DataFrame 반환.
print(type(titanic_sdf.limit(10)))
# spark DataFrame은 pandas와 다르게 print() 호출 시 값을 출력하지 않고 DataFrame 스키마 출력
print(titanic_sdf.limit(10))- 데이터 프레임의 스키마를 출력해 줌

sdf - show()
# spark DataFrame의 내용을 출력하기 위해서는 show() 메소드를 사용해야 함.
print(titanic_sdf.limit(10).show())
titanic_sdf.limit(10).show()- show() 입력하면 데이터프레임 형태의 로우 확인 가능
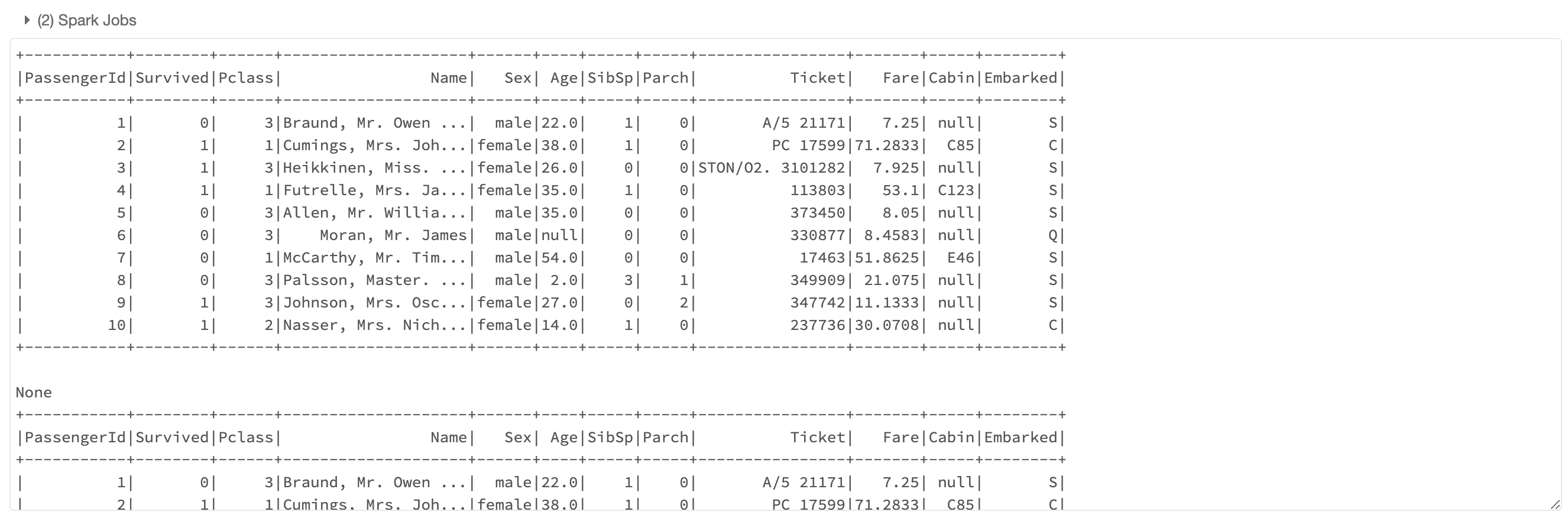
# Databricks의 display()는 spark DataFrame의 내용을 출력할 수 있음.
display(titanic_sdf)
# 메모리 절약을 위해 limit() 사용이 바람직
display(titanic_sdf.limit(10))- 데이터브릭스에서 제공하는 display로 sdf의 내용 출력 가능
2. printSchema(), describe() <-> info(), shape()
- pandas DataFrame의 info()는 컬럼명, data type과 not null 건수를 함께 출력
- spark DataFrame의 info() 메소드가 없으며 대신 printSchema() 메소드로 스키마(컬럼명, data type)만 출력
- not null 건수를 위해서는 별도의 SQL성 쿼리 작성 필요.
- spark dataframe은 pandas dataframe과 비슷하게 describe()를 통해 모든 컬럼값들의 건수/평균/표준편차/최소값/최대값 등의 정보를 확인할 수 있음. 다만 percentile값을 만들지 않음.
- pandas dataframe과 다르게 describe()시 숫자형 컬럼 뿐만 아니라 문자형 컬럼에 대해서도 건수/평균/표준편차/최소값/최대값 조사
a. pdf의 info()에 대응하는 printSchema()
pdf - info()
- 메서드 내에 null 값의 개수를 계산하는 로직이 포함되어 있음

sdf - printSchema()
- 메서드 내에 null 값에 대한 로직은 없어서 따로 확인해야 함

sdf - null 값 확인
# SQL의 count case when과 유사한 로직으로 null 값을 포함한 컬럼 확인하기
from pyspark.sql.functions import count, isnan, when, col
titanic_sdf.select([count(when(isnan(c) | col(c).isNull(), c)).alias(c) for c in titanic_sdf.columns]).show()- 모든 컬럼들을 row 단위로 null인지 확인해서 count 하는 방식

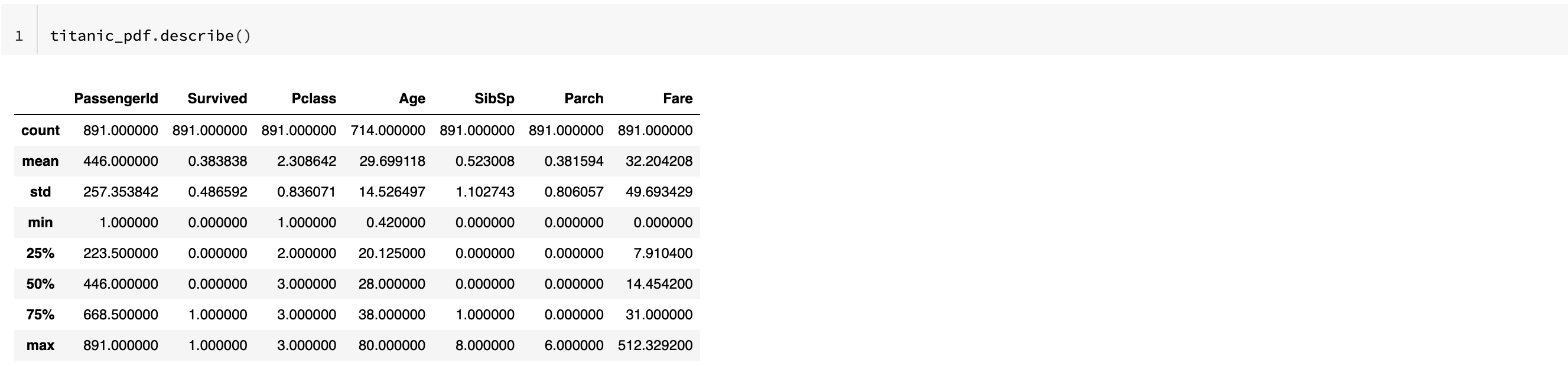
b. describe() 차이
pdf - describe()
- percentile 값도 확인 가능하고 number 형 컬럼만 자동 선택하여 확인
sdf - describe()
- percentile 값 확인 불가하며, 문자열 컬럼에 대해서도 계산이 됨

sdf - 수치형 자료만 확인
# number형 컬럼들에 대해서만 describe()수행할 수 있도록 select 컬럼 filtering 적용.
number_columns = [column_name for column_name, dtype in titanic_sdf.dtypes if dtype != 'string']
print(number_columns)
titanic_sdf.select(number_columns).describe().show()c. pdf의 shape() sdf에서의 적용
pdf - shape()
- pdf의 shape는 컬럼 개수와 로우 개수를 빠르게 세줌

sdf 적용
- sdf에서는 shape()가 없어서, 아래와 같이 적용 필요


글쓰는 데이터 분석가