이전 글에서 HTTP2까지에 대한 설명을 간략히 했었다. 이번 글에서는 현재 최신 버전인 HTTP3에 대해서 알아보도록 하겠다.
본 글은 시리즈 형태가 될 것이고, 아래 글을 번역했고 거기에 몇가지 첨언을 더했습니다.
HTTP/3 From A To Z: Core Concepts
We need to learn technical details
HTTP/3를 제대로 활용하려면 기술적인 부분을 많이 알아야 하기 때문에, 이전의 HTTP/0.9~2에 대해 설명한 글과는 다르게 기술적인 영역들을 심층적으로 다룰 것이다.
사실 이는 HTTP/2도 마찬가지다. HTTP/2가 막 등장했을 때도 새로 추가된 기능들의 implementation에 대해 잘 알아야만 어떤 추가된 기능이 유용한지, 유용한 기능들은 어떻게 구현해야 하는지, 그리고 어떤 예전 기능들은 그대로 사용을 해야하는지를 알 수 있었다. 새로 추가되었다고 무조건 유용한것도 아니었고, 새로운게 나왔다고 예전 방식들을 전부 갈아엎어야 하는것이 아니었다는 뜻이다. 심지어 구현을 제대로 이해하지 못해 성능이 안 좋아지거나 버그가 발생한 경우도 있다. 예를 들어
- HTTP/2의 server push 기능은 현실에선 그닥 도움이 되지 않는 기능이었다.
- HTTP/2 multiplexing 및 prioritization이 제대로 구현되지 않아 제성능을 못낸 경우가 많았다.
- 몇몇 과거 테크닉들이 여전히 유용한 경우가 있었다.
- preload hint와 같이 protocol behavior에 영향을 줄 수 있는 기능을 오남용해서 전체적인 성능을 망치거나 버그를 일으킨 경우가 있었다.
다만 HTTP/2보다 HTTP/3의 기술적인 부분에 더 집중하는 이유는 가장 최근에 나온 protocol이고, 은근히 비중이 있지만 자세히 다루는 곳이 생각보다 없기 때문이다.
(아직은 HTTP/2가 훨씬 많은 비중을 차지하고, 현재 HTTP/3, 정확히는 QUIC이 주류가 될 수 있다는 것에 대해서는 꽤 부정적인 상황이기 때문에 시간이 되면 HTTP/2의 세부적인 내용도 공부해볼 생각이다.)
이번 글은 자세한 구현에 대해 알아보기 전에 HTTP/3가 왜 등장하게 되었는지, 그리고 대략적인 동작 원리가 무엇인지에 대해 알아볼 것이다.
Why new protocol?
HTTP/2는 2015년에 등장했는데, HTTP/3는 불과 7년인 2022년에 새로운 표준으로 등장했다. HTTP/1.1 표준의 최종 개선안이 1999년인걸 생각하면 이전에 비해 새로운게 더 빨리 등장했다. 그러면 왜 등장하게 되었을까?
등장 배경은 새로운 HTTP protocol이 필요해서가 아닌, Transport layer 측에 개선 사항이 필요해서 만들어진 것이다.
HTTP/2랑 관련된 transport layer은 TCP였다. 그리고 이 녀석의 가장 큰 특징은? reliability, in-order delivery, 그리고 congestion control을 통해 여러 연결들이 공평한 bandwidth를 가지도록 조절할 수 있다는 것. 특히 reliability가 유용했는데, 유실되는 data가 없음을 100% 보장해주기 때문이다.
HTTP/2의 구조는 정확히는 밑 그림의 왼쪽 부분과 같았다. (밑의 TLS는 security 담당으로 굳이 OSI에 대응시키자면 presentation layer에 해당한다. 자세한건 이 글 참고
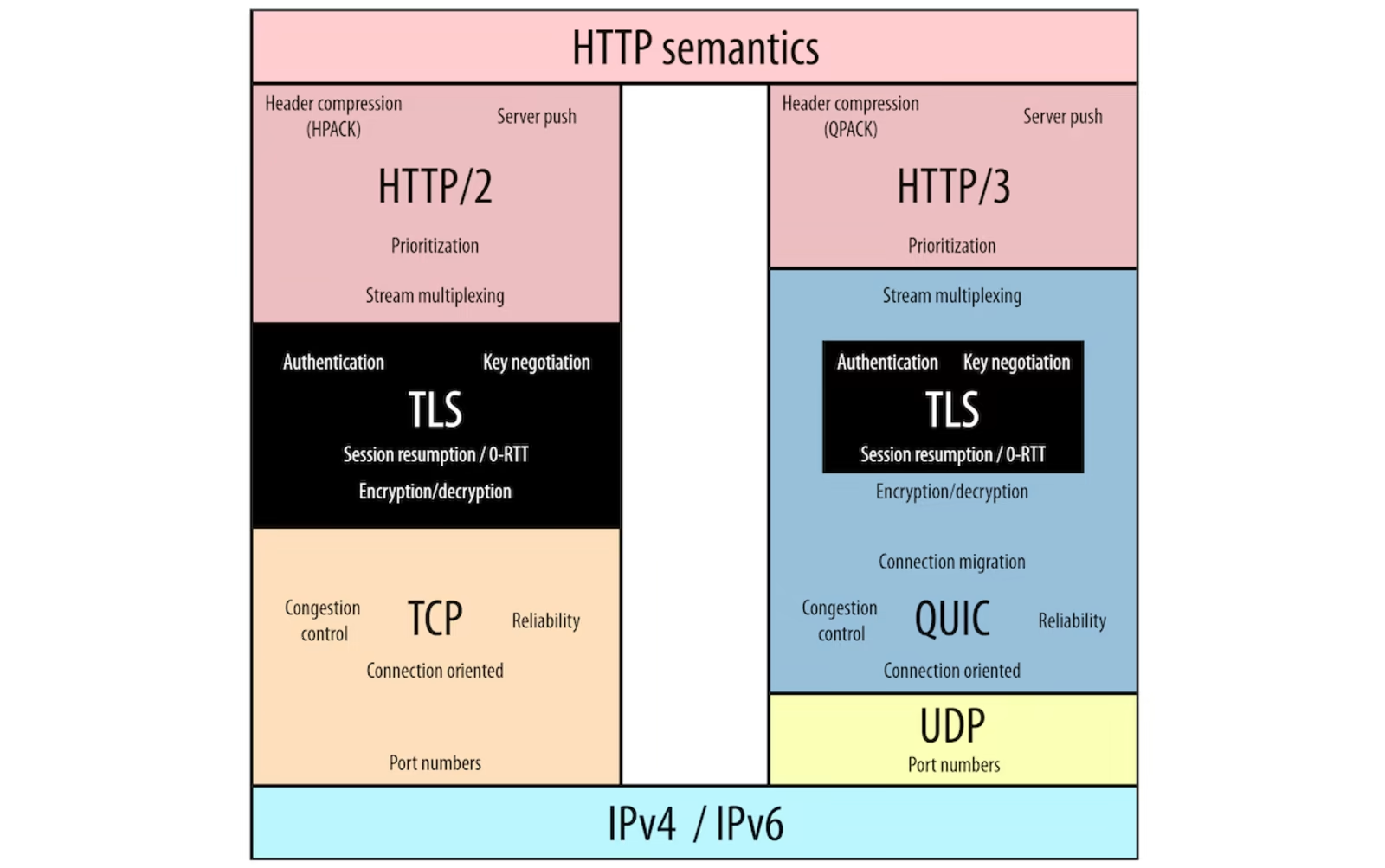
하지만 2000년대 후반, 결국 HTTP protocol에서 사용할 transport lyaer을 TCP 대신 QUIC으로 대체하려는 움직임이 등장한다. 그 이유는 TCP가 성능면에서 그렇게 '극한으로' 효율적이지 않았기 때문이다. 애초에 성능을 극대화하는걸 고려하지 않은 protocol이었기 때문. 구체적인 이유는 2가지인데
-
server과 client가 서로 connection 구축을 위해 진행하는 handshake에서 client->server->client 형태로 round trip이 한번 이루어지는데 이거 자체가 은근 손해
-
Head of Line blocking. 이전에 HTTP/2에서 HOL blocking을 multiplexing을 통해 해결했다고 했으나 이는 HTTP protocol level에서 해결한 것이고, 사실 TCP의 경우 여전히 HOL blocking 문제가 존재하고 있다. 이는 TCP가 in-order이면서 reliable을 보장하려다 보니 그런데 HTTP때의 HOL problem이랑 뭐가 다른지는 후술.
TCP가 처음에 나왔을 때부터 있었던 잠재적 문제였으나, 등장 당시엔 이를 무시하면서 사람들이 써와도 별 상관이 없었다. 하지만 더이상 무시하지 못하게 된 것이다.
다만 처음에는 이 문제를 해결하기 위해 TCP를 통재로 대체할 protocol을 연구한게 아니라, '개선된' TCP를 만들려는 움직임이 많이 있었다. 통째로 바꾸면 이를 사용하던 상위 layer, 즉 HTTP도 영향을 받을 것이기 때문이다.
첫번째 문제의 경우 TCP Fast Open이라고, client가 이미 예전에 연결했던 server과 연결을 시도할 시 handshake 과정에서 data도 함께 보낼 수 있도록 해가지고 handshake 과정에서 낭비되는 RTT를 줄이는 방식.
두번째 문제의 경우 Multipath TCP라고, 간단한 예시를 들자면 우리 스마트폰에 cellular network랑 wifi가 둘 다 있는데, 둘 다 통신에 사용하자는 기적의 논리(...)
이 둘은 생각보다 구현이 어렵진 않다. 전자는 해당 용도를 위한 쿠키를 또 만들면 되고, 후자는 NAT 동작 방식만 좀 튜닝하면 됨. 그럼 왜 안쓰냐고? 인터넷 상의 모든 TCP사용자들에게 배포하기가 너무 힘들어서다. 아니 그냥 다들 이 기능 추가하라고 하면 안되냐고?
TCP가 워낙에 많이 쓰임 -> device들마다 본인들만의 튜닝된 TCP가 존재 -> 일부 device들은 저 새로운 기능을 본인이 쓰던 TCP에 추가할 여력이 안됨. 저기서 확장하는 TCP보다 옛날 버전이거나, 이상한걸 추가해서 버그를 일으킬 수 있기 때문. 즉 온세상의 모든 제각각인 TCP implementation들이 저 2가지 기능을 지원할 수 있도록 업데이트를 해야 한다는 것이다. 물론 그냥 추가해서 update가 되는 애들도 있겠지만, 아닌 애들도 많을 것이라는게 문제
더 구체적으로 설명하자면, end-user들의 경우에는 큰 변화없이 업데이트 하는게 문제가 되지는 않는다. 문제는 온세상에 존재하는 방화벽, 프록시, 라우터, 서버 캐시, load balancer등의 middle-box들이 문제. 한 예시로 방화벽은 제 기능을 하기 위해 TCP protocol이 특정 조건을 만족한다고 가정을 하는데, 위 2개를 추가하면 이 가정이 깨진다. 그러면 방화벽을 위한 TCP를 다시 짜야한다(...) 이러한 이유로 다 업데이트하려면 최소 몇년, 최대 수십년(...)이 걸릴 것으로 예상했다. 저정도면 그냥 새로 protocol 만들어서 갈아엎는게 더 빠를 판이다.
그래서 진짜로 갈아엎기로 결정한거다.(아하) 그런데 힘들었다! 왜냐하면 앞에 말했듯 구현이 너무 다양했고, 그들의 요구사항을 충족시키면서 더 좋은 녀석을 만들기 힘들었기 때문이다. 그래서 미뤘다!(?)
자 다시 앞의 연표를 찬찬히 읽어보자. TCP의 문제가 제기된게 2000년대 후반이다. 사실 이 당시에 HTTP(HTTP/1.1)도 같이 문제가 제기되었다. (이유는...또 HOL) 그래서 둘 다 바꾸기로 했는데, TCP를 바꾸기엔 앞의 이유로 너무 힘들어보여서 일단 HTTP만 바꿨다. 당시 구글에서 만든 SPDY가 2009년도에 이 목적으로 만들어진 다음 2012년에 HTTP/2가 이를 기반으로 표준화되기로 결정되어 2015년에 나왔고, TCP 대체인 QUIC은 그 사이 구글에서 2012년 완성해 2013년도에 전세계에 알려졌다.
원래 의도는 이 QUIC 위에 HTTP/2가 그대로 동작하는 것이었는데... 그냥 적용하면 너무 비효율적이라는 결론이 나왔다. 대체로 서로 중복되는 기능이 너무 많은게 이유였다고 한다.
즉 원래는 HTTP/2가 QUIC위에 동작하는 형태로 끝났어야 했는데 잘 안되어서 HTTP/2를 좀 바꿨고, 그게 HTTP/3가 된 것이다. 즉 HTTP/3로 바뀌면서 생기는 새로운 이점들은 대체로 QUIC의 기능들을 제대로 활용할 수 있게 되어서 생기게 된 것이라고 보면 됨
QUIC
이 때문에 QUIC를 먼저 제대로 이해할 필요가 있다. 얘는 굳이 HTTP에서만 쓰이는게 아니라 다른 application layer protocol들도 사용이 가능하다. (DNS라든가)
QUIC가 User Datagram Protocol, 즉 UDP 위에 돌아가는 protocol이라는 것은 들어봤을 것이다. 혹시 UDP가 뭔지 모르면 이 링크 참고. 흔히 이렇게 구현된 이유가 성능 때문이라고 하는데 이는 사실이 아니다.
QUIC는 원래 network layer의 IP 바로 위에 돌아가는 protocol일 계획이었다. 그런데 그럴려면 온세상의 IP 동작 방식을 또 수정해야 했고, 이게 (앞이랑 비슷한 이유로) 힘들었는데, 마침 UDP 위에 돌려도 괜찮다는게 발견되었고 UDP는 이미 IP들이 잘 인지하는 protocol이어서 UDP위에 돌아가기로 결정된거다.
또 많은 곳에서 UDP 자체가 connectionless, 즉 handshake process가 없고 packet retransmission을 기다리지 않는 특징 때문에 성능이 좋아서 QUIC도 좋은것이라고 하는데 이것도 사실이 아니다. 왜냐하면 UDP는 안하지만 RFC를 보면 QUIC 자체에서 ACK이랑 retransmission을 활용해 reliable한 통신을 보장하고, 매우 복잡한 handshake 과정을 거치기 때문이다. 심지어 flow control/congestion control도 한다. 참고로 이를 구현한 이유는 TCP의 특징을 그대로 보존하기 위해서다. 그리고 알다시피 이것들이 전부 TCP를 느리게 한 원인이라고 지적되었죠.
그러면 왜 HTTP/3가 HTTP/2보다 더 좋다고... 아니 정확히는 왜 QUIC가 TCP보다 더 좋다고 하는걸까? TCP 배포 후에 얻은 경험들을 살려 더 효율적으로 위의 기능들을 구현했기 때문이다. 크게 4가지의 변환점을 들 수 있다.
QUIC implementation
Integrated TLS
인터넷에 data를 secure하게 보내려면... TLS가 필수다! TLS가 개발된 시절, data를 secure하게 보내는데 왜 번거롭게 별도의 protocol을 만들었냐면
- data를 encrypt하는데 생각보다 computation이 많이 들었음.
- 이러는거 자체가 당시에는 모두에게 필수 사항이 아니었음.
위 두가지 이유 때문에 쓰지 않을 거면 쓰지 말라고 따로 protocol로 만든 것이다. 이미 사용되고 있는 protocol에 내장하면 쓰기 싫어도 쓸 수 있도록 구현해야 하니까.
그러나 시간이 흐르고 data를 encrypt하는게 슬슬 반필수가 되었고, HTTP/2의 경우 TLS를 안 쓰고 통신하는게 가능했지만 대부분의 브라우저들이 TLS를 안쓰면 연결 자체에 빠꾸를 먹였기에 TCP랑 TLS를 같이 써야 했고, 이 때문에 TCP handshake랑 TLS handshake를 두 번 해야 하는 문제점이 생겼다.

그래서 QUIC는 해당 protocol '자체'에서 보안 설정 작업을 본인 connection 구축 때 동시에 하도록 설정이 되었다! 구글에서는 자기들 만의 보안 프로토콜을 사용하도록 만들어졌었으나 나중에 표준화 되었을때는 TLS1.3 자체를 사용하도록 만들어짐.
OSI 7계층에서 배운 계층 분리에 위배되지 않냐고? 어차피 현실에서 위배된게 한두번이 아니어서(...) 상관없다. 그건 교육할때 편하고 일반적으론 적용하기 쉬운 추상 모델이면서 많은 사람들이 알고 있기에 계속 쓰이는 것일 뿐이지 꼭 지켜야 하는 것은 아니다.
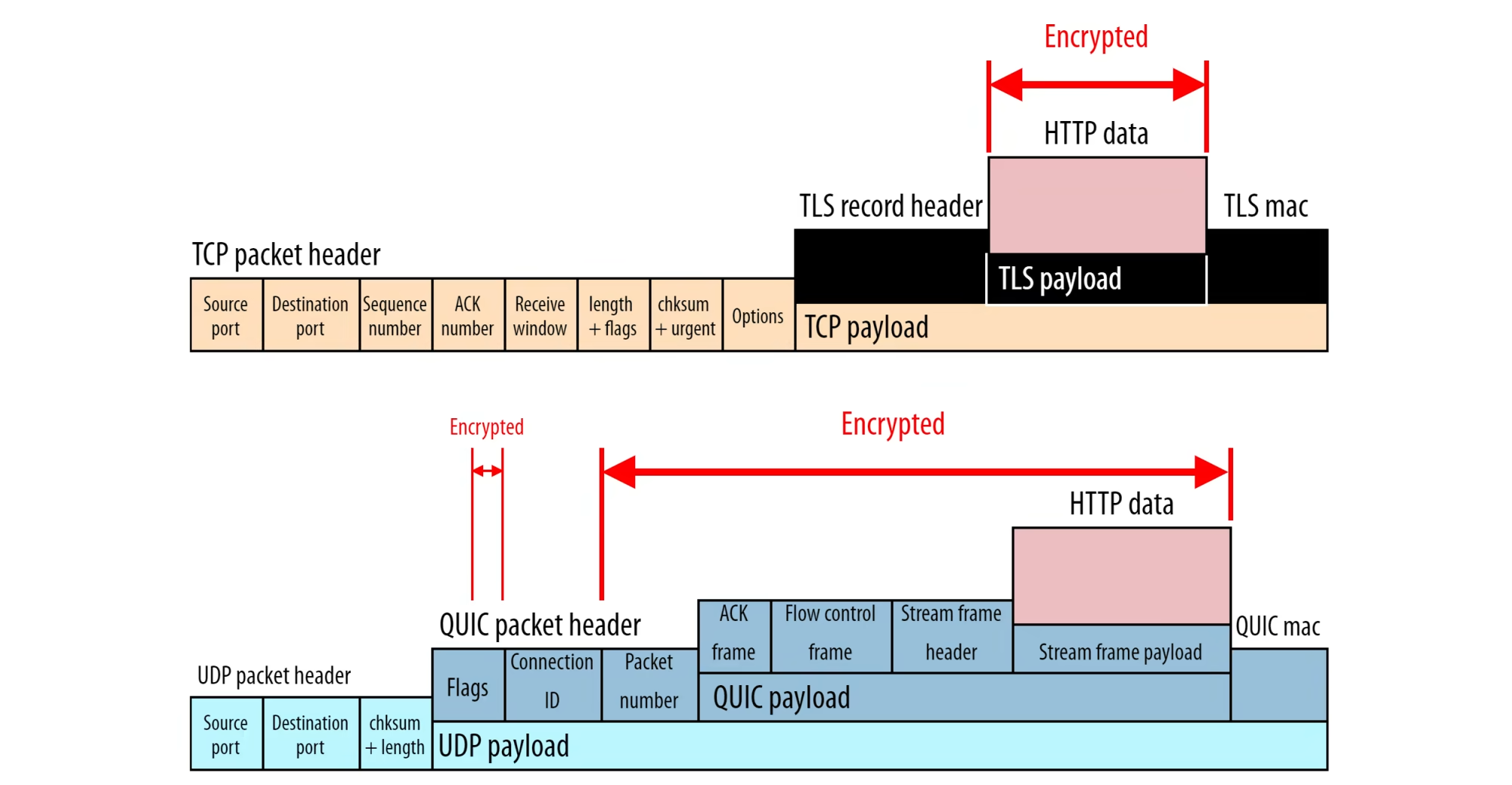
게다가 위의 사진 중 윗 부분이 기존의 TCP + TLS에서의 TCP packet이고, 아래는 QUIC + UDP에서의 UDP packet인데, TCP 측은 HTTP data만 encrypt하는게 가능하지만 QUIC은 HTTP data뿐만 아니라 본인의 payload는 물론, 본인의 header 일부분까지 encrypt하는 것이 가능하다. 즉 transport layer 관련 정보들 및 일부 header 정보까지 전부 encrypt가 된 것이다. UDP header 정보는 encrypt되지 않지만, 여튼 많이 유용한 편.
원리는 매우 단순하다. 원래는 TLS가 별도의 protocol이어서 본인이 encryption을 위한 환경이 구축 완료되면 그걸 본인이 쓰고 TCP는 따로 못썼는데, QUIC은 TLS처럼 encryption 환경을 구축한 다음에 그걸 본인이 쓴다... 암호화를 의무화할거냐 안하냐의 차이가 이런 성능 차이로 유도된다는 걸 알 수 있음.
이 덕분에
- QUIC이 TCP보다 더 secure, 즉 HTTP/3가 HTTP/2보다 더 secure하다고 볼 수 있으며
- QUIC이 handshake 수가 적어서 connection 구축이 더 빠름, 즉 HTTP/3가 HTTP/2보다 connection 구축이 더 빠름
- 이제 앞의 middle-box들이 transport layer payload 인지가 안되어서, QUIC의 내용물을 이해할 필요 없이 동작이 가능해져 QUIC의 구현이 좀 달라져도 middle-box들이 이에 맞춰 변동을 할 필요가 없어짐. layer간의 seperation이 더 잘 되었다고 생각하면 된다.
하지만 단점도 꽤 많다.
- transport layer측의 payload가 통째로 encrypt되는 탓에 특정 traffic이 위험한 data를 포함하는지 안하는지를 판별하기가 더 힘들어서 평균 delay, packet loss 비율을 파악하기가 힘들어서 그냥 QUIC 자체를 지원안하는 곳들이 꽤 생길 수 있다. 언제 이상한게 들어올지 모르니까. 사실 이 때문에 QUIC, 즉 HTTP/3가 전세계적으로 도입되기가 영영 힘들 것이라는 얘기도 있다.
- TCP-TLS 환경과 다르게 한번에 한개의 packet만 encrypt가 가능해서 throughput이 높은 환경에서는 오히려 이전보다 느리다.
- 아무래도 현 QUIC의 표준화를 주도한 IETF가 대기업들 직원이 많이 있는 모임이고 QUIC이 생각보다 복잡하다 보니, IETF를 중심으로 인터넷 환경이 관리되어 IETF가 인터넷 환경을 쥐락펴락 하는 문제가 밸상할 수 있다.
Recognition of Multiple Byte Stream
이건 다음 글에서 더 자세히 설명할 예정이다. 여기선 대략적인 개념만 알아볼 것이다.
아무리 간단한 웹페이지여도 사진, JS file, HTML file, CSS file등이 막 섞여져 있는 형태로 존재하며 이를 서버가 유저에게 전달할 때 한번에 전달하지 않고 나눠서 전달한다는 것은 잘 알것이다. 이때 나눠진 애들 하나하나를 packet이라고 transport layer에선 보통 얘기하고, 하나의 웹페이지를 받을 때 이 packet들이 하나씩 '스트림' 형태로 오고, 이들이 0과 1로 이루어져 있기 때문에 웹페이지를 받을 때 'byte stream'을 통해 받는다고 생각할 수 있다. 이게 여기서 얘기하는 byte stream이다.
HTTP/1.1의 경우 각 웹페이지마다 TCP 연결을 하나 만들었기 때문에 하나의 연결당 하나의 byte stream만 TCP가 신경을 써도 되었으나, connection을 만들 때마다 overhead가 있기 때문에 (handshake, management process 등) 효율적이라고 보긴 힘들었다.
애초에 이 비효율성 때문에 브라우저 차원에서 최대 연결 개수를 제한하고 이 연결들을 재활용하면서 여러 페이지랑 파일들을 받았는데, 이러니까 또 생기는 문제는 파일들이 많아지면 많아질수록 그냥 다운로드 속도가 느려지는 것이다. 그리고 알다시피 이걸 해결하기 위해 HTTP/2에서 multiplexing이 나왔다.
이름이 왜 multiplexing이냐면 여러개의 byte stream들을 하나의 연결에서 섞어가지고 받았기 때문이다. 예를들어 파일이 A, B, C 이렇게 3개를 받는다고 할 때 기존에는 3개의 연결에서 하나씩 담당했다면, 이제는 하나의 연결에서 3개의 다운로드 과정을 담당할 수 있는 것이다. 이 과정에서 A, B, C의 packet들이 뒤섞일 수 있지만 별 문제가 안되었고, 그 덕분에 HTTP/1.1보다 빠르다고 할 수 있었다. 이론적으론.

이론적으론 그런데, 문제는 TCP에서는 여전히 저 3개의 byte stream을 하나의 byte stream으로 본다는 것이다. 3개로 생각하는것은 오직 HTTP측에서만 인지하고 있음. 그러면 TCP가 생각하는 단일 byte stream을 X라고 해보자.
평소에는 별 문제가 없으나, 문제는 TCP측에서 in-order, reliability를 위해 수행하는 retransmission process에서 발생한다. byte stream의 중간 부분 하나가 끊기면 해당 부분의 retransmission을 요청하면서(reliability) 이후에 오는 부분들은 또 위로 전달을 안하는데 (in-order) 뒤에 오는 녀석이 HTTP 입장에서 봤을 때 유실된 부분이랑 관련이 없는 경우더라도, TCP에서는 다 단일 byte stream으로 취급하기 때문에 retransmission을 요청한 애가 제대로 도착할때까지 HTTP측에 전달을 하지 않는다. 이게 TCP에서 (HTTP/2임에도 발생하는) HOL problem이다. HTTP/1.1에서 경험하던 HOL problem이랑은 좀 다르다. 왜냐하면 걔는 HTTP의 구조적 문제까지 결합되어서 생긴 문제였거든. 그런데 이건 HTTP측에서의 문제는 해결되었는데 TCP의 구조적 문제 때문에 발생하는 것이다. 밑의 그림 참고.
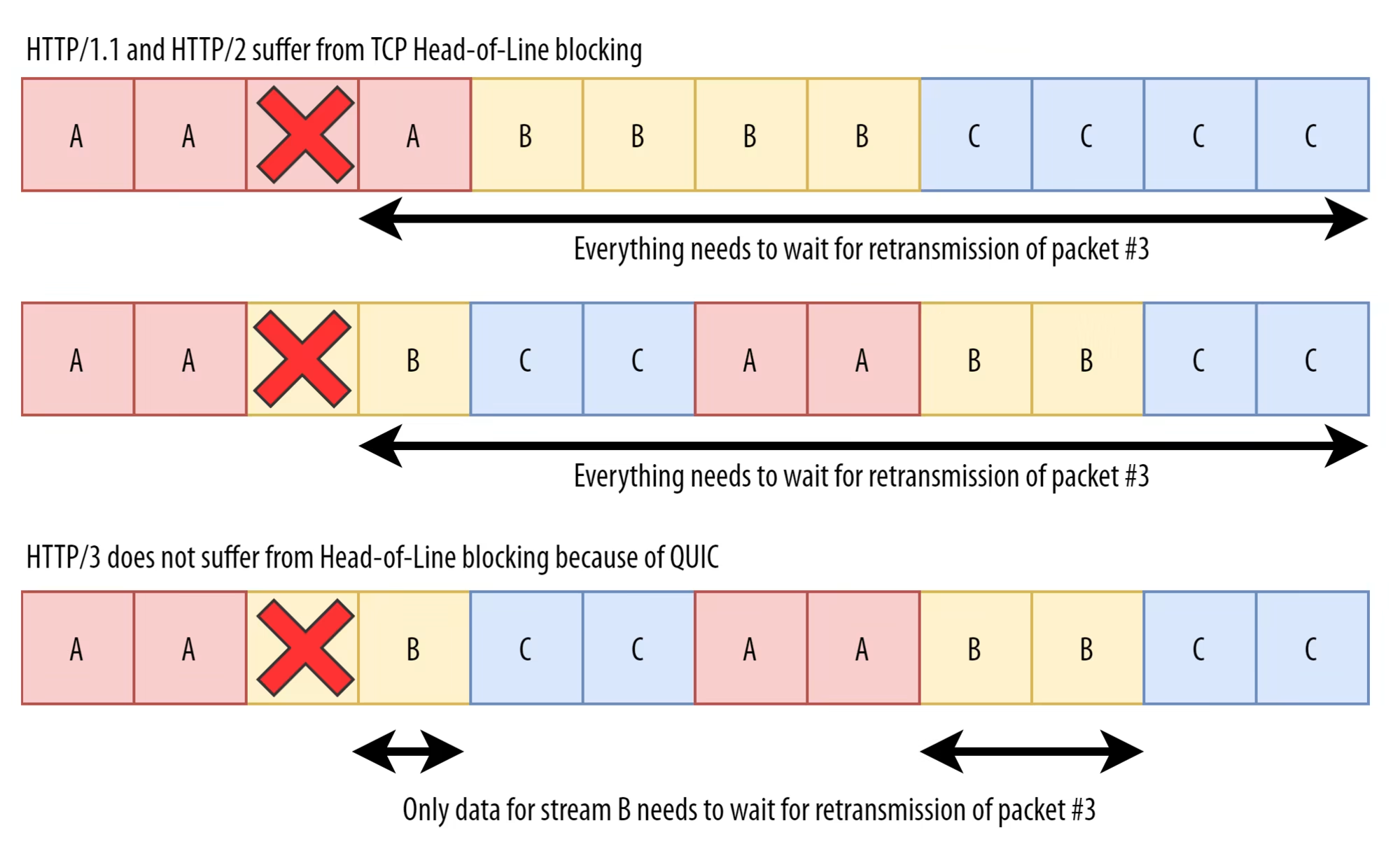
이 때문에 HTTP/2도 이론적 성능이 안 나왔으나, QUIC의 경우에는 하나의 연결에서 여러개의 file을 받을 때 HTTP처럼 여러개의 독립적인 byte stream으로 바라보는 것이 가능하다. 그래서 B가 특정 packet이 유실되었을 경우 이후에 오는 B의 packet들만 잠시 미루고 나머지 packet들은 위로 전달하는게 가능함. (다만 다음 글에서 볼거지만, 현실에서 이 이론적인 효과를 온전히 누리지는 못한다.)
HTTP/3라는 protocol이 새로 등장하게 된 핵심 이유기도 하다. 왜냐하면 HTTP/2를 이 위에 올리면 2 종류의 packet들에 대한 byte stream abstraction이 생기기 때문이다. 이 두개의 서로 다른 추상화를 통일시키는게 너무 번거로워서, 그냥 HTTP/2측에 있었던 기존의 byte stream abstraction을 없애버리고 QUIC의 byte stream abstraction을 활용하도록 바꾼 것이다. 다만 이 여파로 server push, HPACK 활용 header compression, prioritization을 구현하는 방식도 함께 달라져버렸다. 이것도 다음 글에서 알아볼 것이다.
connection migration
packet이 특정 end에서 다른 end로 도달하는데 필요로 하는 정보는 무엇일까. 뭐 복잡하지만, transport layer의 TCP측에서는 IP주소랑 port number을 활용한다. 전자는 어느 기기에서 왔는지를 파악하기 위해, 그리고 후자는 해당 device의 어느 connection에 전달을 해야하는지 파악하기 위해서다. device에서 여러개의 connection이 존재할 수 있으니까.
즉 TCP에서는 연결을 구축한 end user 중 한명의 ip주소나 port number, 둘 중 하나만 바꿔져도 즉시 해당 연결이 무효화된다.
현대에서 이거는 꽤 문제가 된다. 예를들어 집에서 Wi-fi를 활용해 크롬으로 웹서핑 중이었다고 해보자. 하는 도중에 밖에 나가서 와이파이 연결이 끊기고 4G를 사용하게 되었다고 해보자. 그러면 다른 네트워크를 활용하게 되는 것이라 IP주소가 바뀌게 되는데 이러면 기존 연결이 무효화되어서 크롬 밑의 TCP 측에서 새로 연결을 또 만들어야 한다. 게다가 서버에서는 이 바뀐 연결의 기존의 연결에서 사용한 네트워크만 달라진 것인지도 모른다. 아니 심지어 과거 연결이 제대로 종료되지도 않는다. 왜냐하면 서버측에서 응답이 오랬동안 없으면 연결 종료 신호 (FIN)을 보낼텐데 이때 사용되는 도착IP주소가 이미 client가 안 사용하는 IP주소여가지고 영영 도달할 수 없기 때문이다. (...)
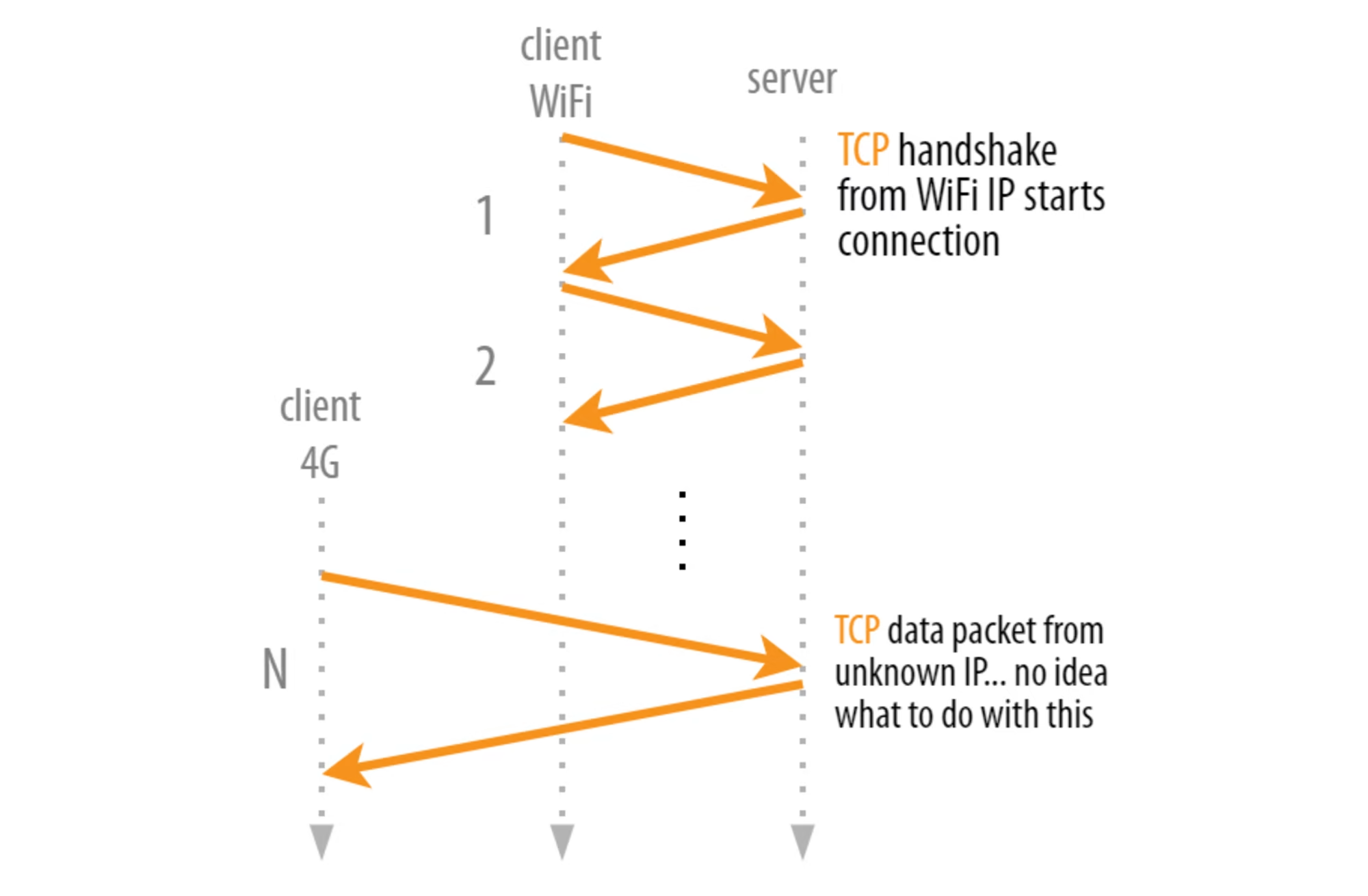
특히 실시간 스트리밍을 보고 있었다든가, zoom을 하고 있었다든가, 엄청 큰 파일을 받고 있었다든가 등의 상황이면 전자 2개는 연결이 완전 끊겨 새로고침을 해야 할 수 있고 후자는 파일을 통째로 다시 받아야할 수도 있다.
그래서 QUIC는 연결을 관리할 때 TCP서 쓰던 4개의 정보에 추가로 connection identifier(CID)를 활용한다. 연결 성립 후 모든 packet마다 고정된 CID를 붙여서 연결 주체중 한명의 앞의 4개 정보 중 하나가 바꿔져도 이 CID가 동일함을 확인하면 동일 연결로 취급할 수 있는 것이지. 이 특징을 connection migration이라고 한다. 다만 이것도 이론적으로는 좋지만 현실에서 완벽히 잘 먹히진 않는다.
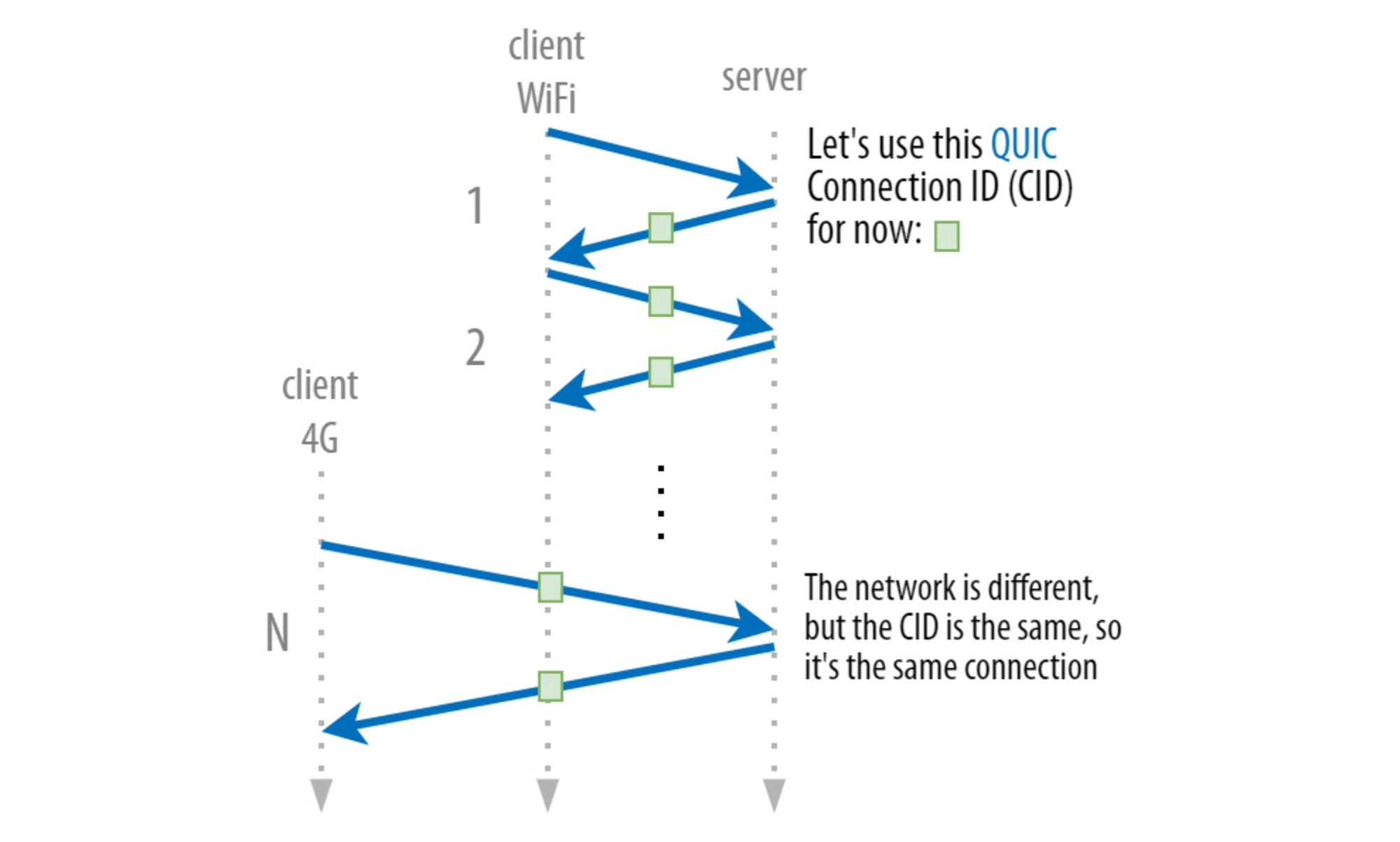
대체로 이 방식이 잘 안먹히는 이유는 다음 글에서 설명할거지만, 일단 지금 당장 언급해야하는 문제점이 있는데 이 CID는 QUIC에서 encrypt되지 않으며, 따라서 연결 내내 동일한 CID를 사용하면 해커가 연결을 사용하는 사람의 실시간 위치를 파악하는게 가능하다.
그래서 네트워크가 바뀔 때마다 CID가 바꿔져야 한다. 잠깐, 그러면 CID까지 다 달라지면 동일 연결인걸 반대쪽이 어떻게 파악하냐고? 사실 QUIC에서는 서로 미리 사용할 CID들의 목록을 정해놓는다. 이것은 encrypt된 채로 서로 약속이 되고, 나중에 네트워크가 달라지는 쪽이 미리 사용하기로 결정된 CID 목록 내의 CID 중 하나를 사용하는 것이지. 그러면 CID가 달라져도 서로 인지가 가능하죠.
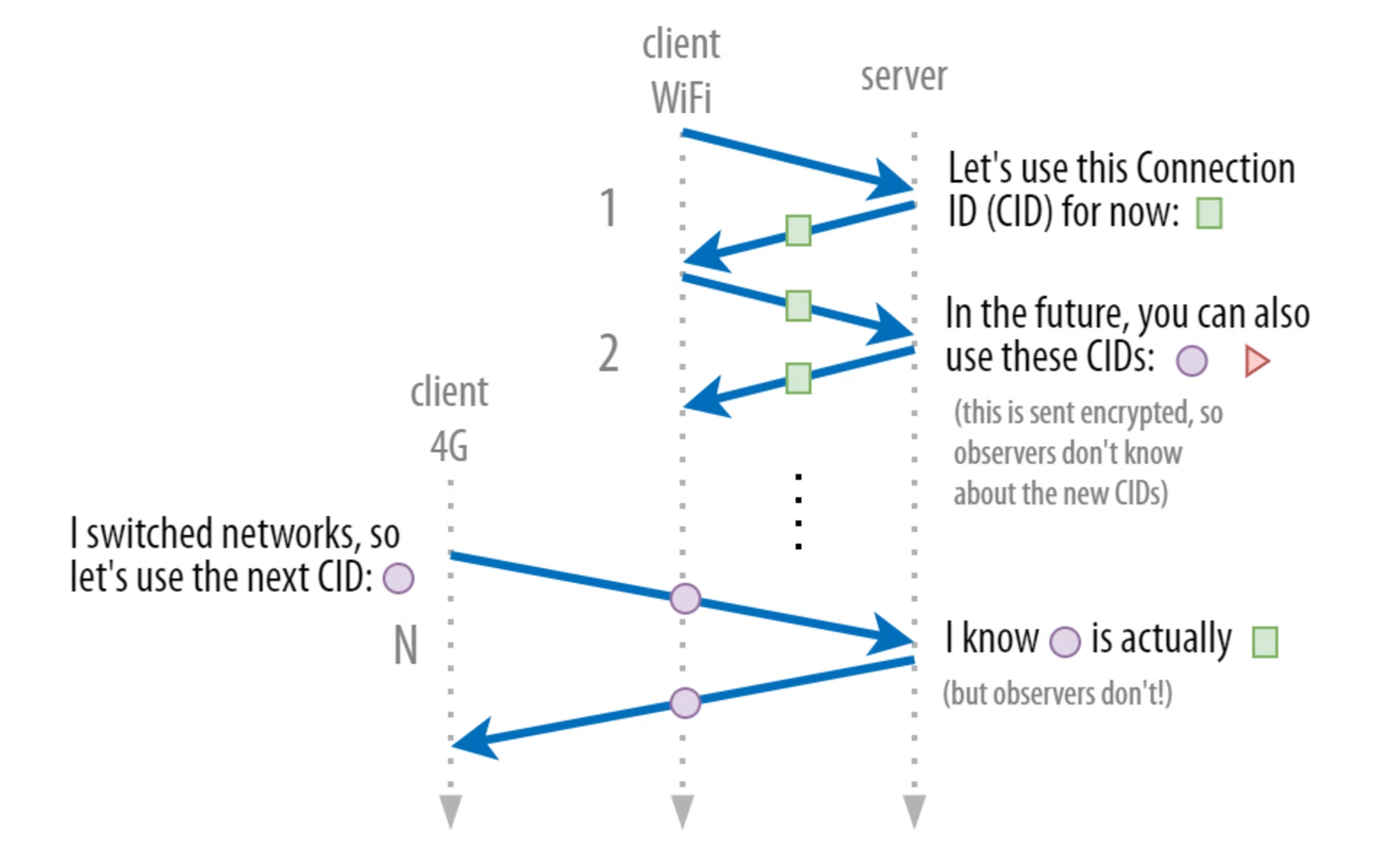
여기에 더 나아가서, 사실 connection의 양측이 사용하는 CID 목록이 서로 다르다. 마치 connection 양측이 (일반적으로) 사용하는 port number이 다른 것과 비슷한데, routing이나 load-balancing을 위해서 이렇게 구현했다고 한다. 즉 실제로는 packet에 2개의 CID가 붙어있고, connection 구축 때 양측에서 서로 사용할 CID 목록이 secure하게 공유되고, 기존에 TCP측에서 사용하던 정보 중 하나가 바꿔지면 바꿔진 녀석이 본인의 CID 목록 내에서 새로운 CID를 골라 붙여서 packet을 보내고, 반대측은 내용이 달라진걸 발견하면 달라진 CID가 보낸 측에서 사용하겠다던 CID 목록에 있는지 파악해 있는걸 확인하면 연결을 유지하는 것이다. 아이고 복잡해 port처럼 생각하면 편하다.
flexible and evolvable
마지막 특징이다. 왜 저런 특징을 가진다고 볼 수 있냐면
- 일단 앞에 말했듯 QUIC 내용물은 전부 encrypt되어서 middle-box측에서 이를 신경쓸 필요가 없기에, QUIC이 좀 달라져도 해당 내용물 관련이면 middle-box에서 대응할 필요가 없다.
- TCP에서 연결의 metadata를 담는데 사용되었던 header 길이를 대폭 축소하고, 대신 'frame'이라는 개념을 도입, 여러 종류의 frame을 정의해서 frame에서 부가적으로 필요한 metadata들을 집어넣을 수 있도록 했다. 이 frame들은 QUIC payload측에 들어간다. TCP에서 header이었던 것들 중 QUIC에서 frame이된 대표적인 녀석은 ACK이며 그 외에도 새로 사용할 CID 등이 있다.
원래 이걸 도입한 이유는 최적화 때문이었는데, 저런 data들은 packet마다 전달되는 data들이 아니어서 굳이 매번 필수적으로 사용되는 header에 넣을 이유가 없었기 때문. 하지만 부가효과로 이 frame을 활용해 추가로 기능을 넣고 싶으면 그냥 새로운 frame을 만들어서, 하위 layer의 변동을 유도하지 않고 추가하는게 가능하기 때문.
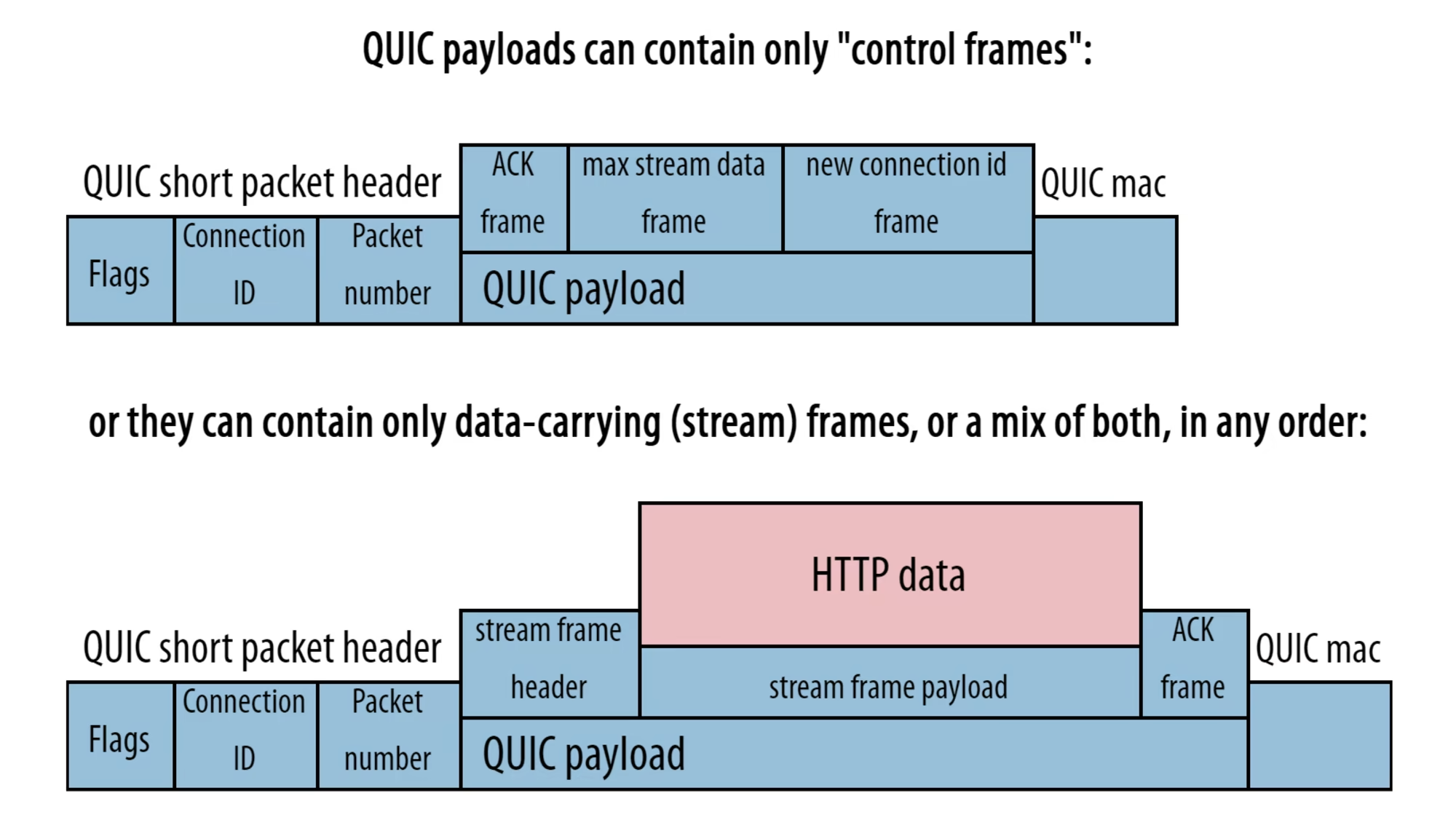
- 사실 QUIC은 순수 TLS를 쓰는게 아니라 튜닝된 TLS를 쓰는데, 거기서 transport parameter을 집어 넣는다. 이걸로 초기 연결 때 무슨 기능이 사용 가능하고 무슨 기능이 사용 불가능한지를 설정하는게 가능하다. 참고로 이것도 encrypt되어 있으니 외부에서 어떻게 설정했는지 파악은 불가능. 이걸 확장하는 것이 가능해서, 유연성을 증진시킨 사례로 볼 수 있다.
- 마지막으로 QUIC의 디자인이랑은 크게 관련 없는 부분인데, TCP가 구현부분이 대체로 kernel 공간인 것과 달리 user 공간에 구현부분이 많이 존재해서 사용자 입장에서 이런저런 실험적인 시도를 하는게 용이하다. 자세한건 다음 글에서 알아볼 것이다.
conclusion
- HTTP/2가 문제가 있었다기보다는, TCP에 개선이 필요해서 QUIC를 구현하다보니 HTTP/3도 새로 정의할 필요가 있었다.
- QUIC는 UDP 위에 존재하는 protocol이나, TCP와 같은 특성을 가진다. 그저 구현을 더 효율적으로 해서 HOL problem, handshake 때 생기는 overhead을 해결했고 더 secure한 communication, 원할한 connection migration을 지원할 뿐이다.
- 이론적인 효율을 현실에서 보긴 힘들다. 이는 다음 글에서 알아볼 것이다.
