-
본 글은 아래 글을 번역했고 거기에 몇가지 첨언을 더했습니다.
HTTP/3 performance improvements (part 2) -
2021년 글이라서 최근에 나온 내용과 불일치한 부분이 있습니다.
이번에는 HTTP/3랑 QUIC이 성능 증진을 얼마나 이루는지에 대해 알아볼 것이다.
다만 논의하다 보면 알게 될 것이, 잠재적으로는 큰 성능 증진을 이룰 수 있지만 이것들이 대부분 느린 네트워크를 사용하는 사람들에게만 해당된다는 것도 볼 것이다. 즉 셀룰러나 빠른 케이블을 사용하는 사람들이 우리들의 웹사이트에 접속한다면 그닥 도움이 안되는 프로토콜...
하지만 뒤에 또 볼 것이, 평균적으로 빠른 uplink 속도를 가지는 곳에서도 하위 1~10%에 해당하는 사람들은 잠재적으로 많은 속도 증진을 누릴 수 있다. 이유는 이 프로토콜이 오늘날 인터넷에서 흔하진 않지만 심각한 영향을 주는 문제들을 주로 해결하는데 초점이 맞춰져서 그렇다.
A primer on speed, 속도랑 관련된 2가지 요소들
성능과 속도는 막 얘기를 시작하려고만 해도 복잡해지는데, 이들에 영향을 주는 요소들이 너무 많기 때문이다. 여기서는 네트워크 측면에서의 요소만 따져보도록 하겠다. 그러면 2개가 속도에 제일 영향을 많이 주는데, latency(지연율)과 bandwidth(대역폭)이다.
latency는 A지점서 B지점까지 packet이 도달하는데 걸리는 시간이다. 이 시간은 빛이 해당 거리를 이동하는 시간보다 빠를 수 없고, 또 신호가 선이나 공기 중에서 최대 속도로 이동하는 시간보다도 빠를 수 없다. 일반적으로 A랑 B사이의 거리에 영향을 받는다. 보통 10~200ms가 걸리는데, B에서 다시 A로 packet을 보내야 진정한 통신이 이루어진다는 점 유의. 저 값의 2배를 한 것, 즉 two-way latency를 round-trip time(RTT, 왕복시간)이라고 한다.
후에 설명할 congestion control(혼잡 제어) 등의 이유로 하나의 파일을 보내는데 여러번 왕복을 해야 하는 상황이 발생한다. 즉 latency가 50ms 이하로 꽤 빨라도 체감하는 지연이 꽤 크다. 이 때문에 등장하는게 Content Delivery Network(CDN, 콘텐츠 전송 네트워크)다. 물리적으로 인접한 위치 서버를 만들어서 콘텐츠를 전송하면 latency가 훨씬 작아지면서 체감 지연도 줄어들테니까.
bandwidth는 한번에 보낼 수 있는 packet 수라고 생각하면 된다. 좀 정확한 개념을 알고 싶으면 물리 공부를 하면 되는데 다음 링크 참고. 데이터가 전송되는 매질이 뭔지, 네트워크에 있는 사용자가 몇명인지, 장치마다 동시에 처리가능한 packet 수가 다르기에 여러 subnetwork들을 서로 연결하는 장치가 뭔지 등등 이 녀석에 영향을 주는 요소가 매우 많다.
보통 packet이 파이프를 통해 전송이 되고 latency는 파이프의 길이, bandwidth는 파이프의 폭에 대응된다고 비유를 하며 적절한 비유이기도 하다. 이 경우 인터넷은 서로 여기저기 많이 연결된 파이프들의 모임이며, 어떤 파이프는 폭이 크고 어떤 파이프는 폭이 좁다. 보통 이 좁은 파이프에 해당하는 녀석들이 bottleneck(병목)의 원인이 되며, 실제 속도가 느린 이유에 가장 많이 기여하기도 한다.
이 2가지 요소가 앞으로의 논의에서 자주 나오기 때문에 기억해두면 좋음.
Congestion Control, 혼잡 제어와 성능 증진
성능 증진을 위해 신경써야 하는 것 중 하나는, transport protocol이 network의 최대 bandwidth를 얼마나 '효율적으로' 활용하냐는 것이다. 최대 bandwidth가 곧 최대 전달 가능한 packet 수를 의미하니 성능에 치명적인건 알겠고, 몇몇이 QUIC이 TCP보다 이를 잘한다고 하는데 아니다. 이참에 TCP가 어떻게 bandwidth를 효율적으로 활용하려는지 알아보자.
일단 이를 수행하려고 할 때 한가지 문제가, 애초에 최대 bandwidth가 얼마인지 모른다는 것이다. 사실 끝지점 한쪽에서 다른 끝 지점 한쪽이랑 연결을 했을 때 그 사이의 bottleneck 유발 요소가 최대 bandwidth를 결정하는데 transport protocol이 어떻게 이를 알겠는가? 각 요소들이 통신으로 알려주면 되지 않냐고요? (아직은) link capacity를 endpoint들에게 알려주는 방식이 없다.
아니 사실 알고 있다고 해도, 다른 연결에서도 이를 활용할 것이다. 사용하는 사람들은 실시간으로 달라질 것이고 모두가 공평한 bandwidth를 가지는게 중요하니 최대 bandiwdth는 항상 유동적이게 될 것이다.
즉 연결 운용하는 transport protocol 측에서 최대 bandwidth가 얼마일지 판단하는게 불가능하다. 이쯤되면 짜증나니까 bandwidth 효율적으로 사용하는 것을 무시하고 무식하게 packet을 계속 보내면 안되냐고 생각할 수 있다. 하지만 저게 중요한것이, bandwidth를 무시하고 보내면 그만큼 packet loss가 발생하게 되어서 다시 전송을 해야 하며, 이를 모두가 그러고 있을시 모두가 하나의 파일 받는데도 오랜 시간을 기다려야 하는 불상사가 발생할 수 있다. 남만 악영향을 끼치는게 아니라 모두가 악영향을 받는다. Lose-Lose. 즉 효율적으로 bandwidth를 사용하는 근본적인 이유가 packet loss가 발생하지 않는 선에서 최대한 많은 packet을 전달하려고 애쓰는 것이라 생각하면 된다. 뭐 보다시피 완벽하게 조절하는건 불가능하기에 애쓴다고 표현.
그러면 TCP는 결국 어떻게 이를 이루는가... 여기서 congestion control이 등장한다. 유동적으로 변하는 bandwidth를 실시간으로 파악하는 본인 나름의 방법이라고 생각하면 된다.
먼저 연결 시작시 적은 수의 packet만 보내는걸 시도한다. 보통 10~100개 (14~140KB). 그리고 RTT시간 만큼 기다려서 ACK가 되는지를 기다린다. 만약 되면 그정도의 packet rate는 현 연결이 감당이 가능하다는 것으로, 개수를 더 늘려본다. 보통 2배로 늘린다. (exponential growth 정확히는 ACK를 받을때마다 다음 전송때 limit를 1개 늘린다.) 이 상태를 slow start라고 한다.
이를 반복하는데, 그러면 어느 순간 ACK가 되지 않는 packet loss가 발생한다. 그러면 연결이 현 packet rate를 감당하는게 안된다는 것이다. (네트워크 혼잡) 그러면 본인이 현 연결서 최대로 보내는 packet의 개수를 반토막을 낸다. (Multiplicative decrease) 그러면 한동안 추가적인 packet 전송이 이루어지지 않을 것이다. 반토막을 낸 순간 이미 보내는 중인 packet이 그 한계를 넘어서니까.
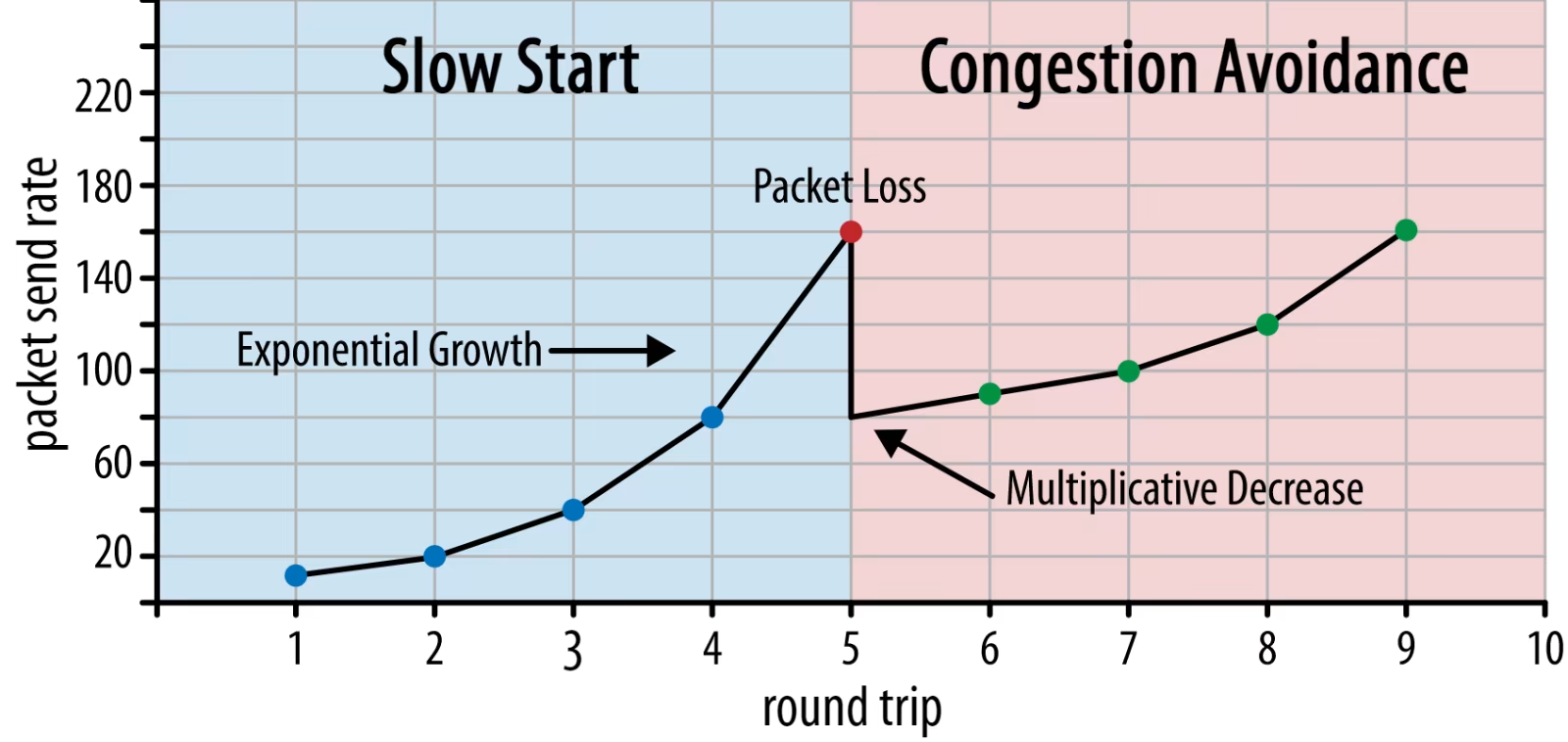
대충 이런 느낌이라고 생각하면 된다만... 이는 매우 열화된 설명이다. 실제로는 훨씬 복잡하며, 원본 링크에 있는 위 그림도 사실 정확하게 설명하는 그림이 아니다. 여러 state를 가지는 FSM 형식으로 운용이 되는데 이에 관해서는 나중에 시간이 나면 글을 올릴 생각이며 일단은 다음 링크 참고
또 위에서 설명한거 말고 다른 방식으로 congestion control이 운용되는 TCP가 많다. 각기 이런저런 요소들을 고려하면서 (bufferbloat, congestion으로 인한 RTT 변화, 서로 다른 사용자들이 공평하게 bandwidth 나눌 수 있게 하기) 만들어졌고, 지금도 만들어지는 중(...) 일단 이정도만 알아도 다음에 할 얘기는 충분히 이해할 수 있으니 넘어가도록 하자.
일단 위의 방식을 보면 알 수 있는것이, 최대 효율의 send rate를 가지는 상태에 도달하는데 시간이 좀 걸린다. RTT가 길수록, 그리고 실제로 활용 가능한 bandwidth가 많을 수록 이 시간이 더 오래 걸린다. 특히 웹페이지의 경우 첫 object가 load되는 시간을 이 녀석이 결정할 수 있다. (애초에 이 점을 고려해서 엄청 중요한 data는 14KB 미만으로 짜라는 얘기까지 있을 정도니)
그래서 packet loss가 좀 발생하는건 크게 신경 안쓰고, 네트워크가 high bandwidth/high-latency인 경우에는 위보다 좀 더 극단적인 방식을 택하는게 유리하다.
여기서부터 QUIC 얘기를 좀 하겠다. 이전에 QUIC이 이론적으론 packet loss로 인한 페널티에 영향을 적게 받는 (그리고 이것의 원인이라 볼 수 있는 HOL blocking이 잘 안 발생하는) 이유가 각 자원의 byte stream에서 발생하는 packet loss를 독립적으로 처리하기 때문이라고 했다. 그리고 QUIC은 congestion control 개념이 없고 loss가 발생한 data의 재전송이 안이루어지고 처음에 원하는만큼 packet을 보낼 수 있는 UDP에서 작동한다.
이 때문에 QUIC이 congestion control이 없고, UDP를 활용해 처음에 data를 한번에 많이 보내는것이 가능하고, 이 때 발생하는 packet loss로 인한 지연은 HOL blocking의 해결을 통해 무마해서 TCP보다 빠르다고 하는 사람이 많은데...
일단, QUIC도 TCP랑 매우 유사한 bandwidth 관리 방식을 사용한다. 얘도 처음에는 낮은 rate로 packet을 보내고 점차 늘려가며, ACK를 활용해서 네트워크의 현 packet 수용량을 측정한다. 이유는
- QUIC이 reliable해야 하기 때문이다. 본인이 그렇다고 하기 때문.
- 다른 QUIC/TCP 사용자들과 공평하게 bandwidth 사용을 해야 하기 때문.
- HOL-blocking이 packet loss로 인해 발생하는 지연을 무마시키는데 그닥 도움이 되지 않기 때문. (후술)
그러면 TCP랑 QUIC이랑 거기서 거기 아니냐고요? 이전에 말했었는데 QUIC의 TCP 대비 장점은 금방 새로운 policy를 집어넣는게 가능하다. 즉 새로운 congestion control algorithm을 TCP보다 더 빠르게 수용할 수 있다. 이게 TCP보다 나은 진정한 이유 중 하나다.
이는 TCP는 주로 OS kernel차원에서 구현되고 있는데 QUIC은 native app을 실행하는 user space에서 주로 구현이 되고 오픈 소스이기 때문인것도 있다. 그리고 congestion control algorithm이 앞에 봤다시피 계속해서 발전하고 있기 때문에 의미있는 장점이라고 볼 수 있다. (특히 5G 관련해서 바꿔야 할게 좀 있다.)
예시로 페이스북이 이미 오픈 소스인점을 활용해 이런저런 실험을 많이 하고 있다. 그리고 delayed acknowledgement frequency 제안이라는 것이 나왔는데 QUIC은 ACK를 2개의 packet을 받을때마다 하는데 그러지 말고 10개의 packet을 받을 때마다 해서 인공위성이나 bandwidth가 매우 높은 network에서 ACK를 자주 보내게 되는 overhead를 줄여, bandwidth 효율성도 높이고 결과적으로 속도도 증진시키자는 것이다. 이런걸 TCP는 바로 적용하긴 힘들겠지만 QUIC은 금방 적용할 수 있겠지요.
강조하는게, 이런 새로운 congestion algorithm들이 QUIC에게'만' 적용된다든가 TCP에게'만' 적용된다든가 그런 것이 아니다. 둘 다 적용 할 수 있는건데 전자가 좀 더 금방 보급이 가능하고 후자가 좀 더 보급이 힘들다는 것이다. 애초에 현재 QUIC의 기본 congestion control algorithm은 New-Reno로 TCP가 쓰였을 때 나온 알고리즘이다.
결론은, TCP보다 QUIC이 가지는 장점 중 하나는 바로 쉽게 새로운 congestion algorithm을 적용하는게 가능하다는 것이다.
0-RTT connection set-up과 성능 증진
성능 증진 관련 두번째 초점은 바로 유용한 HTTP data를 보내기 전에 해야 하는 왕복이 몇번이냐에 관해서다.
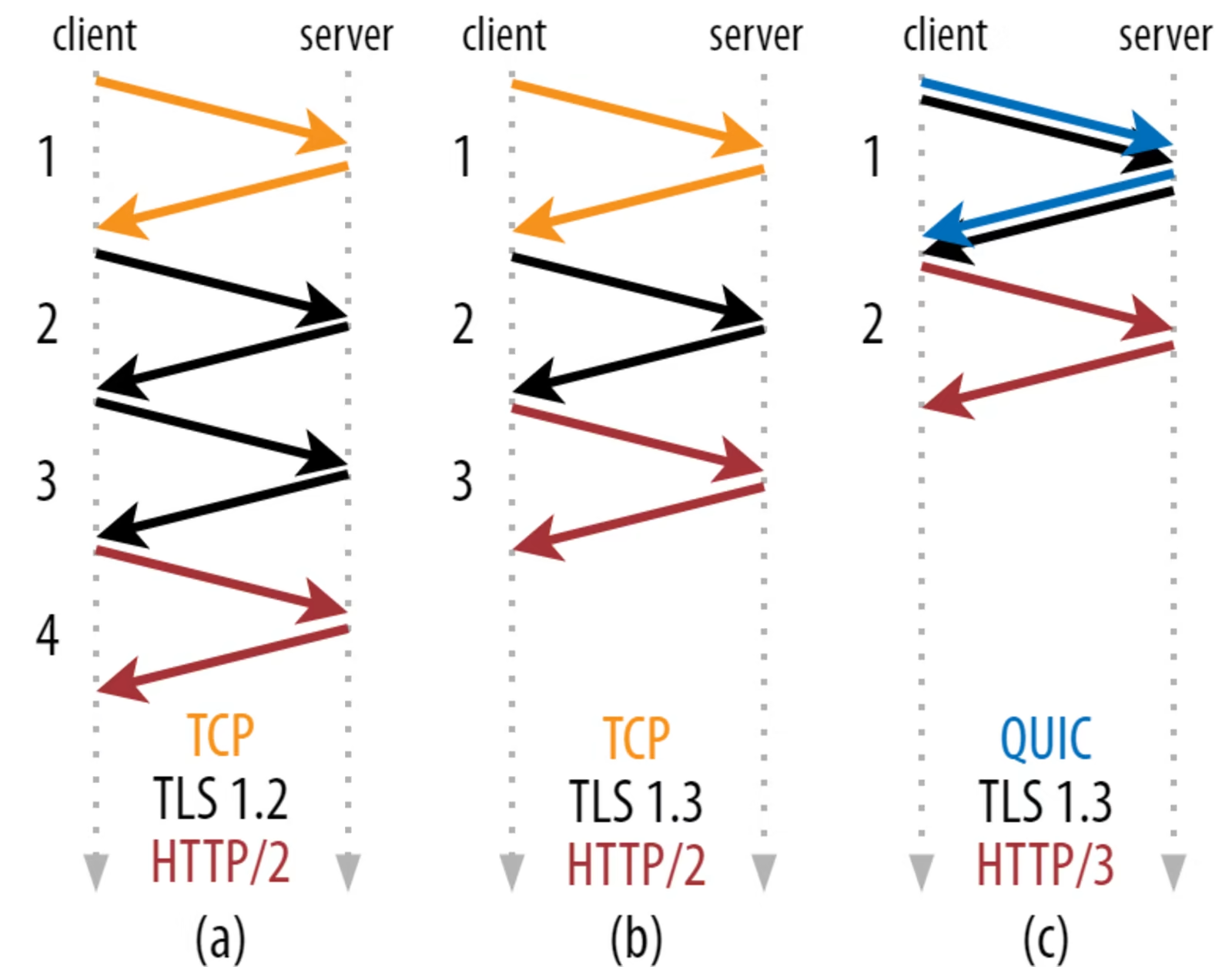
위 그림은 전 글에도 나왔던 글인데, 보시다시피 (a)의 경우 3번, (b)의 경우 2번의 round trip을 해야 하며 둘 다 2번의 handshake 과정을 거친다. 느린 네트워크에서는 이 적은 횟수의 round trip도 성능 면에서 괘 타격을 크게 줄 수 있다. 100~200ms동안이나 연결 구축에만 시간을 소모하기 때문. 그냥 TCP랑 TLS를 합치면 되는거 아니냐는 얘기가 있지만, TCP가 TCP랑 관련되지 않은 내용을 handshake 과정에서 전달하는 것을 지원하지 않기 때문에 불가능. 사실 지원할 수 있도록 노력한 적이 있으나 현실 배포가 힘들다는 결론이 나왔다.
QUIC은 (c)에서 보이듯이 TLS랑 함께 보낼 수 있도록 애초에 설계되어 있다. 그러면 round trip을 한번만 해도 되니 (a), (b)보다 낫다고 볼 수는 있는데... (b)랑 비교하면 round trip 1개 차이고 이는 생각보다 체감 차이가 크지 않다. 느린 네트워크에서는 좀 크겠지만. 몇몇은 QUIC이 TCP보다 2개 이상의 round trip을 줄인다는 얘기가 있으나 그건 (a)만 고려해서 그런 것이다.
handshake 과정이 끝나기 전까지 유용한 데이터를 보내지 않는 이유는 handshake 전에 보내는 data는 encrypt되지 않기 때문이다. encryption과 관련된 cryptographic handshake (TLS 관련)이 완료되어야 encrypt된 data를 보내는 것이 가능하다... 근데 진짜 그럴까(?)
encryption parameter이 유효한게 보장되는 시간 안에 같은 사용자가 연결을 다시 구축하면 '처음부터' encrypted connection을 구축하는 방식이 있다. 처음에 사용했던 encryption parameter을 유효기간동안 저장하다가 그 기간 안에 재접속을 하면 다시 사용하는 것이다. 이러면 TLS handshake를 기다릴 필요도 없으며, 이 테크닉을 session resumption이라고 한다. QUIC에서 이를 수행하면 handshake 과정에 동시에 HTTP data를 보내는 것이 가능하다. 그러면 data 전달 과정 전에 수행되는 RTT가 0이라고 볼 수 있어서 0-RTT라고 불린다. 물론 첫 data 받는데 걸리는 시간이 1-RTT이긴 하다만 여튼.
그러면 TCP는 이게 안되는가? 된다. 사실 저 기능은 TLS 차원에서 지원해주는 것이거든. 그래서 여전히 QUIC은 가장 최적화된 TCP보다 1 RTT만큼만 더 빠르다고 생각할 수 있다.
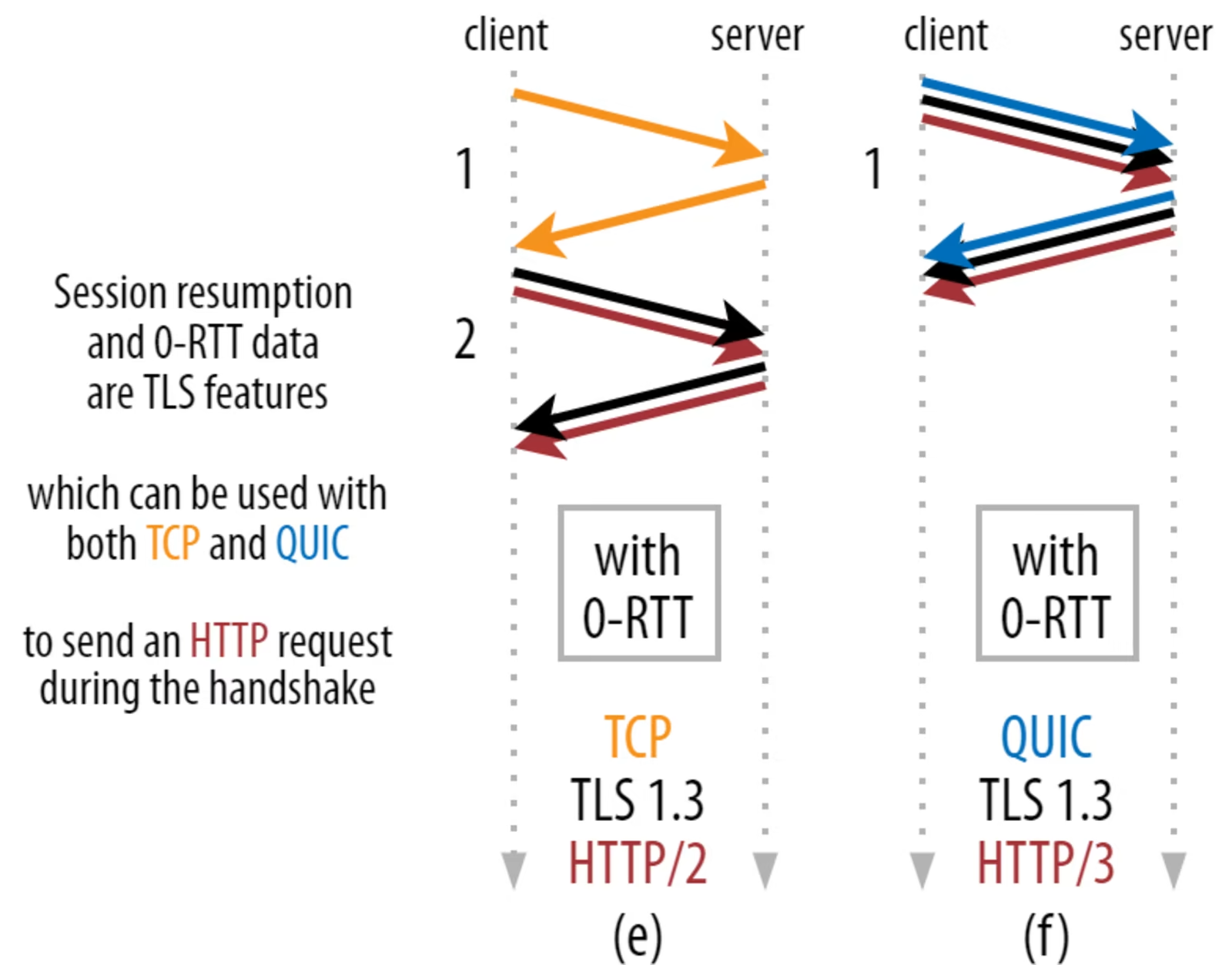
더 큰 문제는 보안 관련 문제로 QUIC이 저 0-RTT를 제대로 활용할 수가 없다는 것이다. 왜인지 알아보자.
TLS handshake 말고 TCP handshake를 하는 이유를 살펴보면
- client가 server측에 higher-layer data를 전달하기 전에 실제로 server이 존재하는지를 파악하기 위해
- server이 connection 요청을 한 client가 실제로 누구고 어디에 있다고 하는지를 파악하기 위해
여기서 두번째가 이번 논의와 관련이 많다. 보통 client가 어디의 누군지 파악하는데 ip주소를 사용하는데, 이 ip주소를 위조하는게 가능하다. 이를 ip spoofing이라고 한다.
이거랑 QUIC의 0-RTT를 활용해 다음과 같은 공격이 가능하다. 공격자가 HTTP를 통해 엄청 큰 파일을 0-RTT QUIC을 통해 요청한다. 이 때 source IP를 공격 대상 컴퓨터의 ip주소로 설정한다. 그러면 server은 request가 오자마자 해당 파일을 공격 대상 컴퓨터에게 보내게 된다. 그러면 피해자의 network bandwidth가 이 요청하지도 않은 파일 전송에 소모되어 아무것도 못하게 된다. 이 공격을 amplification attack이라고 하며 분산 DDoS 공격에 적극 활용된다. amplification attack의 자세한 내용은 다음 링크 참고 (여기는 DNS 활용 amplification attack이다.)

이 방식의 공격은 TCP에서는 불가능하다. 왜냐하면 TCP는 handshake하면서 packet을 보내는게 TLS handshake 도중에 가능한 것이지 그 전의 TCP handshake에서 가능하지 않기 때문이다. 만약 ip spoofing을 한채 TCP handshake를 시작하면 그 reply가 공격 대상 machine에 갈텐데, 거기서 '뭐지?'하고 무시하면 연결이 구축이 안되서 공격자가 공격 대상 machine에 엄청난 traffic을 전달하는게 불가능하다. 하지만 QUIC은 TLS랑 connection request가 동시에 이루어지며, 거기에 data요청까지 할 경우 connection request에 대한 reply랑 요청한 data traffic이 공격 대상 machine에게 도달하기 때문에 문제가 되는 것이다.
이 때문에 QUIC 활용 서버는 0-RTT request에 대해 답변을 내릴 때 좀 신중하게 해야 한다. 그 방식이 뭐냐면 0-RTT 요청을 할 때 건넨 data의 3배만큼만 처음에 reply하는 방식이다. 굳이 '3'이라는 숫로 한 이유는 안전하면서 최대한 성능을 이끌어내기 위해 연구한 결과라고 한다. (이전에 51000으로 했다가 당한 케이스가 있다고 함)
보통 client는 처음에 1~2개의 packet을 보낸다. 그리고 server에서 다시 reply를 보낼때 순수 내용물 말고도 다른 내용물도 겸해서 전송해야 하다보니 0-RTT를 통해 받는 첫 packet의 크기는 보통 최대 4~6KB에 불과하다. 저런...
게다가 보안 문제가 이것만 있는게 아니다. replay attack에도 이게 취약한데, 이 때문에 0-RTT때 요청 할 수 있는 HTTP request가 제약이 있다. 예를들어 Cloudflare은 0-RTT때 query parameter이 없는 GET request만 허용한다. 저런...
물론 이걸 개선하기 위해 유효한 connection을 만들었던 IP에서 또 0-RTT 요청이 들어온 경우에는 제한 없이 바로 data를 보내는 옵션이 있긴한데 IP주소가 같아야 하다보니 요청자가 계속 같은 network하에 있어야 해서 connection migration(후술)이랑 잘 호환이 안되고 설령 이게 잘 작동한다 해도 어쨌든 이후의 연결에서는 TCP랑 유사한 congestion control 알고리즘 하에 통신이 이루어져서 TCP 대비 어마무시한 속도 증진이 있는건 아니다.
여담으로 저 첫 요청에서 건넨 data의 3배만 처음에 전달하는건 0-RTT가 아니더라도 지켜야 한다. 만일 TLS 인증서가 엄청 커서 4~6KB가 넘어선다면 첫 reply때 다 반환이 안된다는 것인데, 그러면 RTT가 하나 늘어나고, 그래서 TCP랑 TLS를 합한 녀석과 RTT가 똑같을 수 있다.(?) 이 때문에 인증서 압축과 같은 테크닉들이 TCP 대비 QUIC에서 훨씬 더 중요함.
또 여담으로, 0-RTT를 개선하는 방식들이 몇가지 더 있는데, 예를들어 서버가 각 client가 연결시에 사용했던 bandwidth를 기억하고 다음에 그 client가 다시 연결을 하면 해당 bandwidth만큼이 여유 있다고 생각하면서 전송을 시작하는 방식이 있다. 학계에서 많이 연구된거고, QUIC에 이를 확장하자는 제안도 나왔으며, TCP에 이를 적용한 기업도 꽤 있다.
아니면 처음 요청때 packet 1,2개 정도 더 padding해서 보내가지고 12~14KB의 response를 처음부터 받을 수 있게 하는 방법이 있다. connection migration이 이루어져도 효과가 있다는건 덤.
아니면 0-RTT서 처음에 3배만큼만 response 보내야 하는게 의무사항은 아니어서 그냥 서버에서 더 많이 보내도록 설정하는 경우가 있다고 한다. 물론 이로 인한 보안 문제는... 거기서 감당해야 한다.
결론은 0-RTT를 통한 빠른 연결은 대격변 수준의 최적화는 아닌 약간의 최적화라고 봐야 하며, latency가 매우 큰 사용자들이 접속하는 경우나 애초에 전송하는 data가 적은 곳 (캐싱이 많이 된 웹사이트 등)에서나 큰 효과를 볼 수 있고 나머지는 큰 효과를 보기가 힘들다. 특히 CDN을 사용하고 있는 곳은 더더욱.
connection migration과 성능 증진
QUIC은 connection migration을 활용해 속도 증진을 노리는데, 이게 뭐냐면 네트워크가 변동되어도 이미 존재하는 연결이 계속 유지될 수 있도록 해주는 기능이다. 이전에 QUIC이 CID를 활용해서 사용 네트워크를 손쉽게 바꿀 수 있다고 했는데 이거랑 관련이 있다.
잘 작동하는 기능이지만 자주 작동하지 않는다는 점과, 전송율이 초기화되는건 여전하다는 단점이 있다.
전자를 먼저 살펴보자. 위 connection migration이 효과를 보이는 경우는 사용하는 ip 자체가 달라지는 경우다. 이 때문에 유의해야하는게 사용하는 Wi-fi access point가 달라진다고 ip주소가 달라지지는 않기에 저게 변할 때 connection migration을 이용한다고 볼 수는 없다. 참고로 그 이유는 무선 연결을 제공하는 곳이 달라지는 것을 처리하는건 network layer보다 하위 layer에서 이루어지기 때문이다. 4G를 쓰다가 Wi-fi를 쓰는 경우가 ip 주소가 변하는 경우에 해당한다.
또 대용량 파일을 받는 경우나 스트리밍 도중에 끊겨서 다시 다운로드를 시작하거나, 스트리밍이 멈추는 것을 피할 수 있는건 좋은데, 하루종일 대용량 파일을 받는것도 아니고 일반 웹페이지 방문 때 이것이 진짜로 도움이 많이 될까? 물론 받는 도중에 끊기면 도움이 되겠지만 사실 웹페이지 받는게 몇분이 걸리는 것도 아니고 보통 몇초만에 끝나기 때문에 그닥 도움이 된다고 보긴 힘들다. 특히 앞에 말했듯 자주 발생하지도 않기 때문에 더더욱.
게다가 사실 이 녀석이 해결해주는 부분도 이미 다른 해결책들이 존재하고 있었다. 예를들어 큰 파일의 다운로드를 제공하는 서버는 HTTP range request를 통해 중간부터 다시 다운로드를 할 수 있도록 해준다.
아니면 네트워크 전환이 이루어질 때 그 전에 둘이 겹치는 타이밍이 있는 경우가 자주 발생한다는 것을 이용해, 스트리밍 시 여러 종류의 연결을 동시에 운용하고 싱크를 맞춰서 나중에 하나가 끊겨도 (네트워크 전환이 있는 것은 눈치채지만) 영상이 완전히 끊기지 않을 수 있도록 하는게 이미 가능하다.
마지막으로, 아까 전송율이 초기화된다고 했는데 그것의 직접적인 원인이 되는 부분으로 새로운 네트워크가 이전과 같은 bandwidth를 가진다는 보장이 없다. 그래서 전송율이 (congestion control 부분에서) 초기화되는 것이다. 이는 스트리밍의 경우 순간적인 품질 저하로 이루어질 수 있다.
즉 connection migration은 사실 성능 증진이 목표라기 보다는 연결이 바뀌면서 data가 뒤섞이거나 네트워크 변환으로 인해 server에서 다시 연결을 구축하는데 발생하는 overhead를 줄이는 것이 목표라고 봐야 한다.
다만 마지막 문제점을 해결하기 위해 각 네트워크에서 사용했던 bandwidth를 기억해서 그걸로 시작하는 방식이 있다. 또 이랑 별개로, 그냥 네트워크가 여러개면 여러개의 네트워크를 동시에 사용하는 성능 증진 방법도 있다.
passive connection migration
위의 내용은 사실 'active' connection migration에 대한 내용이었으나, 사실 'passive' connection migration이라는 것도 존재한다. 바로 특정 네트워크의 연결이 갑자기 본인이 사용하던 parameter을 바꾸는 것이다. 대표적인 경우가 Network address translation(NAT) rebinding이다. 자세히는 설명안할건데 궁금하면 앞의 NAT에 관한 링크를 읽으면 된다. 핵심만 말하자면, 연결의 포트 번호가 갑자기 바뀔 수 있다는 것이다. TCP보다 UDP에서 이런 경우가 더 자주 발생한다.
보통 이게 발생하는 경우는 아주 길게 idle했던 connection에서인데, QUIC의 경우 이를 방지하기 위해 PING이랑 timeout indicator을 사용한다. 그리고 설령 발생해도, QUIC의 CID가 변하지는 않도록 설계가 되어서 대부분의 QUIC 사용처에서는 여전히 연결이 그대로라고 생각해 congestion window나 다른 parameter들을 초기화하거나 바꾸지를 않는다.
그러면 이 점을 고려했을 때, QUIC의 CID는 절대로 안바뀌는 것일까? 그건 아니다. 이전 글에서 봤다시피 보안 문제로 인해 QUIC이 여러개의 CID를 하나의 연결에 대해서 사용할 수 있다고 했고 그게 network가 달라졌을 때 라고 했다. 즉 active connection migration이 발생할 경우 CID가 바뀌는 것이 가능하다.
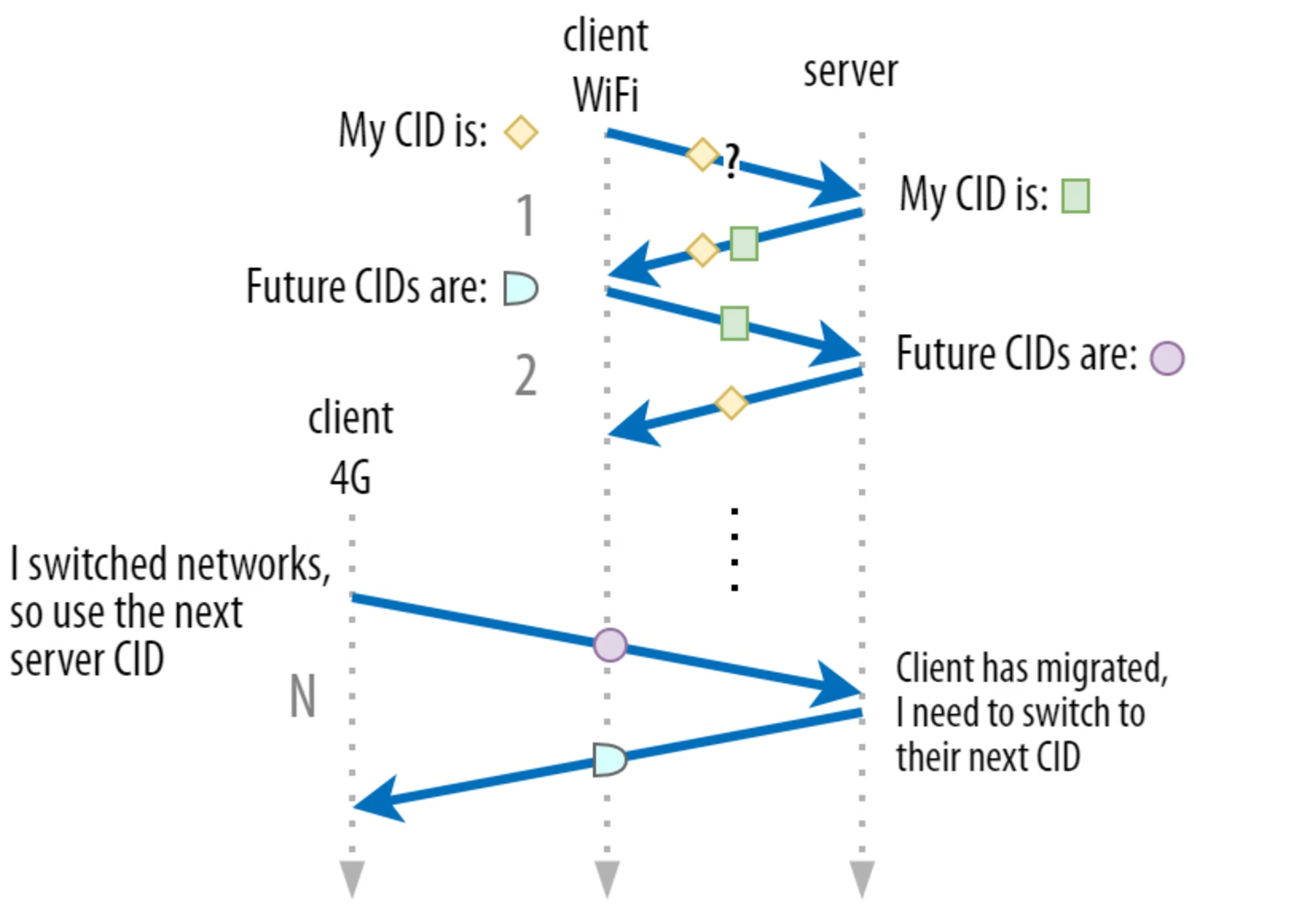
이때 유의해야하는게 한가지 있는데 server랑 client의 CID 형식도 서로 다를 수 있도록 하기 위해 양측에서 통일된 CID를 사용하지 않는다는 것이다. 왜 이런 복잡성을 가미한 것일까? 고급화된 routing과 load-balancing을 하기 위해서다. 지금부터 자세히 설명하겠다.
connection migration 때문에 load balancer들은 단순 ip/port nubmer로 구성된 4개짜리 pair로 load balancing을 하는것이 불가능해졌다. 어떤 연결이 갑자기 다른 ip/port number로 달라지더라도 그게 같은 연결이었다는 것을 인지할 수 없기 때문. 하지만 CID도 active connection migration이 발생하는 경우 CID가 변한다고 했고, 또 설령 그러지 않는 경우라고 해도 특정 백엔드 서버가 어떤 CID에 대응되고 있다는 mapping을 일일이 저장해야 한다는 (memory) overhead가 발생한다.
이 때문에 load balancer 뒤에서 동작하고 있는 back-end server들의 CID는 load balancer이 예측할 수 있는 형식으로 구성이 되어야 한다. CID를 가지고 back-end server을 유추할 수 있는 형식으로 말이다. 심지어 active connection migration이 발생해서 CID가 달라져도 같은 애로 유추할 수 있도록 하기 위해서다. 그런데 client가 server의 CID를 결정하는 권한을 넘겨버리면 이런 형식을 가질 수 있도록 하는게 불가능하다. 즉 서버가 혼자서 CID를 알아서 결정할 수 있어야 한다. 그래서 client랑 server의 CID 형식이 다를 수 있게, 즉 서로 다른 CID를 같은 연결에서 사용할 수 있도록 설계된 것이다.
결론은 connection migration에 대한 성능 증진이 실제로 이루어지는 경우는... 제한적인 환경에서만 가능하다. 그리고 많은 QUIC 활용하는 곳에서 이 기능을 애초에 지원하지 않기도 하다. 설령 지원하는 곳도 보통 본인들의 서비스의 모바일 버전에 대해서만 지원을 한다. 일부는 0-RTT가 얘랑 비슷한 이점을 주니까 필요없다고 하는 곳도 있다.
하지만 방금 문단에서 얘기했던 것처럼 모바일 환경에서 작동되는 프로그램은 이점을 많이 볼 수 있다. 특히 이동하면서 사용되는 경우가 자주 있는 앱이나 웹사이트가 그렇다. 구글 지도, 카카오 택시 등이 대표적. 또 실시간 활동이 이루어지는 비디오 활용 대화, 동시 편집 기능, 모바일 게임 등에서 저점을 높이는데 매우 유용하다는 것도 참고.
Head-Of-Line(HOL) blocking removal과 성능 증진
HOL blocking 문제를 해결함으로써 QUIC은 packet loss가 많은 네트워크에서 기존 TCP보다 빠를 수 있다. 그러나 현실에서 이게 큰 이득을 불러오지 않는다는 것을 지금부터 알아볼 것이다.
stream prioritization
일단 이에 대해 얘기하기 전에 2가지를 먼저 설명해야 하는데 첫번째는 stream prioritization이다. packet loss랑 HOL이 왜 관련이 있는지는 이전 글을 참고하면 알 수 있는데, TCP의 bytestream abstraction에 따르면 bytestream 자체는 여러개인게 맞는데 이게 전부 하나의 파일에서 비롯하는 것으로 생각해서 앞에 있는 요청이 packet loss 발생시 뒤에 있는 요청이 기다려야 하고, 이로 인해 HOL blocking이 생기기 때문이다. 그리고 이 때문에 HOl blocking이 이론적으론 성능에 악영향을 끼치는 요소로 생각이 가능하다
그리고 QUIC에서 여러개의 bytestream을 인지하고 concurrent하게 이를 실행한다고 얘기했었는데, 저번 글을 잘 보면 알겠지만 실제로 여러개의 bytestream을 '동시에'다루는 것이 아니라 하나의 연결에서 뒤섞는 형태 (multiplexing)로 다룬다. 그니까 추상적으로 여러개의 bytestream이 있는것은 인지를 하는데 결국 이것들을 다 하나의 연결에서 처리를 한다는 것이다.
처리 순서가 어떻게 될지는 여러가지 방식이 있다. 3개의 stream이 있다면 ABCABCABC라든가 AAABBBCCC라든가, 그 외의 여러 방식도 존재할 수 있다. 그러면 저 순서는 누가 정하는가? HTTP-level에서 결정을 하며, 이를 담당하는 feature이 stream prioritization이다.
무슨 순서로 뒤섞느냐에 따라 page loading 차이가 클 수 있다는 연구는 이미 꽤 많이 나왔다. 그리고 다양한 브라우저, 심지어 4대 브라우저 (엣지 사파리, 파이어폭스, 크롬)들도 다 사용하는 multiplexing 방식이 다르다. 왜 다른지에 대한 자세한 내용은 원본 링크 참고. 여튼 그 이유를 간단히 얘기하자면, 몇몇 자원은 render blocking을 일으킬 수 있다. 보통 웹사이트의 파일들 중 HTML head에 있는 CSS나 JavaScript에 해당하는 파일로
- 저거 load를 안 하면 브라우저 측에서 페이지에 뭘 올리는 것이 불가능하고
- 저게 '다' load되어야 비로소 사용이 가능함.
이런 resource들은 먼저, 빨리! load를 해야 한다. 그럴려면면 얘네가 priority가 높아야한다. 그러면 만약 bytestream A, B, C가 모두 render blocking이면 어떻게 해야 할까?
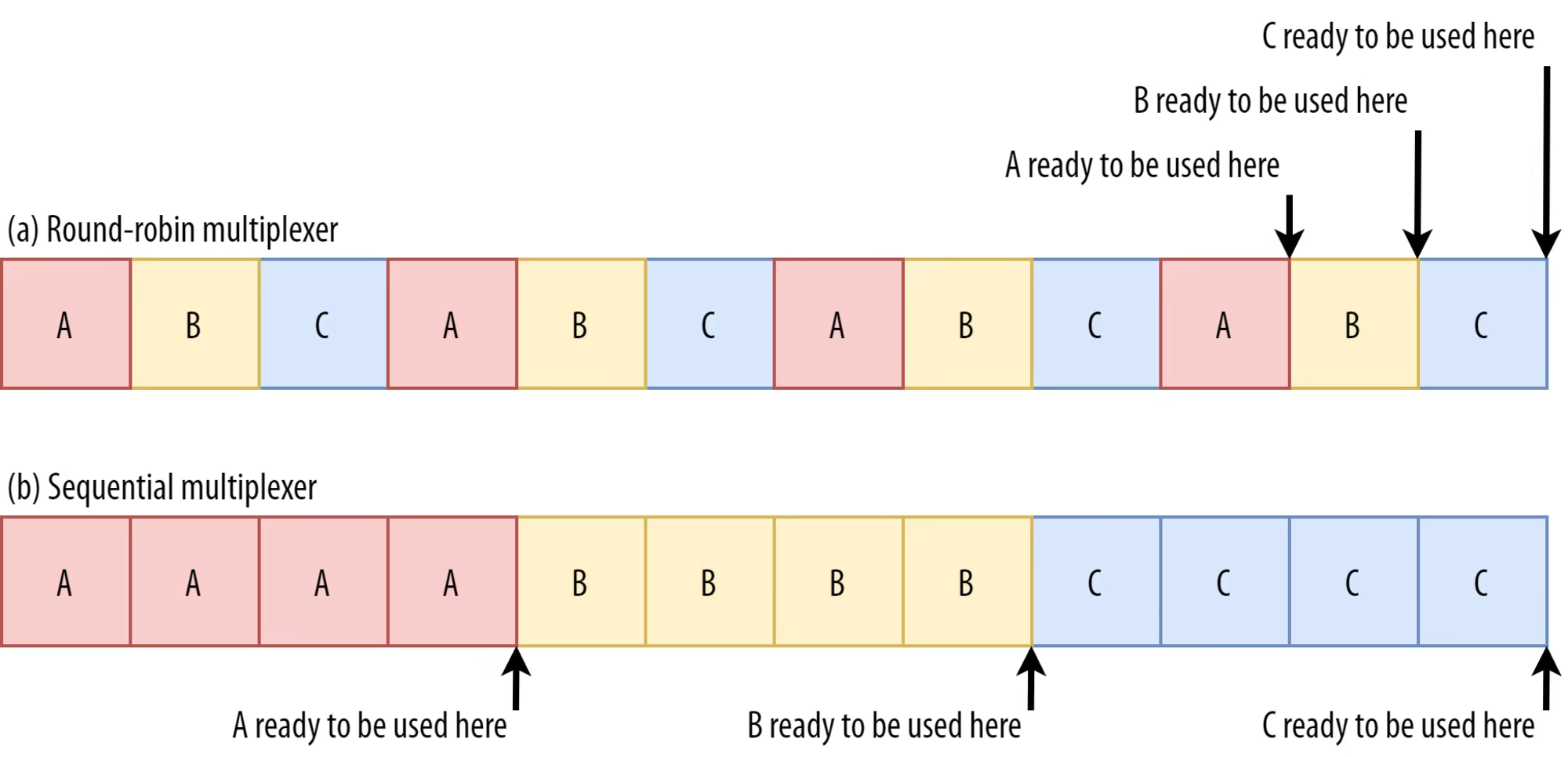
round robin multiplexer의 경우 각 자원들 모두의 완료 시간이 끝부분에 가게 된다. 왜냐하면 bytestream이 여러개여도 어쨌든 connection이 하나여서 bandwidth를 공유하기 때문이다. 그러면 3개가 거의 다 load될 때 즘에야 하나가 load가 완료 된다. 이러면 3개랑 관련된 요소 모두의 delay가 크게 된다...
반면 sequential multiplexer의 경우 하나를 완료한 다음에 다음 bytestream의 render-blocking resource load를 시도하는데, 그러면 짧은 시간에 적어도 하나의 load는 완료가 되고, 마지막 녀석도 round robin이랑 비교했을 때 그렇게 늦게 load되는 것은 아니어서 round robin보다 좋은 정책이라고 볼 수 있다.
이 경우엔 sequential multiplexer이 좋게 나왔지만, 언제나 좋다는건 아니다. 몇몇 resource들은 (예를들면 non-render blocking resource들. HTML이나 progressive JPEG가 해당) 부분이 load되면 사용되고, 그 다음 부분이 load되면 사용되는 형식을 가지는데 이 경우엔 round robin이 명백히 sequential보다 좋다. 이 때문에 무슨 상황을 각 브라우저가 중시하냐에 따라 다른 multiplexing 방식을 택하는건데, 일단 '대부분'의 경우에는 sequential multiplexing이 좋다고 합니다. 크롬이 대표적.
Packet loss resilience
여러개의 byte stream들이 '동시에' active하지 않고, 그 순서도 위의 multiplexing 방식을 어떻게 하냐에 따라 다양해질 수 있다는 것을 배웠다. 그러면 이제 packet loss가 발생할 때 뭐가 일어나느지 얘기를 할 수 있다. QUIC의 경우 특정 stream이 pakcet loss를 겪더라도, 그거랑 관련이 없는 stream에 대한 처리를 계속 할 수 있다고 했다. (TCP는 그냥 다 멈추고)
여기서, 아까 render blocking resource들의 영향으로 인해 여러개의 byte stream을 운용하는걸 사람들이 그렇게 선호하지 않는다. 앞에 설명했듯이 render blocking resource '전체'가 다른 resource loading에 필수적이기 때문에 어떻게든 다 load를 해야 하는데 byte stream이 여러개면 그만큼 후순위로 밀릴 수 있기 때문. 당장 앞에서 A, B, C라는 byte stream 3개를 운용해서 결국 C라는 녀석이 render blocking resource를 빨리 load해야 함에도 뒤로 미뤄진 것을 생각하면 이해가 될 것이다. 이와 같은 이유로 round-robin multiplexing도 선호를 하지 않는다. sequential을 해야 하나라도 빨리 render blocking resource가 load 되기 때문.
문제는, byte stream을 적게 하고 sequential multiplexing을 적용하면 QUIC의 HOL blocking removal을 위해 애쓴 디자인이 무용지물이 된다는 것이다.
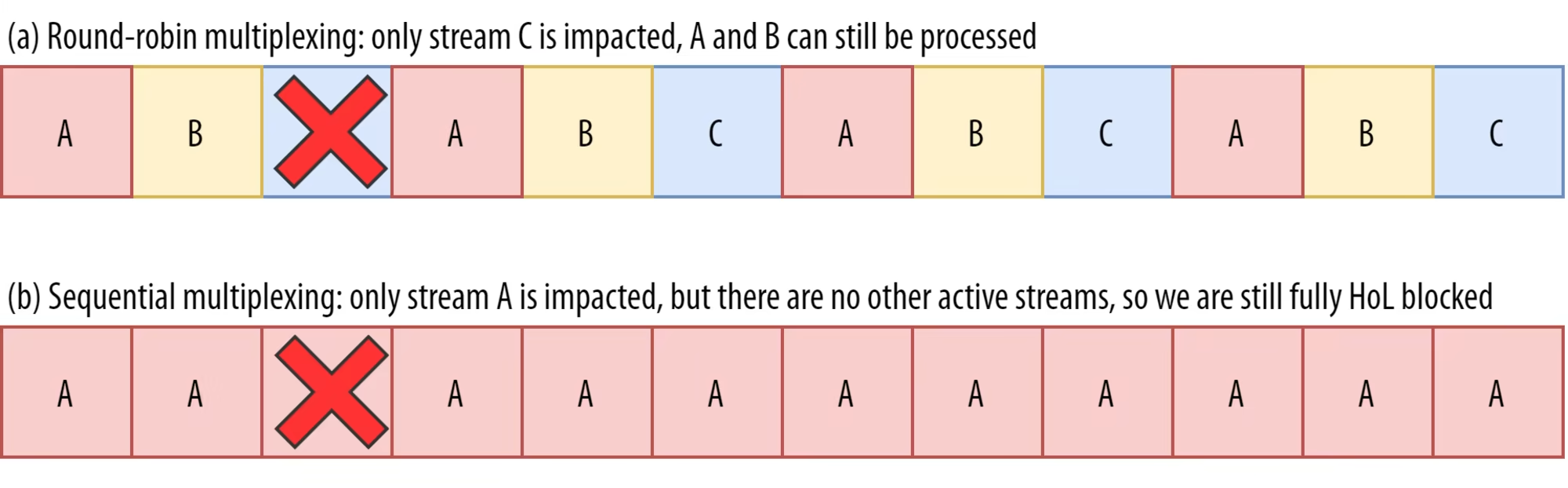
예를 들어 송신자가 특정 연결에서 최대로 유지할 수 있는 전송중인 packet 개수가 12개라고 해보자. (알다시피 이런것은 congestion controller에 의해 조절되며 충분히 일어날 수 있는 상황이다.) A가 render block과 관련된 byte stream이라 이 가용량을 전부 A로 채워넣으면 (중요하고, 전부 load를 해야 의미 있으니 저럴만하다.) 위의 (b)와 같은 상황이 나오겠지요. 그리고 보시다시피 하나라도 drop가 되면? 뒤의 애들도 전부 block이 된다. HOL block 발생. 다른 대체할 byte stream이 없기 때문이다.
즉 앞 소단원에서 논의한 내용과 종합하자면
- sequential multiplexing : round-robin 대비 일반적으로 좋은 성능을 내는데 정작 TCP에 있었던 HOL blocking을 제대로 제거를 못함...
- round robin multiplexing : sequential 대비 HOL blocking에 면역이 생기는데 일반적으로 좋은 성능을 못냄...
망했다! 게다가 더 중요한 문제가 뭐냐면 지금은 한번에 하나의 packet만 loss 된 경우를 따졌지만 현실에서는 한번에 여러개의 packet이 loss 되는 경우가 많다는 것이다.
congestion controller의 동작 방식을 생각해보면 과포화를 방지하기 위해 만드는 녀석들이다만... 뭐 congestion control에 대해 자세히 다룬 글에서 봐도 마찬가지지만 packet loss가 발생할 때까지 일단 멈추지 않고 계속 보내는 개수를 늘리기 때문에 과포화를 유발하는 녀석으로 생각하는 것도 가능하다.
이 얘기를 갑자기 왜 하는거냐면 congestion control 알고리즘을 보면... congestion controller들이 처음에는 천천히 보내다가 나중에 몰아서 packet들을 보내다보니 좀 시간이 지난 후에야 과포화가 발생하게 되고, 이 때문에 각 연결에서 packtet을 어느정도 보낸 이후에 갑자기 우수수수 loss가 발생할 수 있다는 것이다. 그래서 앞에 말한것처럼 한번에 여러개의 packet이 loss되는 경우가 많다는 것이다.
참고로 이 때문에 HTTP/2가 기존의 HTTP/1.1과는 다르게 하나의 TCP 연결만을 만들어서 운용하는 것이다. HTTP/1.1처럼 TCP 연결 여러개를 만들면 위의 이유로 갑자기 여러 연결에서 여러 packet loss가 발생할 수 있기 때문. 사실 크로뮴 개발자들이 연구한 결과에 따르면 이게 인터넷에서 packet loss가 발생하는 주된 원인이라고도 한다. 그리고 이 때문에 BBR이 congestion control algorithm으로 많이 사용되는 것이라고 한다.
BBR은 Bottleneck Bandwidth and Round-trip propagation time의 약자로, 구글에서 개발했으며 기존의 congestion control algorithm과는 다르게 packet loss를 congestion의 신호로 생각하지 않고 RTT가 요동치는 것을 congestion의 신호로 생각한다. 예상되는 bottleneck bandwidth와 RTT를 기반으로 최적화된 최대 packet수를 계산함으로써 이를 이룬다. packet loss가 애초에 유발되지 않는다는 것이 고전 congestion control algorithm과의 가장 큰 차이점이자 장점이라고 볼 수 있다. 자세한건 링크 참고
참고로 여기서는 transport layer 차원의 packet loss만 얘기를 하고 있으며, 실제로는 wireless network같은걸 사용할 때 lower layer에서도 packet loss가 발생할 수 있다. 무선 통신에선 lower layer에서 생각보다 packet loss가 쉽게 일어난다. 다만 이게 transport layer의 packet loss로는 이어지지 않는다. 보통 해당 layer에서 다 처리하기 때문. 대신 packet의 도착 시간이 transport layer 입장에서는 보낸 순서에 안 맞고 뒤죽박죽 섞이는 현상으로 나타난다.

위의 그림을 보도록 하자. 우리가 round-robin multiplexer을 사용해 HOL을 제거하려고 애쓴다고 가정해보자. 여기서 4개의 packet이 연속으로 동시에 loss가 이루어졌다고 해보자. (보통 여러개가 동시에 loss가 발생하면 연속으로 loss가 발생하는게 일반적이다. 대충 위에 읽어보면 느낌이 오겠지만 말이다.) 그러면... 결국 위의 그림같은 경우 round robin multiplexer도 딱히 HOL 제거 효과를 누리지 못하는걸 알 수 있다... (b)에 해당한다. 오히려 byte stream이 여러개인 sequential multiplexer이 더 면역이 있다는 것을 볼 수 있다. (c)에 해당한다. 저 경우에는 C byte stream에 대해서 작업하면 되기 때문. 물론 앞에서 봤듯이 sequential multiplexer은 특정 상황에서 저렇게 많은 bytestream을 애초에 형성하지 못하겠지만 말이다.
결론은, QUIC의 HOL blocking 제거가 실제로 잘 작동하냐 안 하냐를 파악하기는 힘들다. stream이 몇개냐, packet loss가 몇개가 동시에 얼마나 자주 일어나냐, stream이 어떻게 배치되냐 등에 따라 다르기 때문. 그러면 일반적인 측정 결과에 따르면? 별로 도움이 안된다 보통 concurrent한 stream이 여러개인걸 선호하는 상황이 잘 안나오기 때문이라고 한다. render blocking resource 때문.
물론 앞의 단원들과 마찬가지로 이를 해결하는 고급 기술들이 존재하긴 한다. 앞의 BBR congestion control이 대표적이고, packet pacing이라는 congestion control 기법이 있는데, 기존에는 활용할 수 있는 packet 전송 개수가 5개고 5개가 전송 대기중이면 한번에 다 보냈더라면, packet pacing은 이것을 하나의 RTT에 전송이 되도록 '퍼뜨려서' 전송을 하는 것이라고 생각하면 된다. 그러면 네트워크가 '한번에' 여러 packet을 받지 않는다는 것을 볼 수 있지요? 실제로 QUIC Recovery RFC에서 이를 매우 권유하고 있음.
현재 이 HOL 제거 방식은 잘 caching이 된 page들에 대해서 지속적인 재방문을 할 때 가장 잘 활용되낟고 한다. 그 외에도 background download, single-page app에서의 API call 등에서 효과를 보인다고...
UDP, TLS 관련 성능 증진
이제 QUIC과 HTTP/3이 packet을 생성하고 네트워크에 전달하는 효율이 실제로 얼마나 좋은지에 대해 알아보자. QUIC가 UDP를 활용하는 방식, 그리고 encryption 방식 때문에 TCP보다 약간 느리다는 것을 배울 것이다. (다만 계속 개선이 이루어지고 있다고 한다.)
앞의 글에서 QUIC이 UDP를 쓰는 이유가 성능 때문이라기보다는... 쉽게 deploy가 되도록, 쉽게 변형이 되도록 하기 위해서라는 것을 배웠다. 애초에 뒤에 TCP 쓰는것보다 이게 느리다고 했는데 성능 때문에 쓴다고 하기는 좀... 그러면 왜 느린걸까?
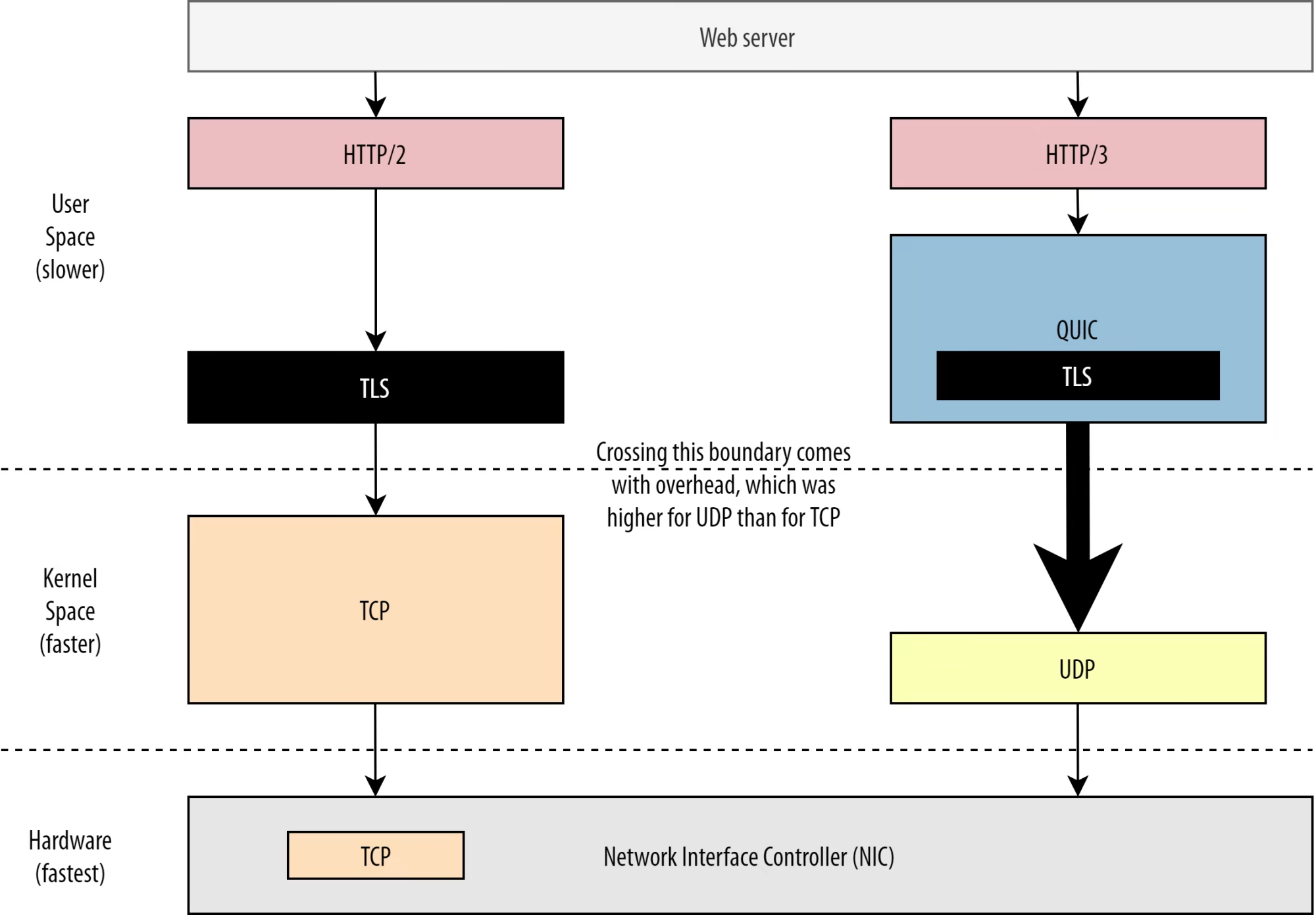
TCP/UDP는 보통 OS kernel에서 구현이 이루어진다. 또 QUIC가 TLS는 user space에서 돌아간다는 것도 앞에서 봤다. (사실 QUIC은 꼭 user space에서 돌아갈 필요는 없다만 유연성을 위해 그냥 거기서 구현되었다.) 그런데 user space에서 돌아가는게 보통 느리다. 지금 위의 그림에 봤다시피 TCP보다 QUIC이 이미 더 많은 요소가 user space에서 돌아가는 것을 볼 수 있다. 그러니 벌써부터 느릴만한 기미가 보인다.
OS측에 user space data를 전달하려면 OS kernel의 API에서 제공하는 system call을 활용해야 한다. 시스템을 공부하면 알고 있을텐데, 이거 엄청 느리다. 그리고 TCP에 비해 QUIC 측에서 이 API를 활용할 때 생기는 overhead가 훨씬 크다. 이유는... TCP가 그냥 UDP보다 많이 쓰여가지고 system call들이 전부 TCP에 초점을 맞춰서 최적화가 이루어졌기 때문이다. 그런데 QUIC은 UDP를 써서... 그 최적화를 제대로 못 누리는 것이다. 심지어 TCP는 하드웨어 최적화(...)까지 받았다. 다행히도 21년 기준 5년 사이에 UDP와 관련된 최적화 옵션도 많이 생겼다고 한다.
또 다른 TCP가 빠른 이유는 QUIC은 packet을 만들 때 하나씩만 만들지만 TCP는 한번에 여러개의 packet을 만드는 것이 가능하다. 참고로 QUIC이 이런 느린 방식을 택한 이유는 또 다른 HOL blocking을 막기 위해서라고 한다. 이 때문에 이거랑 관련된 성능 문제는 앞으로 개선되길 바라기 힘들다.
다만 최적화된 encryption library나 몇몇 스마트한 방식을 통해 QUIC packet header들을 '한번에' encrypt하는 것이 가능하다고 한다. 초창기 QUIC은 TCP + TLS보다 2배나 느렸으나, 현재는 대략 1.33배 정도 더 느리다. 그 외에도 여러 최적화 작업이 이루어져 있어서 현재 TCP + TLS랑 비슷한 속도를 내는 것이 가능하다고 한다.
아니 애초에 2배 느려도 별로 상관 없는게 서버가 평소에 TCP+TLS관련 작업만 한게 아니다. 뭐 HTTP, caching, proxying등 여러 작업을 함께 하고 있었기 때문에 2배 느린 경우라고 해서 진짜로 서버를 2배로 늘려야 하는 (...) 상황이 생기진 않는다. 아 물론 실제 datacenter에서 이것 때문에 증설을 해야 했는지 아닌지는 판단이 불가능한게 자료를 공개한게 하나도 없어서...
뭐 실제로 느리면 더 증설을 해야 했다고 하더라도 위에 봤다시피 많이 개선이 이루어졌고, 여전히 개선할만한 영역이 많이 남아있다. 예를들어 일부 QUIC 부분이 OS kernel로 이동한다든가, OS를 거치지 않고 작업을 한다든가 등. 아니면 QUIC 최적화된 하드웨어를 만든다든가! 실제로 계획된게 있다고도 하고.
다만 모든 기업이 QUIC으로 넘어갈 것으로 보이진 않는다. 넷플릭스가 대표적인데, 이미 TCP+TLS에 극한으로 최적화된 셋업을 만들었기 때문에 굳이 또 바꾸는 모험을 하고 싶지 않다고... 또 페이스북의 경우 이 packet관련 오버헤드 때문에 end user과 CDN 사이의 연결만 QUIC으로 사용하겠다는 얘기를 했다. 즉 data center 사이, 혹은 edge node와 origin server 사이의 연결은 여전히 TCP를 쓰겠다는 것이다. 정확히는 매우 높은 bandwidth를 중시하는 곳에서는 여전히 TCP+TLS를 계속 선호할 것이라는거다.
결론은, 그냥 저 관점에서 QUIC은 TCP+TLS보다 느리거나 비슷하다. 시간이 지나면 좀 더 간격이 좁하지거나 더 나아질 수도 있겠지만 말이다. 이 간격이 일반적인 웹페이지 load에서는 크게 문제가 되진 않겠지만, 여러 서버를 운영하는 사람 입장에서는 머리 아플 수 있다.
HTTP/3 관련 기능
지금까지는 사실상 QUIC이랑 TCP 간의 차이점에 관한 얘기라고 볼 수 있다. 그런데 사실... 이거 시작이 HTTP/3에 관한 얘기였잖아요. HTTP/3과 HTTP/2 사이의 차이점은 뭐 없을까?
미안하지만 앞에서 말했다시피 HTTP/3이 그냥 HTTP/2를 QUIC 위에 올리기라서 새로운 기능이 '하나도' 만들어지지 않았다. 그냥 옮긴거다.(...) 다만 구현 방식에 좀 많이 차이가 생겼을 뿐이다.
구현 방식 차이의 원인은 QUIC이 HOL blocking을 제거하려고 하다 보니 여러개의 byte stream들을 독립적으로 생각하게 되었고, 그래서 하나의 byte stream이 다른 byte stream의 특정 packet loss되었다고 기다릴 필요가 없게 되었고, 이 때문에 특정 순서로 packet을 보냈을 때 관련 byte stream이 보낸 순서대로 간다는게 보장되지 않기 때문에 그렇다. 예를들어 A, B, C 순서로 뭘 보내면 관련 byte stream 완료가 B, A, C 순서로 완료 되어서 B, A, C 순서로 상대방에게 도달하는게 가능하다.
HTTP/2에서 순서대로 오는 것에 의존을 많이 했기 때문에 이게 문제가 된다. 특히 특별한 control message들을 server측에 보냈는데 거기서 뒤죽박죽 순서로 받아가지고 원하는거랑 하등 상관없는 순서로 처리가 될 수 있기 때문.
HTTP/3에서 이걸 해결하기 위해 기존 기능들의 새로운 구현방식을 만든 것이다. 대표적인게 HTTP Header Compression으로 HTTP에서 큰 HTTP header들이 반복적으로 전송되는 overhead를 줄이기 위해 만든 것인데 HTTP/2의 경우 이를 HPACK을 통해 했다면, HTTP/3의 경우 좀 더 복잡한 QPACK을 통해 이를 구현했다.
앞에서 잠깐 나온 HTTP의 prioritization 기능도 구현 방식이 달라졌다. HTTP/2의 경우 좀 복잡하게 했는데 dependency tree를 사용해서 모든 page resource와 이들 사이의 관계를 나타내려 했다. 이 tree에 resource를 추가하는게 하필 control message로 하는 것이다보니 QUIC에서는 앞에 봤다시피, 이들의 순서가 달라질 수 있어서 그대로 적용하기가 힘들다.
게다가 사실 이전에 사용했을 때 이게 쓸데없이 복잡해서 제대로 효율이 안나온다든가, 구현 관련 버그가 많았다든가 등의 문제가 있었다고 한다. 몇몇 서버에서는 원하는 만큼의 효율이 제대로 나오지 않았다고도 한다. 그래서 HTTP/3에서 이를 간단하게 구현할 수 있도록 디장니을 다시 했다. 몇몇 고급 시나리오에 대해서는 처리가 힘들거나 아예 불가능하지만... web-page loading 관련 최적화에 대해 많은 옵션을 여전히 제공해 줄 수 있기 때문에 좋다고 볼 수 있다. 또 쉬워진 디자인이다 보니 구현 상의 버그가 덜 나타날 것이라는 희망을 가질 수 있죠.
마지막으로 server push라고 server이 사용자 측에서 요청하기 전에 미리 특정 HTTP response를 제공하는 기능이지요. 이론적으로는 엄청난 효율을 낼 수 있지만 현실에서 보니 제대로 쓰기 힘들거나 구현 방식이 이곳 저곳 다 달라서 꼬인다든가 등의 문제가 있어가지고 크롬에서 아예 제거를 했었다고 얘기했지요. 그래도 HTTP/3에 여전히 남아 있습니다! 다만 구현이 달라졌어도 여전히 관련 문제들이 해결될 것으로 보이진 않는다고 합니다.
결론은, HTTP/3랑 HTTP/2는 기능 구현에만 차이가 있지 기능상 차이는 전혀 없습니다.
현재 이루어지고 있는 확장자
앞에서 말했듯 QUIC의 최대 장점, 즉 HTTP/3의 최대 장점이 사실 확장성이라 많은 확장자가 활발히 연구되고 있다.
Forward error correction
QUIC이 packet loss에 더 면역을 가질 수 있도록 하는 기능. 같은 data를 여러번 보내고, 만약 packet이 loss되었지만 이 여러번 보낸 data 중 하나가 잘 도달하면 재전송을 하지 않는 기능이다.
구글에서 원래 QUIC에 넣을려 했으나, 진짜로 성능이 좋은지 확인이 안되가지고 들어가지 않음.
Multipath QUIC
Wi-fi에서 셀루러, 즉 4G등으로 이동할 때 connection migration이 이루어진다고 했는데 그냥 둘 다 쓰자는 확장자(...)
구글에서 원래 QUIC에 넣을려 했으나, 구현이 복잡해서 안 넣었었다. 하지만 잠재성이 높아서 추가될 확률이 높은 기능 중 하나라고 한다. 참고로 TCP는 이미 이게 존재하는데 상용화되는데 몇십년 걸렸다(...)
Unreliable data over QUIC and HTTP/3
QUIC은 완전히 reliable하다. 하지만 UDP는 reliable하지 않다. 그러니까 QUIC도 unreliable하게 변형시키는게 가능하다(?)
보통 이런 unreliable한 data 전송은 web page를 전송하는데는 별로지만 게임, 생방송 스트림 등에는 유용하기 때문에 UDP의 장점과 QUIC의 encryption 측면 장점에 선택적인 congestion control을 가질 수 있다는 점에서 추가되면 괜찮은 기능...
WebTransport
보통 JavaScript에게 TCP나 UDP가 노출이 되진 않는데 보안적인 이유가 크다. 이들은 보통 HTTP 차원의 API들을 활용하거나 WEbSocket, WebRTC protocol을 대신 활용해 lower layer과 통신을 하는데, WebTransport는 이 API들 중 가장 최근에 논의되고 있는 녀석이라고 생각하면 된다. HTTP/3를 좀 더 low-level한 방식으로 활용할 수 있게 해주는 녀석이다.
HTTP/3를 활용한 unreliable data 활용이 대표적이라고 볼 수 있다. 그러면 browser에서 게임같은것을 구현하는게 훨씬 쉬워지겠지요. 일반적인 API call까지 전부 이 API call로 대체되진 않고 일부 상황에서만 쓰일 API를 개발중이라고 생각하면 된다.
DASH / HLS video streaming
라이브 형태가 아닌 비디오들, 그러니까 유튜브나 넷플릭스 같은 경우 브라우저들은 보통 Dynamic Adaptive Streaming over HTTP(DASH)나 HTTP Live STreaming (HLS) protocol을 활용한다.
일단 둘 다 비디오들을 작은 조각으로 나눠서 (2~10초) 여러 화질로 인코딩을 보통 한다. 구체적인 활용 방식은, 브라우저에서 현 네트워크에서 감당이 가능한 최고 화질을 파악한 다음에 서버에 관련 화질과 관련 비디오를 요청하는 것이다. 그런데 이 때 HTTP를 통해 하며, kernel측에 구현된 TCP를 보통 직접적으로 활용하진 못하기에 감당 가능한 화질 계산에 오차가 생기거나 갑자기 변하는 네트워크 환경에 적응하는데 좀 시간이 걸리는 경우가 있다.
하지만 QUIC은 browser측 layer에서 구현이 되어 있다보니 streaming estimator들이 좀 더 낮은 level의 protocol 관련 정보를 접근할 수 있도록 함으로써, 저런 오차나 환경 적응 관련 문제들을 해결할 수 있도록 도와줄 수 있다.
HTTP/3 말고 다른 protocol을 QUIC 위에 구현하기
아무래도 HTTP/3도 TCP위에 동작하던걸 QUIC 위에 동작하도록 만든것이다보니 DNS나 SMB, SSH를 QUIC 위에 동작하도록 하는 연구도 이루어지고 있다고 한다.(?)
결론은, 사실 지금 나온 QUIC은 앞으로의 무궁무진한(?) 발전을 위해 첫 발걸음만 내딘 것이라고 생각하면 된다.
conclusion
이 글의 작성자는 벨기에 사람이며, 이 때문에 벨기에를 기준으로 많은 성능 측정을 했는데, 벨기에 하위 10%에서 보통 네트워크 성능 증진을 얻을 수 있었다고 한다. 그러나 전세계에는 벨기에보다 인터넷이 느린 곳이 많다. 그런데 QUIC이랑 HTTP/3의 경우 이런 곳에서 특히 좋은 효율을 낼 수 있기 때문에... 결론은 QUIC이랑 HTTP/3를 최대한 빨리 활용하는 것이 중요하다고 이분은 말하고 있다.
특히 앞으로도 계속 발전할거고, 더 빨라질 것이기 때문에 더더욱 이 protocol을 활용해야 한다고 주장하고 계신다.
