Domain Name
-
사람들이 인터넷을 통해 특정 정보를 받으려고 할 때 사용된다.
-
예를들어 네이버 메인 화면을 찾고 싶으면 www.naver.com을 사용할 수 있는데 이거 자체가 domain name이다.
-
URL(Uniform Resource Locator)과의 차이점은
- (http나 https를 앞에 붙여서) 어떤 protocol을 사용해서 정보를 요청할건지 명시를 하고
- 특정 server에서 제공하는 website의 어떤 page를 원하는지를 구체적으로 명시하거나
&등을 이용해서 parameter을 전달
등 여러개의 정보들이 추가로 덕지덕지 붙어있다는 것이다. 즉 domain name은 URL의 일부로서 존재한다고 생각하면 된다.
https://cloudflare.com/learning/ 의 경우 cloudflare.com까지만 domain name이다. -
domain name은
.으로 구역이 나눠지고, 우측에서 좌측으로 TLD, 2LD, 3LD라고 흔히 불린다. 각각 top-level domain, second-level domain, third-level domain에 해당. 예를들어 google.co.uk의 경우 uk가 TLD, co가 2LD, google이 3LD다. google.com의 경우 com이 TLD, google이 2LD다.
domain name registrar / registry
-
domain name과 연동될 ip 주소를 뭐로 설정할지 담당하는 사업체를 domain name registrar이라고 한다.
-
registrar에서 만들어낸 domain name과 연동된 ip주소 쌍이 뭔지를 파악하고 이를 TLD server들 등에 반영하는 곳을 domain name registry라고 한다. 단어가 약간 다르다는 것에 유의. 이건 전부 ICANN에서 관리한다.
-
registrar은 domain name에 ip주소를 묶으려고 하는 사람에게 돈을 받으며, 또 registry에게 어떤 domain name이 어떤 ip주소에 묶이게 되었다고 알리면서 수수료도 지불을 한다. 즉 registrar은 브로커의 일종이라고 생각하면 된다.
-
실질적으로 각 ip주소에 무슨 domain name이랑 연결될지를 담당하는 곳은 registry라고 생각하면 된다. 이곳이랑 소통을 해서 어떤 domain이 어떤 ip주소에 연결될 수 있도록 돕는게 registrar이고.
-
비용을 지불해 이렇게 쌍이 형성되어도 영구적으로 유지되는 것은 아니다. 특정 기한동안만 인정이 되며 (최대 10년), 그 유효기간이 지나면 갱신을 하지 않으면 파기 된다. 다만 갱신은 무한하게 할 수 있다. 돈만 있으면(...)
-
registrar이랑 소비자 사이에 또 domain name과 연동될 ip주소 쌍을 만들어주는 브로커가 존재하는데 이들을 reseller이라고 한다. 이것도 합법이긴하나, 아무래도 중간 사업자 사이에 또 낀 중간 사업자이다보니 더 많은 돈을 요구할 수 있다. registrar이랑 직접 소통을 하고 싶으면 ICANN에서 제공하는 유효한 registrar 목록을 확인하면 된다.
-
그렇다고 registrar도 꼭 착하다는 것은 아니다. 이들이 domain name과 ip주소 연결 쌍이 얼마나 유효한지를 소비자들에게 알려줄 책임이 있는데, 일부러 기한이 만료될 때까지 안 알려주다가 만료되는 순간에 본인들이 registry를 통해 해당 domain name을 사버린 다음에 원래 주인이었던 사람에게 더 비싼 가격으로 되팔이 할 수 있기 때문이다.(...)
-
그러면 단점만 있고 registry에 직접 등록하는게 가장 좋냐고요? 꼭 그런건 아니다. 원래 TLD에다가 저 쌍을 등록할 때 WHOIS information, 그러니까 등록한 자가 누군지에 대한 정보를 입력해야 하는데 여기에 등록하려는 사람의 개인정보를 입력해야 한다. 이게 찝찝할 수 있는데, registrar을 통해 등록시 registrar 측에서 본인들에 대한 정보를 거기에 대신 기입해준다. 단 이게 registrar이 등록을 한 소비자를 위한 proxy 역할을 하는 것이라 등록을 한 소비자의 개인 정보를 registrar에게 제공해야 하는 것은 여전하다. 그게 registry에게 제공이 안 될 뿐.
-
이 때문에 registrar 측에서는 보안을 엄청 많이 신경 써야 한다.
Domain Name System (DNS)
-
문제는 실제로 인터넷 정보를 주고 받을 때 어디에서 정보를 받고 그걸 어디에 전달할지 구별하는데 사용되는 것이 ip 주소라는 것이다.
-
즉 원래는 네이버 홈페이지에 들어가려면 네이버 홈페이지 정보를 가진 서버의 ip주소를 입력해서 정보를 요청해야 한다는 것이다. 다만 사람 입장에서 그걸 외우기가 힘들어서 위와 같은 Domain Name이 등장한 것이다.
-
그래도 어쨌든 실제 통신에서는 ip 주소를 사용하기에 domain name을 ip 주소로 변환해야 하는데 이를 해주는 시스템이 Domain Name System, DNS다.
Process
DNS를 통해 어떻게 DN이 ip주소로 변환되는지에 대해 알아보겠다.
1. request
-
브라우저에 유저가 domain name을 입력해서 관련 정보를 브라우저에게 요청한다.
-
브라우저는 먼저 본인 cache (browser's DNS cache)에서 해당 domain name에 대한 ip 주소가 있는지를 확인한다. 만약 있을 경우 그 주소를 활용해 바로 통신을 하고 관련 정보를 사용자에게 전달한다.
-
위에 해당되지 않을 경우, OS에 해당 domain name에 대한 ip 주소가 있는지를 확인한다. OS의 stub resolver, 혹은 DNS client라고 불리는 녀석이 이를 담당하는데 브라우저랑 browser의 DNS cache랑 별도인 고유의 DNS cache를 활용해서 이를 확인한다. 만약 있을 경우 그 주소를 브라우저에게 전달하고 브라우저가 이를 기반으로 통신을 하고 관련 정보를 사용자에게 전달한다.
2. Request to recursive DNS resolver (DNS recursor)
- 1번에서 해결이 안되었을 경우 OS에서 DNS recursor에게 해당 domain name에 대한 ip주소가 있는지를 물어본다. 이곳에는 DNS와 관련된 온갖 정보(record)들이 저장되어 있으나, 일단 이 글에서 집중적으로 살펴볼 record 종류는 domain name이랑 연관된 ip주소를 알려주는 record인 A(IPv4 용)/AAAA(IPv6용) record다.
다른 record들에 대해 궁금하다면 이 글을 참고. 이 글에서는 좌측 링크의 record들 중 일부 record들만 다룰 예정이다.
- DNS recursor은 요청이 오면 일단 본인이 해당 domain name과 관련된 A/AAAA record를 caching하고 있는지를 확인한다. 만약 있을 경우 그 IP 주소를 그대로 전달한다.
3. Request to DNS Root Server
-
2번에서 해결이 안되면 이 때부터 DNS recursor이 본격적으로 변환을 위해 일을 한다. OS는 그 답을 기다릴 뿐임.
-
먼저 이후의 과정은 DNS recursor에 아무것도 cache가 되지 않았다는 가정하에 이루어진다는 점을 참고 바란다. 당장 이게 무슨 소리인지 모를 수도 있는데, 무슨 뜻인지 및 이 가정을 왜 하는지는 후술.
-
DNS recursor은 DNS root server에 먼저 해당 domain name과 관련된 ip 주소를 찾으러 간다. 안타깝게도 root server에 해당 domain name과 관련된 ip 주소를 가질 일은 절대로 없다.(?) 그 대신 해당 DN과 관련된 DNS TLD server의 ip주소를 알려준다.
-
어떤 DNS TLD server이 관련되어 있는지는 요청 DN의 확장자에 의해 결정된다. .com, .net, .org, .gov, .kr, .jp, .us, .edu등 엄청 많고 예시를 보면 알겠지만
.다음에 있는 끝부분?이 여기에 보통 해당된다. -
root server은 전세계에 13'종류'가 있다. 13'개'가 있는건 아니고 각 종류가 전지역에 여러개씩 존재를 하고 있으며 개수는 다 합하면 600개 정도 있다. 모두 비영리조직인 ICANN에서 관리를 하며 Anycast routing을 통해 여러 DNS recursor에서 오는 요청에 대해 빠른 답변을 제공해준다.
-
참고로 root server에게 요청을 하려면 당연히 root server과 관련된 ip주소를 알고 있어야 하는데, 모든 DNS recursor이 13 종류의 root server과 관련된 ip주소들을 전부 보유하고 있다. 이 정보는 절대로 삭제되지 않고, 삭제되어서도 안된다.
-
또 DNS recursor은 root server에게 TLD server domain name과 이와 관련된 ip주소에 대한 답변을 받으면 다음에 현재 찾고 있는 DN과 관련된 확장자와 관련된 요청이 또 올 때 바로 해당 TLD로 요청을 할 수 있도록 이를 caching한다. 이 경우 추후 요청이 온 특정 domain name이 이 cache된 DNS TLD server과 관련되어 있으면 거기의 ip주소를 기반으로 바로 4번 단계로 바로 진행한다. 즉 이 단계(3번)를 진행할 필요가 없음.
4. Request to DNS TLD server
-
TLD는 Top-Level Domain의 약자다.
-
특정 domain extension을 가지고 있는 domain name들에 관한 정보를 모두 가지고 있다. 예를 .com TLD server의 경우 www.naver.com과 같은 모든 '.com'으로 끝나는 domain name들에 관한 정보를 가지고 있다.
-
다만 직접적으로 www.naver.com에 대한 ip주소를 가지는 것은 아니고 이랑 관련된 authoritative nameserver에 대한 정보를 가지고 있다.
-
관리는 ICANN의 하위 기관 중 하나인 Internet Assigned Numbers Authority (IANA)에서 한다.
-
국가(.kr, .us, .ru, .jp)와 관련된 TLD server인 country code top-level domain server, 그 외(.com, .org, .net, .edu, .gov)와 관련된 generic top-level domain server와 같이 2가지로 크게 나눌 수 있다.
-
...는 사실 하나가 더 있는데 infrastructure domain이라고 '.arpa'가 예시다. ip주소를 기반으로 DN을 찾는 reverse DNS lookup (역방향 DNS 조회)에 사용된다. reverse DNS lookup은 누가 웹페이지에 방문하는지를 역추적하는데 매우 유용하기 때문에 중요하며, 이를 가능하게 해주는 특수 domain name이 저 '.arpa'확장자를 가진다. 자세한건 이 링크 참고.
-
여기서 얻은 정보도 나중에 관련된 요청이 올 때 바로 사용할 수 있도록 caching을 할 수 있다.
5. Request to DNS authoritative nameserver
-
정상적인 경우 resolver의 일반적인 최종 목적지가 되는 곳이 DNS authoritative namserver이다.
-
특정 domain name에 대한 정보 자체를 보관하고 있기에 당연히 특정 domain name에 대한 ip 주소 정보도 가지고 있다.
-
resolver이 query하던 domain name과 관련된 DNS A/AAAA record가 있으면 이걸 그대로 돌려준다.
-
그러나 관련된 record가 A/AAAA record가 아닌 CNAME record인 경우가 있다. 이 경우 해당 domain name에 대해서 resolver이 '다시' DNS query를 해야 한다. 물론 cache된 정보들이 좀 모여있으면 금방 찾을 수 있겠지만 여튼...
-
굳이 CNAME record를 사용하는 이유는
- 여러 domain name이 하나의 ip 주소를 가리킬 수 있도록 하기 위해. 특히 여러 종류의 service (mail, blog, etc.)들을 다 하나의 server에서 처리할 수 있도록 하게 해준다.
- 어떤 domain name에 대해 '실제로' service를 제공하는 server의 domain name을 파악할 수 있도록 하기 위해. 즉 사실 service를 제공하는 server의 domain name은 사람들이 흔히 접속할 때 사용하는 domain name과 다를 수 있다.
-
CNAME record가 CNAME record를 가리키는 경우도 있다. 다만 그만큼 DNS query 횟수가 늘어나는 것이라 선호되진 않는다.
Why hierarchical structure?
-
다 보고 나면 들 수 있는 의문이, 왜 이렇게 복잡한 과정을 거치냐는 것이다. 예를들어 Root server, TLD server, name server과 같은 계층 구조를 가져서 복잡하게 여러번 이동하지 말고 그냥 모든 정보를 저장한 server을 여러개 만들어서 거기서 바로 찾으라고 하면 안되냐고 할 수 있다.
-
다만 관련 정보를 전부 저장하는 server을 만드는게 힘들고, 설령 만들었더라도 온곳에서 오는 요청들을 전부 감당하기에 충분한 server들을 만들기 힘들다는 문제점이 있다. 즉 workload를 최대한 분산시키려고 하다보니 이러한 구조를 가지게 되었다.
-
또 다른 큰 문제는 그 하나의 DNS server이 오작동하면 전세계의 인터넷이 마비된다는 문제점 때문이다.
Hard to manage
-
앞의 record 종류들이 곧 DNS에서 제공하는 기능이기 때문에 DNS는 그만큼 복잡하다고 볼 수도 있다. 확장성이 많이 좋아서 기능이 이래저래 추가되다보니 이런 현상이 발생했다.
-
좀 많이 이론적으로 접근할 경우, DNS는 DNAME record를 활용해 DFA(Deterministic finite automation) 및 PDS(Push-down system)을 simulate하는 것이 가능하다. 그만큼 복잡한 system을 이론적으로도 운용하는 것이라고 볼 수 있다는 뜻이다. 이에 대해 더 알고 싶으면 이 링크 참고
-
이 복잡성은 DNS 관리 자체를 난해하게 만들기도 한다. 정확히는 DNS system을 보안에 취약하게 만들 수가 있다. 이 링크에 따르면 이를 방지하고 싶으면
- DNS service는 가급적 하나의 vendor에서 제공하는 것을 활용해야 한다고 한다. 그래야 하나의 vendor의 DNS service만을 활용해가지고 trust 기반이 단 하나의 source로부터만 형성 될 수 있게 하고, domain 변화에 대해 여러 source에서 각기 다른 행동을 보여가지고 혼란을 일으키는 상태를 방지할 수 있기 때문이라고 한다.
Types of DNS query
- DNS query에는 3가지가 존재한다. recursive query, iterative query, non-recursive query
recursive query
-
이 query를 DNS client가 DNS server에게 요청을 하면 server은 무조건 그 domain name과 직접적으로 연관된 ip address를 줘야한다. 실패시 실패했다고 전달한다.
-
recursive DNS resolver이랑 recursive DNS query의 차이를 확실히 알도록 하자. 전자는 recursive query를 받고 처리하는 computer 자체를 말하고, 후자는 방금 소개한 query 방식 자체를 말한다. 방금 소개한 query 방식의 DNS server이 recursive DNS resolver이라고 생각하면 된다.
iterative query
-
이 query를 DNS client가 DNS server에게 요청을 하면 server은 '최선을 다해서' client에게 해당 domain name과 관련된 정보를 준다.
-
여기서 최선을 다한다는 것은 요청시 사용한 domain name과 직접 연관된 ip주소 정보가 없을 경우 그것과 관련 있고, 본인보다 level이 낮은 다른 DNS server에 대한 ip 주소를 제공해주는 것을 의미한다.
non-recursive query
-
구글서 검색시 흔히 iterative query의 다른 이름으로 사용되고 있으나, 별도의 정의가 따로 있다.
-
요청하는 쪽은 '이미' domain name과 관련된 ip주소를 알고 있는데 (본인이 caching을 해놓았거나, 본인이 해당 domain name에 대한 authoritative server이라서) 이를 server에게 알리기 위한 query다. server은 해당 정보를 caching 혹은 있던 정보를 갱신한다.
앞의 DNS process에서의 예시
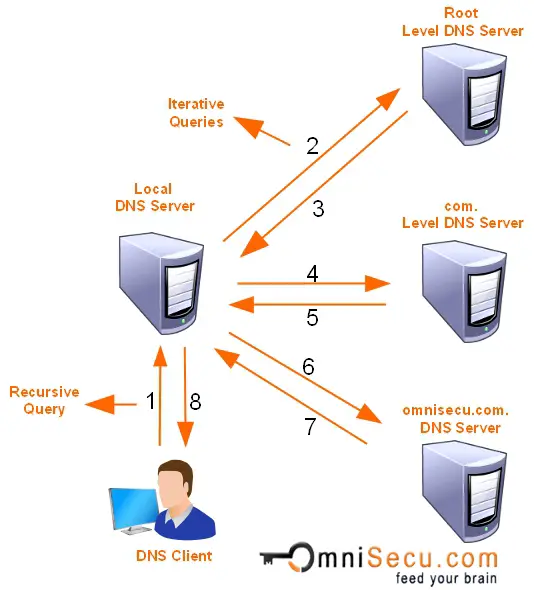
위에 나와 있듯 recursive resolver에게 user computer의 OS가 요청하고 응답하는 과정이 recursive query이고, recursive resolver이 타 DNS server들에게 요청하는 것이 iterative query다.
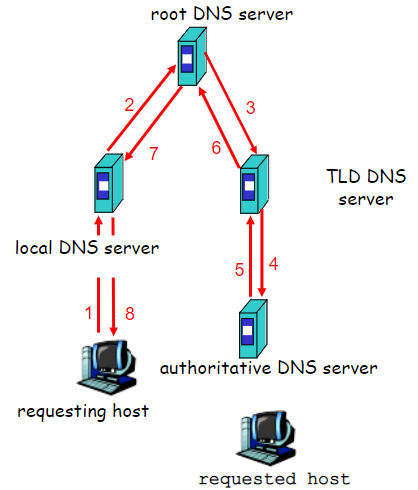
그냥 다 iterative query 형태로 요청을 하면 안되냐고 할 수 있다. 그럴 경우 밑과 같은 형태가 되는데, 이 경우 root server에게 traffic이 몰린다 + 중간에 거치는 결과물들에 대한 정보를 recursive resolver이 받을 수 없어 caching도 안되가지고 매 query마다 여러번의 iteration을 거쳐야 해서 성능상 문제가 있다는 단점이 있다.
DNS caching
-
single point failure을 방지하기 위해 계층 구조를 가졌지만 그렇다고 여러번 왔다갔다 하는 것이 손해가 아니라는 것은 아니다. 그래서 DNS caching이 존재하는 것이다. recursive resolver의 경우 recursive query들을 통해 얻은 각 server의 정보를 caching하며, browser이랑 OS는 recursive resolver로부터 요청했을 때 얻은 답들을 caching한다.
-
저장된 정보들과 같이 붙어있는 attribute로 TTL (time to live)가 있다. 해당 정보가 유효한 기간을 정해놓은 것으로, 저 시간이 지나면 자동 파기가 되고 이 경우 caching을 해놓은 쪽에서 다시 관련 정보를 요청해야 한다.
Load-balanching using DNS
-
앞의 caching에서 TTL이 있는 이유를 단순하게 생각해보면, ip주소 정보가 언제나 유효한 것은 아니기 때문에 특정 기간이 지나면 새로 정보를 받을 수 있도록 하기 위해서라고 볼 수 있다.
-
문제는 그렇게 자주 ip주소 정보가 달라질 일이 있냐라는 것이다. 여기서 등장하는게 DNS를 활용한 load-balancing이다.
-
가장 흔한 방식은 round-robin DNS다. 특정 domain name에 대해 여러개의 ip주소를 (여러개의 A/AAAA record를) server에 보관한 다음, 해당 server에 그 domain name에 대한 ip 주소 요청이 오면 매 요청마다 돌아가면서 ip주소를 제공하는 것이다.
-
매우 간단하게 구현이 가능하다는 장점이 있으나, 문제는 caching에 의해 제대로 동작하지 못할 확률이 높다. 예를들어 특정 ISP에서 제공하는 recursive resolver이 어떤 domain name에 대한 여러 ip주소 중 하나를 DNS server에게 받았다고 하자. 그러면 이를 caching할 것이다. 그러면 해당 recursive resolver을 사용하는 모든 user들은 관련 domain name에 대한 ip주소를 요청할때마다 그 ip주소를 할당받게 될 것이다. 이상적으로는 각 user이 각기 다른 ip주소를 (돌아가는 형태로) 사용하는 것이지만 그게 caching으로 인해 불가능해진 것이다. 게다가 이 ip주소를 받은 user은 추후 ISP의 recursive resolver이 해당 cache data를 파기해도 계속 그 ip주소를 가지고 요청해서 관련 server이 부담을 받는 상황이 생길 수 있다.
-
그러나 TTL을 적절히 설정할 경우 이를 어느정도 완화할 수 있다. user/recursive resolver에서 cache된 data의 순환이 빠르게 이루어지도록 해서 다양한 ip주소에 대해 요청을 할 수 있도록 유도할 수 있기 때문.
-
다만 너무 짧게 하면 query 자체가 여러번 이루어져서 DNS에 부담이 갈 수 있기 때문에 적당한 값으로 설정을 해야 한다.
참고 링크
Cloudflare - What is a domain name?
Cloudflare - What is a domain name registrar?
How DNS works (comic)
CloudFlare - What is DNS? | How DNS works
CloudFlare - What is round-robin DNS
