
Hash
도입
-
사실 나는 Java 개발을 주력으로 하지 않고, C++을 기반으로한 임베이디드 개발자로 활동을 하고 있었다.
-
어쩌다 보니, 웹 관련 공부를 진행하면서 Java 공부를 다시 하고있는데, equals와 hashCode의 중요성에 대해서 질문 받았는데 너무 답변이 길게 나왔다... (주절주절)
-
따라서, 한번 정리 겸 글을 작성한다.
왜?
-
우리는 여러가지 알고리즘 이슈를 해결하며, 최선의 시간/공간 복잡도를 가지는 해결책을 강구하기를 원한다. 알맞은 자료구조의 선정 또한 매우 중요한
Key-Point일 것 이다. -
다음과 같은 개발 요구사항이 생겼다고 가정해보자.
- 요구사항
1. 중복된 요소가 없을 것.
2. 검색, 삭제, 삽입 모두 O(n)의 시간 복잡도를 가질 것.
3. 타입 안정성과, 코드 재사용성을 고려할 것.
4. Hash 충돌을 최대한 해결하여 안정성 있는 구조로 할 것.-
다음과 같은 요구사항이 접수되었다면 HashSet 자료구조를 선택하는것이 현명 할 것이다.
모든 조건에 맞아 떨어지는 자료구조 이기 때문이다. -
하지만, HashSet과 같은 Hash 알고리즘을 사용하는 자료구조를 사용할 때에는 특별히 유의할 점이 있다.
equals, hashCode 메서드 이다.
HashSet으로 뜯어보기
- 나는 equals 를 할때 같은 Human 인스턴스에 이름도
백과로 같으므로, 같은객체라고 판단하여HashSet에add할 경우, 중복으로 저장이 되지 않으면 한다.
public class Human {
public String name;
public Human(String name) {
this.name = name;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "Human{" +
"name='" + name + '\'' +
'}';
}
}
----
public class main {
public static void main(String[] args) {
Human human1 = new Human("백과");
Human human2 = new Human("백과");
Set<Human> humans = new HashSet<>(16);
humans.add(human1);
humans.add(human2);
System.out.println("humans = " + humans);
}
}
humans = [Human{name='백과'}, Human{name='백과'}]- 하지만 결과는
백과의 이름을 가진 두개의 인스턴스를 모두 저장해버린다.
왜?
- 답은, Hash를 사용한 자료구조의
add에 있다. add를 할 경우, 내부 로직에 의해, Hash 알고리즘이 동작하여 저장하게 된다.- 이때,
Hash를 실행하는 메서드는 객체의hashCode()메서드로 실행하게 되는데, 우리는Override를 진행하지 않았기 때문에 최상위 부모인Object의hashCode()가 실행 되게 된다.
실 사용은 HashSet을 하였지만, HashSet의 구현은 HashMap을 통해서 이뤄져서 HashMap 코드를 확인하며 진행하였다.
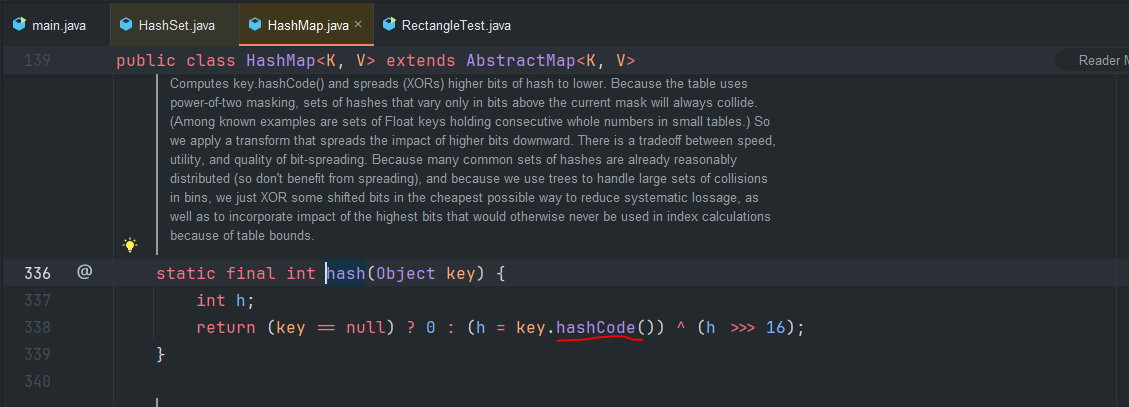
Object의hashCode()는 객체의 참조값을 바탕으로 해시화 시키는데, 이는 객체 human1과 human2는 당연히 다르기 때문에 다른 해시 코드가 실행되는 것이다.
public class main {
public static void main(String[] args) {
Human human1 = new Human("백과");
Human human2 = new Human("백과");
System.out.println("human1.hashCode() = " + human1.hashCode());
System.out.println("human2.hashCode() = " + human2.hashCode());
}
}
==logs==
output
human1.hashCode() = 793589513
human2.hashCode() = 824909230- 따라서 name이 같은 경우에 같은 Hash 값을 가지게 하려면,
hashCode()를Override진행하여, 다음과 같이 동일한 hash값을 가지게 만들어준다. - 동일한 Hash값이 있어야 동일한 Buckets에 들어가게 된다.
public class Human {
public String name;
public Human(String name) {
this.name = name;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "Human{" +
"name='" + name + '\'' +
'}';
}
@Override
public int hashCode() {
return Objects.hashCode(getName());
//Objects Util Class에서는 파라미터 값을 입력하면, 간편하게 Hash값을 만들어주는 메서드를 지원한다.
//물론 이를 따르지 않고, 해시충돌을 방지할 수 있는 Hash 알고리즘을 만든다면 그걸 사용해도 무관하다.
}
}- 그럼 이제 완료된 것일까?
NO!
- main 코드를 돌려보면, 역시 동일하게 중복되어 들어가는 것을 확인 할 수 있다.
- 마찬가지로 조금더 데이터를 추가하는 부분을 살펴보면 답이 나온다.
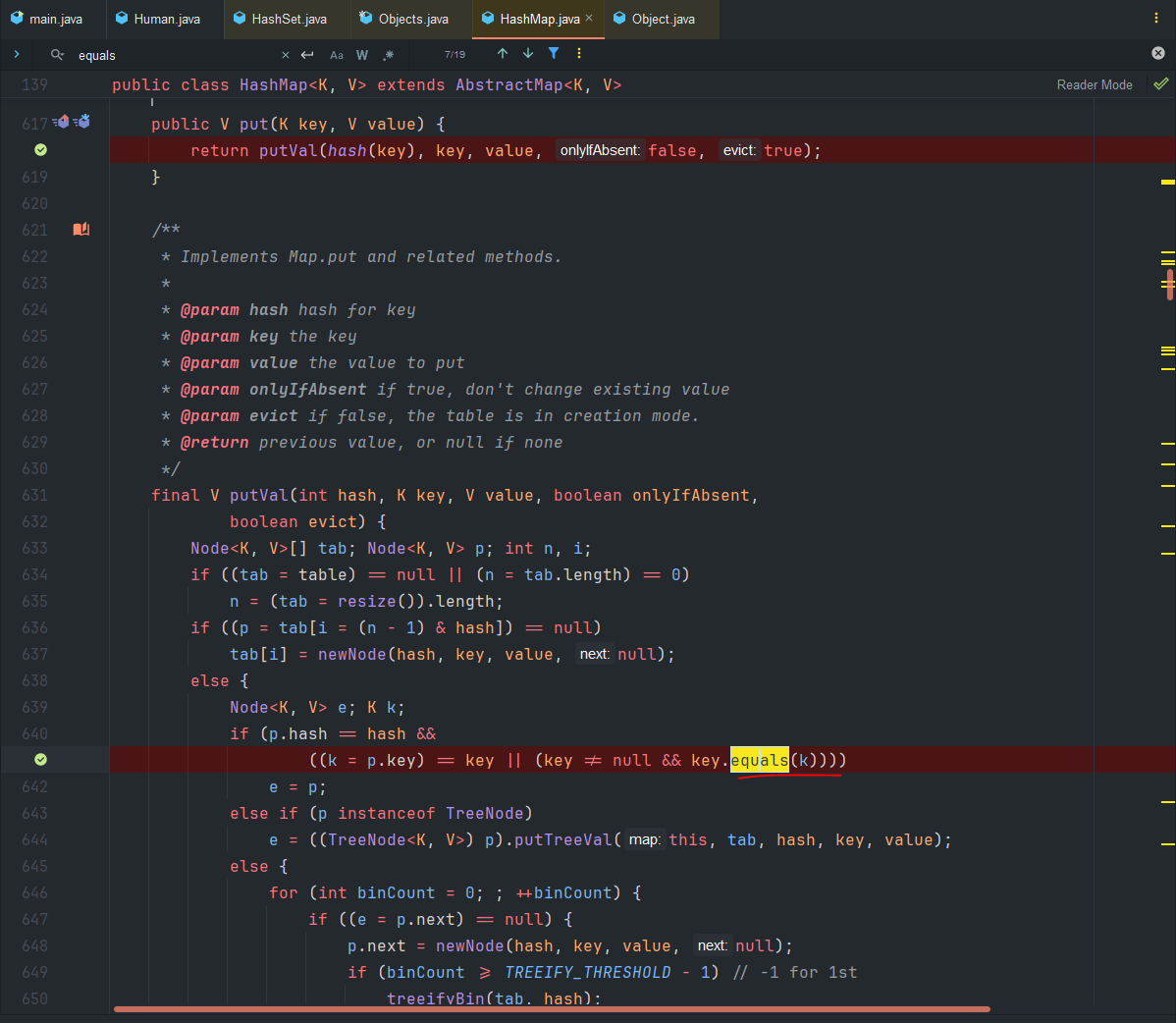
equals메서드를 통해서 동등성 검사를 진행하고 있는데, 이 또한,Override진행하지 않았으므로,Object의equals()메서드로 진행 한다.- 이는, Hash 값으로 동등성 비교가 아닌, 동일성(Identity, ==) 비교를 한다는 뜻이다.
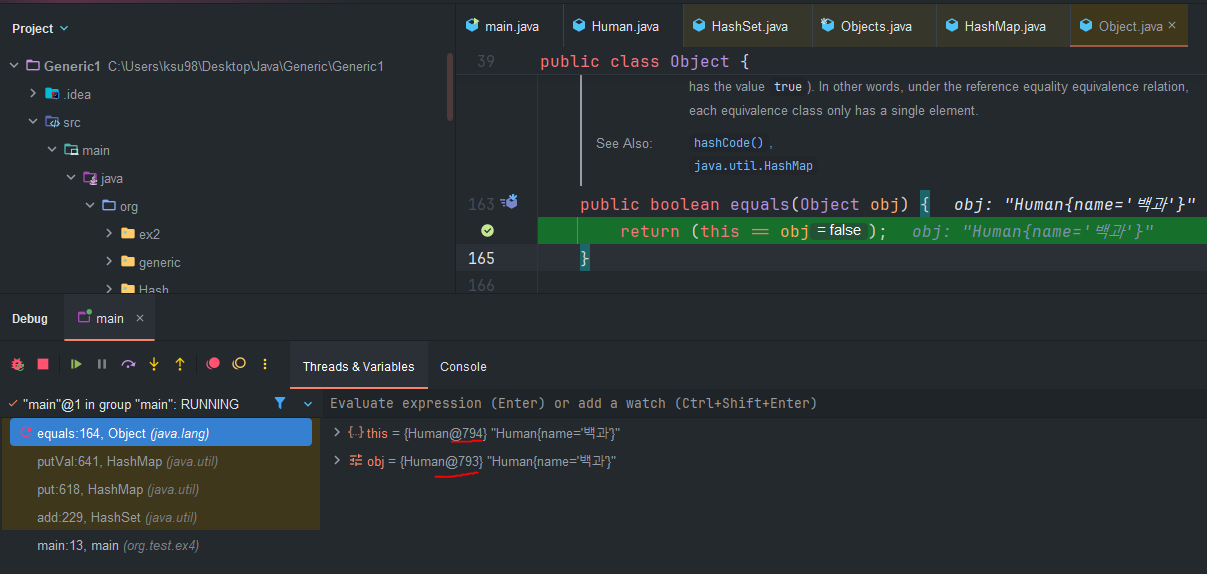
- 결국, 다른 참조 영역을 비교하므로
중복되지 않았다라고 판단하고,백과라는 중복된 데이터를add한 것이다. - 즉,
equals또한 오버로딩해서 hash값을 비교하게 만들어 동등성 비교를 진행하게 만들어준다. - 이제 정상적으로 중복된 데이터가 삭제 처리되어
add되는 것을 확인 할 수 있다.
public class Human {
public String name;
public Human(String name) {
this.name = name;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "Human{" +
"name='" + name + '\'' +
'}';
}
@Override
public int hashCode() {
return Objects.hashCode(getName());
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Human human = (Human) o;
return Objects.equals(getName(), human.getName());
}
}
==Main 코드 실행==
==Logs==
humans = [Human{name='백과'}]따라서
간단한 정리는
Hash 알고리즘을 사용하는 HashMap, HashSet, LinkedHashSet 등을 사용할 때에는, 무조건 equals 와 hashCode를 재정의 해서 사용하자.
복잡하게는, 객체의 식별 코드로 사용되는 Hash값을 참조 주소로 식별하는 것이 아니라, 객체 내부의 값 으로 재정의 해서 사용해야 논리적으로 동등한지 (동등성) 확인이 가능하다.

현재 블로그 이전 중입니다. https://blog.baekgwa.site/