Spark 데이터프레임의 컬럼과 레코드 삭제
요약
- 판다스 데이터프레임은 drop() 메소드 내의 axis 인자로 (0은 로우, 1은 컬럼) 로우와 컬럼 모두 삭제가 가능하나 Spark Dataframe의 drop() 메소드는 컬럼 삭제만 가능하다.
- Spark 데이터프레임의 drop() 메소드 단일 혹은 여러개의 컬럼 삭제가 가능하나, 여러개의 컬럼 삭제 시에는 list 입력이 불가하고, 개별 컬럼이 입력 되어야 한다.
- Spark 데이터프레임은 특정 조건에 맞는 로우 삭제가 어려워서, 삭제 대신 filter() 메소드를 이용하여, 해당 조건에 맞지 않는 로우를 필터링 해서 반환하는 형태로 작업한다.
- Pandas의 None 값은 Null을 의미하여 Spark에서는 null로 변환됨. 값이 있는 레코드는 dropna() 메소드 또는 DataFrame.na.drop()을 이용하여 삭제 할 수 있음. 또는 filter() 조건에서 Not null조건으로 다시 만들어 낼 수 있다.
- DataFrame.na는 DataFrameNaFunctions 객체다.
a. 판다스의 drop()
- 레퍼런스: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html
- 판다스의 drop()은 axis 인자를 통해 로우와 컬럼 삭제 가능
- pandas(axis=0, how='any', thresh=None, subset=None, inplace=False)
## axis = 0 (로우), axis = 1 (컬럼)
titanic_pdf_dropped = titanic_pdf.drop('Name', axis=1, inplace=False)
display(titanic_pdf_dropped.head())
display(titanic_pdf.head())b. 스파크 drop() - 기본 용법
-
레퍼런스: https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrame.drop.html
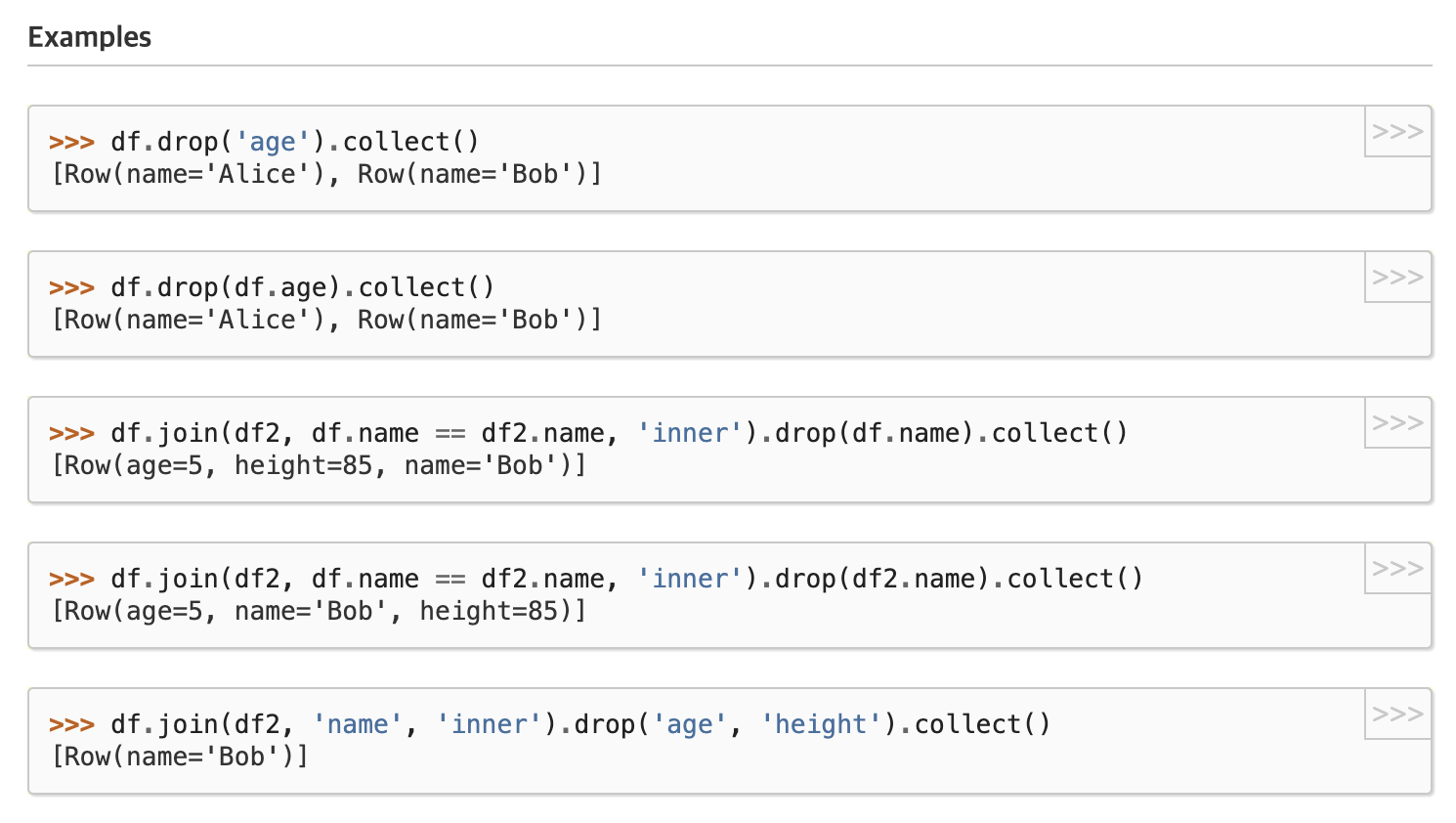
-
단일 컬럼명 혹은 col() 형태의 컬럼명 입력하여 드롭
-
컬럼이 존재하지 않아도 오류 나지 않고 수행되는 점 주의
## 라이브러리 로드
from pyspark.sql.functions import col
## copy로 받기
titanic_sdf_copied = titanic_sdf.select('*')
## 단일 컬럼 삭제.
## drop() 메소드 인자로 단일 컬럼명 문자열, 또는 컬럼명 컬럼형을 입력.
titanic_sdf_copied = titanic_sdf_copied.drop('Name')
titanic_sdf_copied = titanic_sdf_copied.drop(col('Sex'))
titanic_sdf_copied.limit(10).show(truncate=False)c. 스파크 drop() - 여러 컬럼 삭제
- 여러개의 컬럼 삭제시에는 list가 아닌 개별 컬럼명 입력
- 여러개의 컬럼들을 삭제 시 컬럼형 인자는 불가
- 여러개의 컬럼들을 삭제 시 list 입력은 불가
- *으로 리스트 하위의 인자를 받아서, 컬럼 삭제 가능
from pyspark.sql.functions import col
## 여러개의 컬럼을 삭제할 시 list가 아니라 단일 컬럼명들을 각각 인자로 넣어 주어야 함.
titanic_sdf_copied.drop('Age', 'SibSp').limit(10).show()
## 아래는 오류 발생. 여러개의 컬럼들을 삭제 시 컬럼형 인자는 안됨.
titanic_sdf_copied.drop(col('Age'), col('SibSp')).limit(10).show()
## 아래는 오류 발생. 여러개의 컬럼들을 삭제 시 list 입력은 안됨.
titanic_sdf_copied.drop(['Age', 'SibSp']).limit(10).show()
## *으로 받아서, 수행
drop_columns = ['Age', 'SibSp']
drop_columns_col = [col('Age'), col('SibSp')]
titanic_sdf_copied.drop(*drop_columns).limit(10).show()
## 하지만 아래는 여전히 오류를 발생 시킴.
titanic_sdf_copied.drop(*drop_columns_col).limit(10).show()d. 스파크 drop() - 특정 조건에 맞는 컬럼 삭제
- 로직 설정하여 조건에 맞는 여러개의 컬럼들을 삭제 가능
- dropna, drop은 subset을 이용하여, 특정 컬럼에 null이 있는 경우만 삭제 가능
## 타입 확인
titanic_sdf_copied.dtypes
# 아래와 같이 logic으로 조건에 맞는 여러개의 컬럼들을 삭제할 수 있음.
drop_string_columns = [ column_name for column_name, column_type in titanic_sdf_copied.dtypes if column_type == 'string']
print('drop 컬럼명:', drop_string_columns)
titanic_sdf_copied.drop(*drop_string_columns).limit(10).show()
# Spark DataFrame은 특정 조건으로 로우를 삭제하기가 어려우므로 filter()로 특정 조건에 해당하지 않는 로우를 걸러내는 방식을 적용.
titanic_sdf_removed_Embarked_C = titanic_sdf.filter(col('Embarked') != 'C')
titanic_sdf_removed_Embarked_C.show()

글쓰는 데이터 분석가