
Hash란?
도입
- Java 기반의 Spring Boot 프레임워크로 개발을 하던 중, Map 자료구조나, Set 자료구조를 사용해야 될 경우가 있었다.
- 이때 사용하는 Hash는 어떤 것 일까?
Hash를 왜 써야 하고, HashSet의 내부 구현 모습을 간단히 살펴보면서, 어떤식으로 이루어져 있는지 확인 해 보자.
Hash란?
https://ko.wikipedia.org/wiki/%ED%95%B4%EC%8B%9C_%ED%95%A8%EC%88%98
해시 함수(hash function) 또는 해시 알고리즘(hash algorithm) 또는 해시함수알고리즘(hash函數algorithm)은 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수이다.
- 쉽게 설명하면, "Hello World"라는 문자열이 해시 함수에 의해 생성된 고정 길이의 해시 값 (예: 5eb63bbbe01eeed0934c6d3f1e2d2d2)
왜 쓰는거야?
- 해시 알고리즘을 사용하게 되면, 많은 장점들이 있다.
- 빠른 데이터 검색
- 효율적인 데이터 저장
- 중복 데이터 검출
- 데이터 무결성 검증
- 암호화 및 보안
- 데이터의 빠른 색인화
- 이 글에서는 빠른 데이터 검색과 효율적인 데이터 저장 부분에 대해서 키포인트로 코드와 함께 알아보겠다.
분석해보기
요구사항
- 먼저, 이러한 요구사항이 나에게 떨어졌다고 가정하자.
- 데이터에 중복이 없을 것.
- 저장된 데이터의 검색을 할 것.
- 데이터의량은 달라지나, 최소 1만건 이상의 데이터가 저장되고 관리 된다.
- 메모리 용량을 최대한 적게 사용한다.
List로 구현 해 보기.
public class ArrayListMain {
private static final int DATA_COUNT = 100_000;
private static final int MAX_RANDOM = 10000000;
private static final int FIND_VALUE = 10000001;
public static void main(String[] args) {
// ArrayList 테스트
List<Integer> arrayList = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < DATA_COUNT; i++) {
int inputData = random.nextInt(MAX_RANDOM);
if (!arrayList.contains(inputData)) arrayList.add(inputData);
}
arrayList.add(DATA_COUNT/2, FIND_VALUE);
//시간복잡도 O(n)
int findIndex = arrayList.indexOf(FIND_VALUE);
}
}- 10만건의 데이터를 랜덤으로 List 자료 구조에 넣었다.
- 이때,
indexOf를 통해서, Value 값을 찾을때 시간복잡도는 O(n) 이 걸리게 된다. - 또한, 이떄 생성되는 배열의 크기는, 10만보다 크게 생성되어있어, 메모리가 낭비되고 있다.
ArrayList에서는 동적으로 배열을 할당 하기 위해, 내부적으로 배열의 사이즈가 부족할 경우,50% ~ 200%증가시켜서 할당한다.
List 통해, 데이터의 검색을 구현할 경우, 성능적으로 이슈가 걸림을 확인 할 수 있다.
문제 해결
STEP 1) 시간복잡도 해소하기
- 그렇다면, 검색을 O(1)로 개선시키고, 필요없는 메모리를 할당하지 않고 필요한 만큼만 할당해서 사용하면 성능개선에 도움이 될 것 같다.
- ArrayList에서 Index를 활용한 Get 메서드는 O(1)의 시간복잡도를 가지는데, 이를 활용하면 좋은 방법이 될 것이다.
- 즉, {1, 2, 5, 8} 데이터를 저장할 때
- arrayList[0] = 1
- arrayList[1] = 2
- arrayList[2] = 5
- arrayList[3] = 8
- 이렇게 가 아니라, Index 번호와 저장될 Value를 동일하게 만드는 것이다.
- arrayList[1] = 1
- arrayList[2] = 2
- arrayList[5] = 5
- arrayList[8] = 8
- 이렇게 된다면, 8이라는 데이터를 찾고 싶을때, arrayList[8]에 바로 접근하여 사용하면 되므로, 시간복잡도는 O(1)로 굉장히 단축되게 된다.
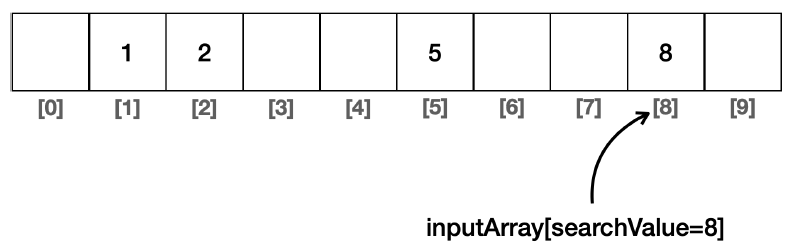
하지만, 이렇게 된다면, 10000 이라는 데이터를 추가하고 싶다면, arrayList가 10000 까지 큰 범위로 할당되어있어야 한다.
따라서 이때, 공간이 많이 낭비된다.
STEP 2) 낭비되는 공간 해소하기
-
step1 을 진행하였다면,
1과10000이라는 데이터를 저장하기 위해서는, arrayList가10000의 사이즈의 배열로 확장되어있어야 한다. -
만약
10000을 다른 숫자로 치환할 수 있으면 어떻게 될까? -
이번에는
1,2,5,8,14,99라는 Values를 저장 시켜 보겠다. -
단, Values 그대로 Index로 사용하지 않고, 모듈러 연산으로 나머지를 구해, 인덱스로 활용하겠다.
Java의 HashSet은 모듈러 연산 시, 배열의 크기로 연산 하지만 (Default 16), 설명을 위해서 10으로 진행한다- 1 % 10 =
1 - 2 % 10 =
2 - 5 % 10 =
5 - 8 % 10 =
8 - 14 % 10 =
4 - 99 % 10 =
9
-
연산으로 나온 값을, Index로 활용하여, 다음과 같이 저장한다.
-
이때, 연산으로 나온 값을 HashIndex 라고 한다.
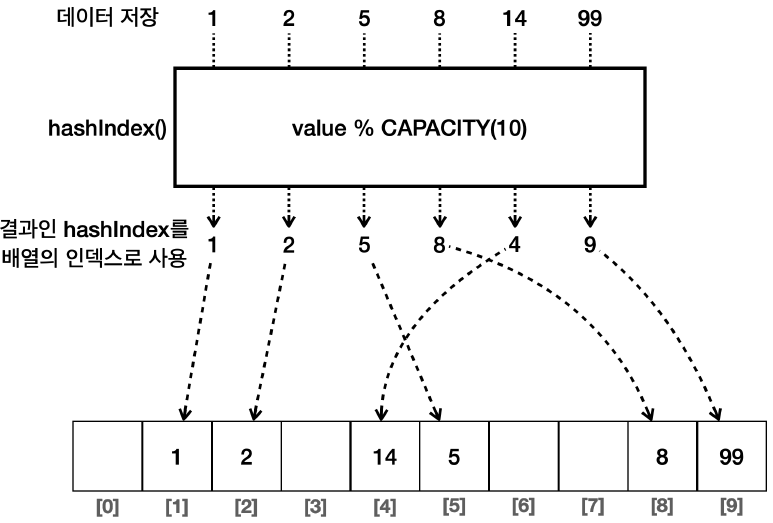
-
이제,
99의 데이터를 넣기 위해 arrayList의 사이즈를99까지 할당하지 않아도 되서 메모리 사용에 굉장히 효율적이게 되었다.
STEP 3) 중복 데이터 발생 시
step2를 거쳤다면, 한가지 문제점이 발생한다. (...사실 아직 문제점이 많다)9와99를 저장하게 되면, 같은arrayList[9]에다가 값을 저장한다는 것이다.
이를 해시 충돌 이라고 한다.
9를 먼저 저장해두고,99를 저장하게 되면,step2의 상황상 둘 중 하나의 데이터는 소실되게 된다.- 따라서, ArrayList안에 Values를 저장해두는 공간을 또다시 배열로 할당해버리는 것이다. 배열 in 배열

이렇게 된다면, 9를 찾을때, arrayList[9] 값 안의 배열의 2번째 값을 찾을 수 있을 것이다. 이때 시간 복잡도는, O(1) 이 걸리지만, 최악의 조건에서는 O(n)이 걸릴 수 있다.
왜? O(n)이 걸릴 수 있나요?
저장하는 데이터가 모두, Index 9에 할당되게 되면, EX) 9, 19, 29, 39, 49...
모든 데이터는 결국 arrayList[9]에서 Full Scan으로 확인해야 되기 때문에 그렇다.
단, 평균적으로 그렇게 저장될 일을 많이 없기 때문에, 신경쓰지 않아도 된다
- 실제로, Java8 이전에는 HashSet의 구현 안에는 LinkedList를 사용하여 내부 Node 들을 관리 하고 있다.
- Java8 이상의 버전에서는, Node와 TreeNode를 사용하여, LinkedList 보다 더 빠른 속도를 지원하고자 적용되어 있다.
다음
다음으로는, HashSet의 일부 기능들을 구현해보며, 기본 Object에서 제공하는 hashCode()와 equals() 메서드의 중요성, 문자열 해싱에 대해서 알아보겠다.
