1. 정의
- HTML 파싱 Java 라이브러리
- 주로 정적인 웹 페이지를 파싱하고자 하는 경우
- DOM, CSS 및 jquery와 같은 방법을 사용하여 데이터를 추출하고 조작하는 편리한 API를 제공
Selenium 은 동적 페이지도 크롤링이 가능하다.
2. 사용법
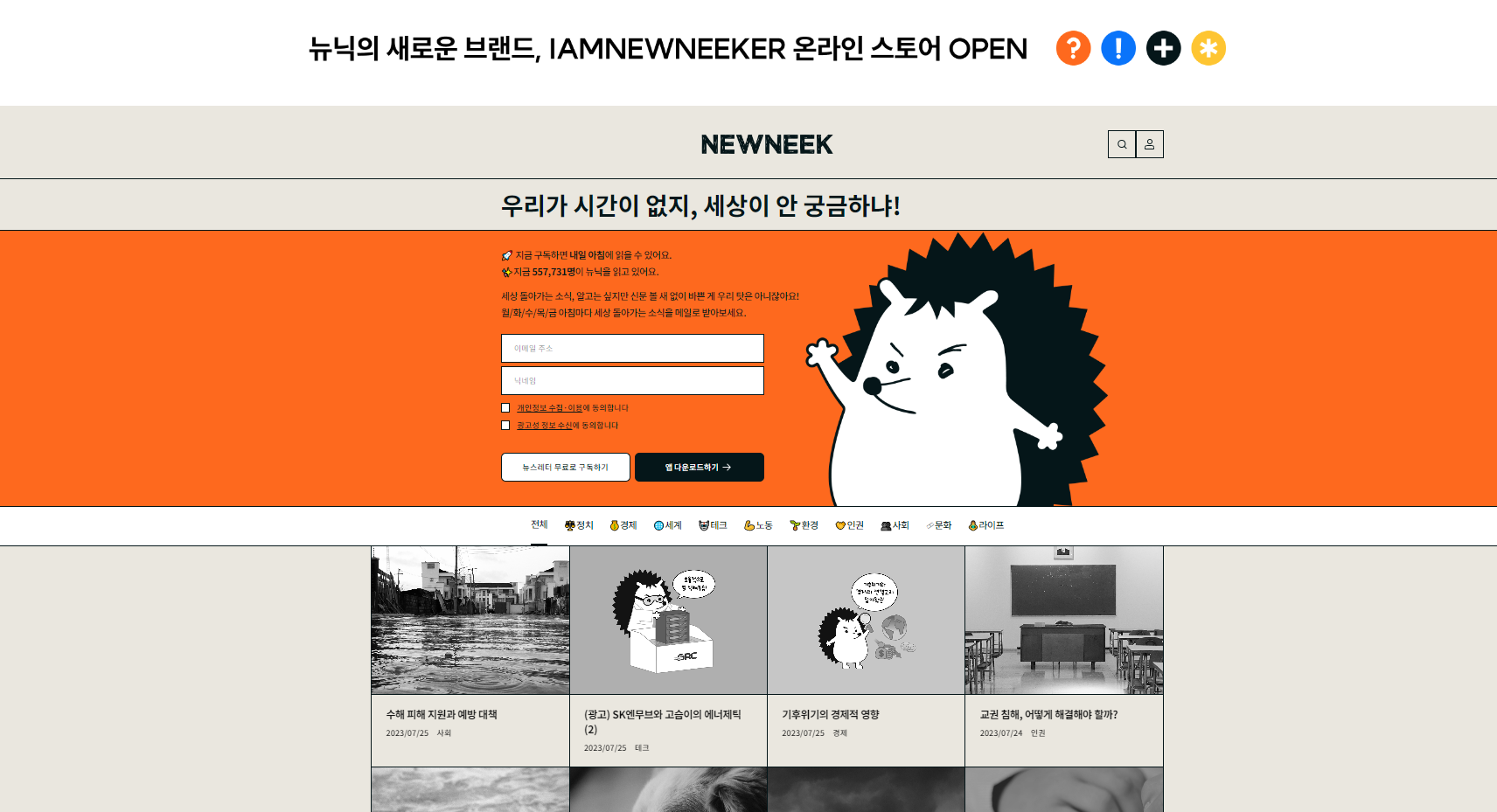
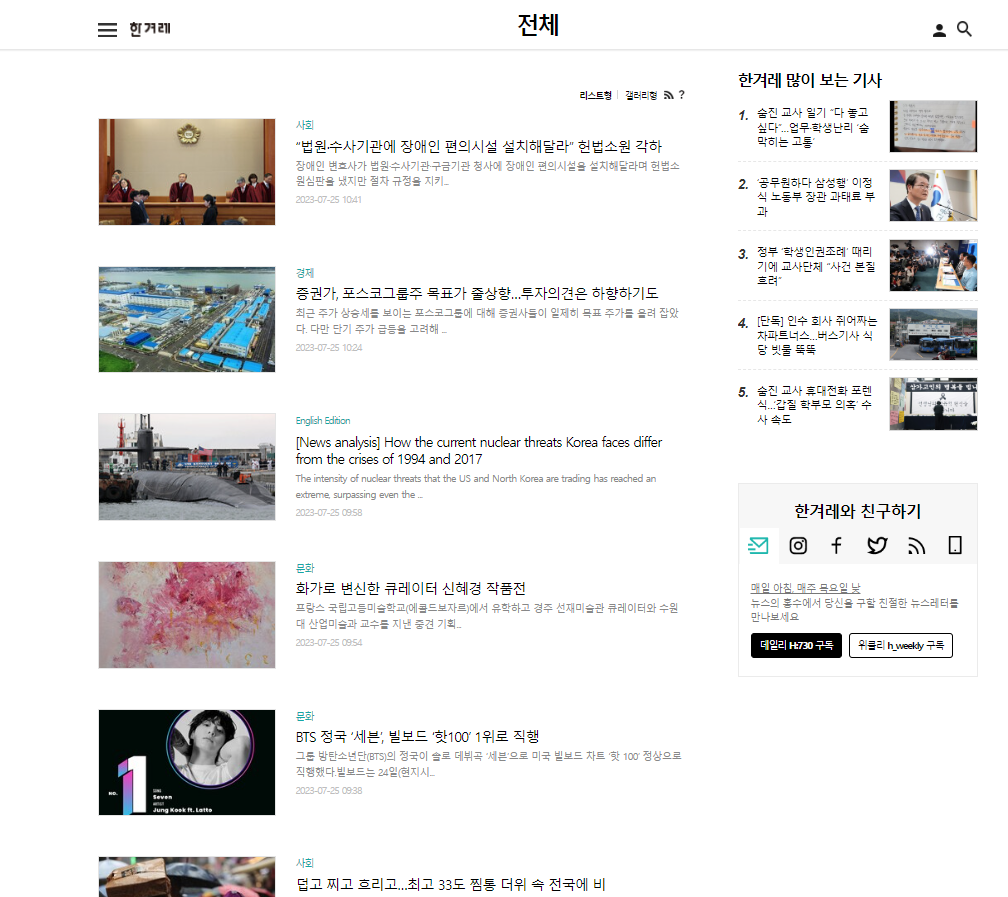
뉴닉 클론코딩을 위해 뉴닉 기사들의 구성을 보고,
섹션, 제목, 내용, 날짜, 이미지를 가져올 수 있는 한겨레 사이트를 크롤링해왔다.
1) 라이브러리
build.gradle
// jsoup 의존성 추가
implementation 'org.jsoup:jsoup:1.15.3'2) 크롤링
crawling 패키지 하위에 CrawlingArticle 클래스를 생성했다.
CrawlingArticle
@Service
@RequiredArgsConstructor
public class CrawlingArticle {
private final ArticleRepository articleRepository;
// 크롤링: 전체 기사 조회
public List<ArticleListResponseDto> saveArticleList() throws IOException {
List<ArticleListResponseDto> articleResponseDtoList = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
String Article_URL = "https://www.hani.co.kr/arti/list" + i + ".html"; // Url 링크도 for문으로 돌릴 수가 있다.
articleResponseDtoList.addAll(processUrl(Article_URL)); // 2.
}
return articleResponseDtoList;
}
// Url 처리하기
private List<ArticleListResponseDto> processUrl(String url) throws IOException {
Document document = Jsoup.connect(url).get(); // url 과 연결
Elements contentList = document.select("div div.section-list-area div.list"); // html 태그로 파싱
List<ArticleListResponseDto> articleResponseDtoList = new ArrayList<>();
// 4.
for (Element contents : contentList) {
String image = contents.select("a img").attr("abs:src"); // 이미지
String title = contents.select("h4 a").text(); // 제목
String date = contents.select("p span").text().substring(0, 10).replaceAll("-", "/"); // 날짜
String tag = contents.select("strong a").text(); // 섹션(태그)
// 내용
String articleLink = contents.select("h4 a").attr("abs:href"); // url에 접근
Document articleDocument = Jsoup.connect(articleLink).get(); // 해당 url 과 connect
String content = articleDocument.select("div div.text").text(); // connect 된 url 안에서 파싱할 정보 선택
Article article = Article.builder()
.image(image)
.title(title)
.tag(tag)
.date(date)
.content(content)
.build();
articleRepository.save(article); // DB 에 저장
articleResponseDtoList.add(new ArticleListResponseDto(article));
}
return articleResponseDtoList;
}
...
} 1. (리펙토링 후, 삭제된 내용)
- GET 조회를 반복할 시, 데어터가 누적되는 것을 방지하고자 모두 삭제하고 다시 DB 에 담는다
2.
- add : 새 노드를 연결하는 메서드
- addAll : ArrayList 에 다른 ArrayList 의 데이터를 통째로 붙이기 위한 메서드
3. (리펙토링 후, 삭제된 내용)
- 크롤링을 했을 때, 각 기사들에 id값이 존재하지 않았으나 Article 엔티티에서 id에 @GeneratedValue(strategy = GenerationType.IDENTITY) 가 설정돼있었다.
- 그러나 이는 id값이 자동 부여가 되면서, GET 조회를 반복할 수록 첫 기사글의 id값은 1-> 46 -> 91 이렇게 삭제된 기사글의 다음 id값이 자동 부여돼버렸다.
- 따라서 @GeneratedValue(strategy = GenerationType.IDENTITY) 설정을 제거하고, currentId 를 1로 선언 및 초기화해서 직접 id값을 부여했다.
4.
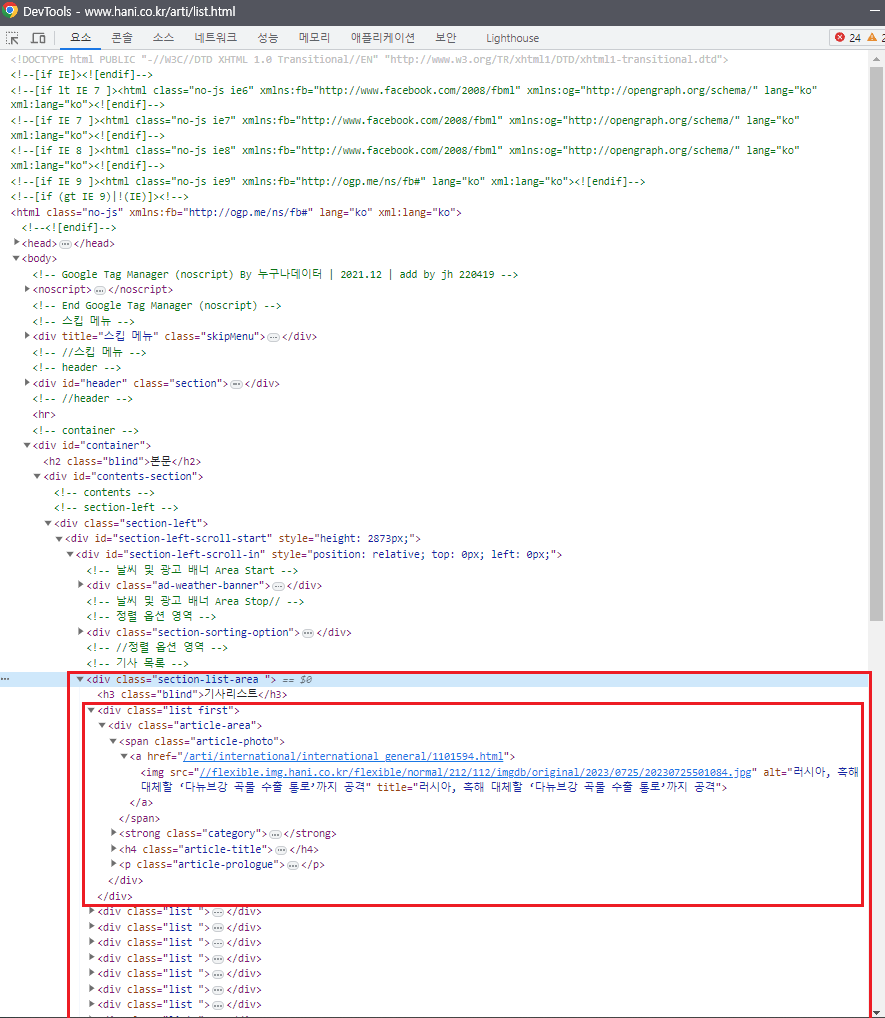
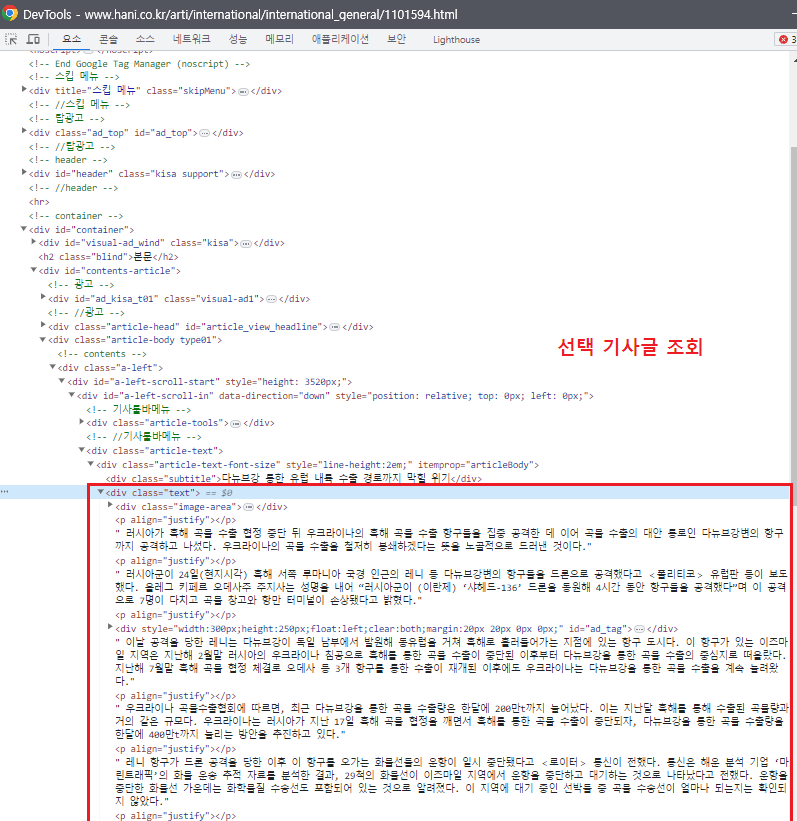
(아래 사진은 위 사진에서 href 링크로 들어간 기사글)
-
div 태그가 달린 section-list-area 안에 div 태그가 달린 기사글들이 있는 형태다.
-
content 는 링크를 타고 거기서 text 를 파싱해온다.
-
Article_URL1, 2 는 전체 기사글을 조회한 url 였으므로, 각 기사글에 대한 url 가 없었다. 있다해도 모든 기사글의 링크를 connnect 하는 것은 불가능했기 때문이다
Data too long for column 에러 메시지
이렇게 content 를 담을 경우 해당 content 컬럼의 길이가 길어진다.
따라서 Article 엔티티의 content 필드에 @Column(length = 5000) 와 같이 길이 제한을 둘 수 있다.
-
ArticleController
// 크롤링: 전체 기사 조회
@GetMapping("/crawling")
public ApiResponseDto<?> saveArticleList() throws IOException {
return new ApiResponseDto<>(HttpStatus.OK, "OK", crawlingArticle.saveArticleList());
}- controller 에서 해당 api로 요청을 보내면, 각각의 responseDto 형식에 맞춰 DB 에 저장된 데이터들을 반환하게 된다.
ArticleListResponseDto
@Builder
@Getter
@NoArgsConstructor
@AllArgsConstructor
public class ArticleListResponseDto {
private Long id;
private String image;
private String title;
private String date;
private String tag;
public ArticleListResponseDto(Article article) {
this.id = article.getId();
this.image = article.getImage();
this.title = article.getTitle();
this.date = article.getDate();
this.tag = article.getTag();
}
}참고: [Springboot] Jsoup 이용하여 웹 크롤링하기
참고: JPA에서 String의 길이 (Length) 변경하기

개발자로 거듭나기!