YAMNet 모델을 활용한 음성데이터 분류 및 분석 첫번째 포스트에서 threshold(임계값) > 0.3 즉, 0.3이상의 프레임에서 Cough가 감지되었을 때만 감지되었다고 판단하도록 코드를 짰는데 생각보다 기침 감지가 잘 되지않아서 조건을 조금 조정하였다.
threshold > 0.1 로 수정하여 같은 코드를 한 번 더 돌려보니
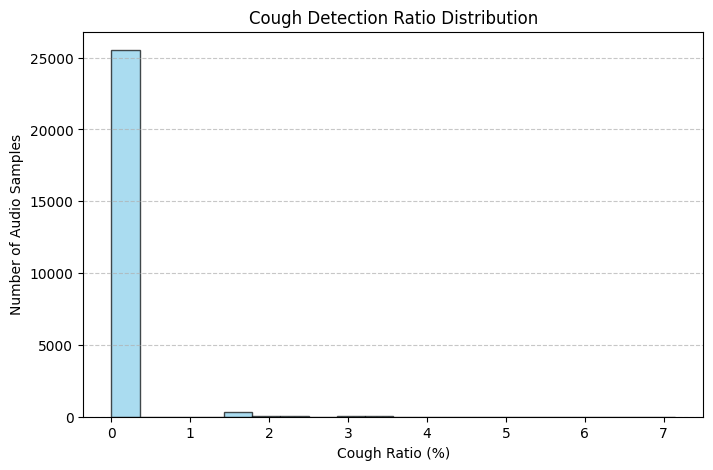
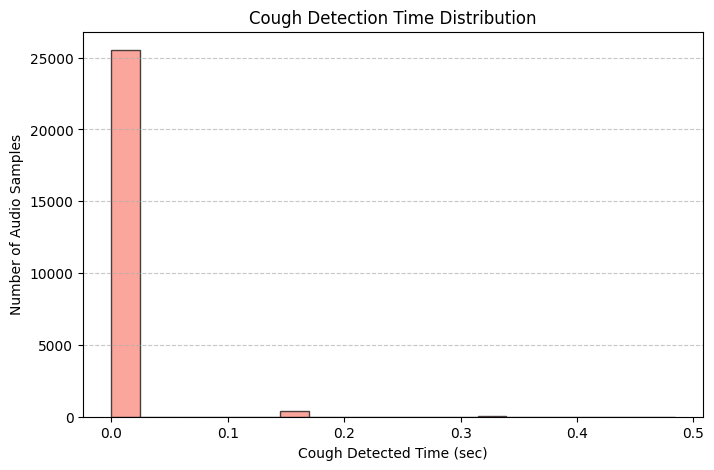
다음과 같이, 조금 더 많은 오디오 데이터에서 기침이 잡혔다.
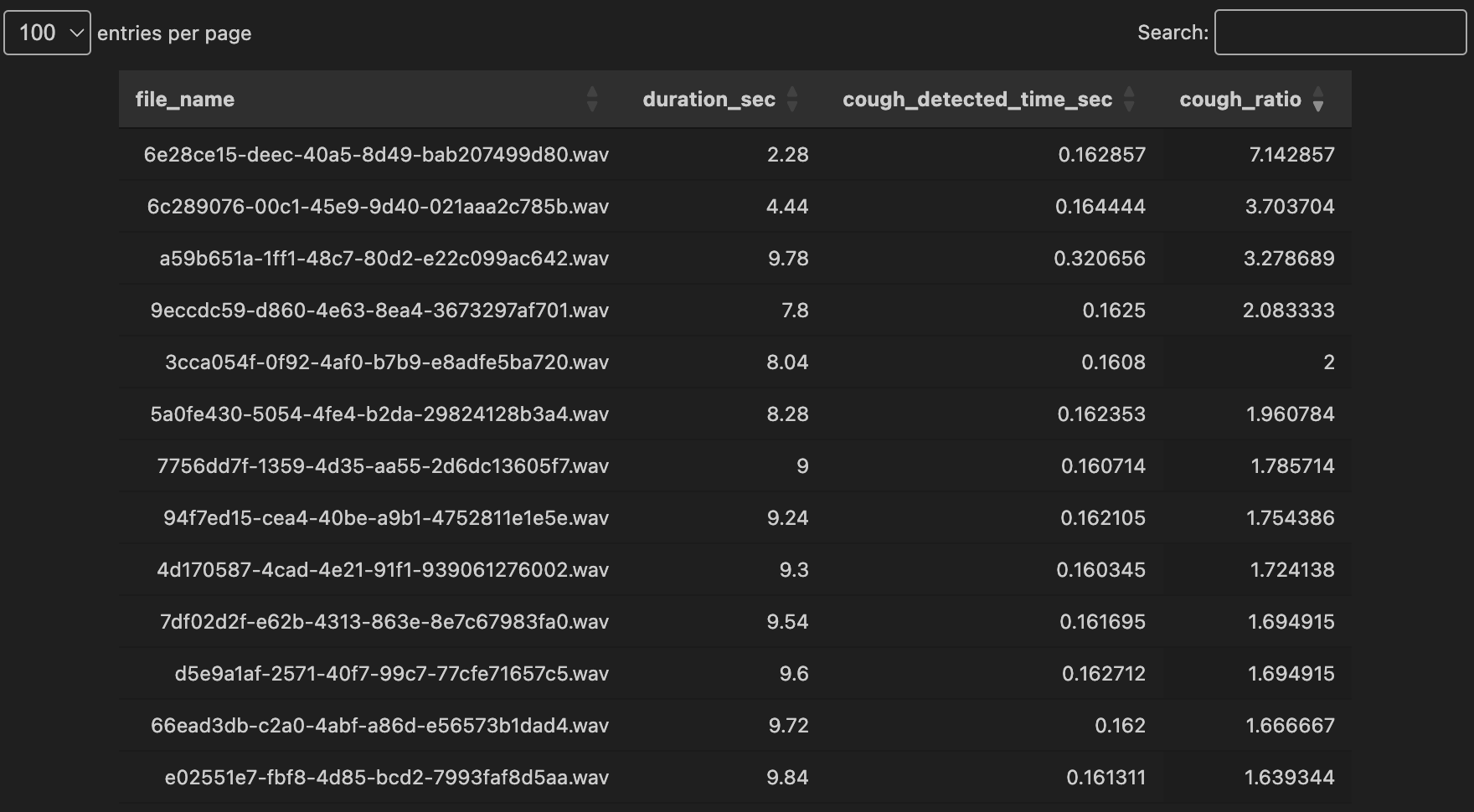
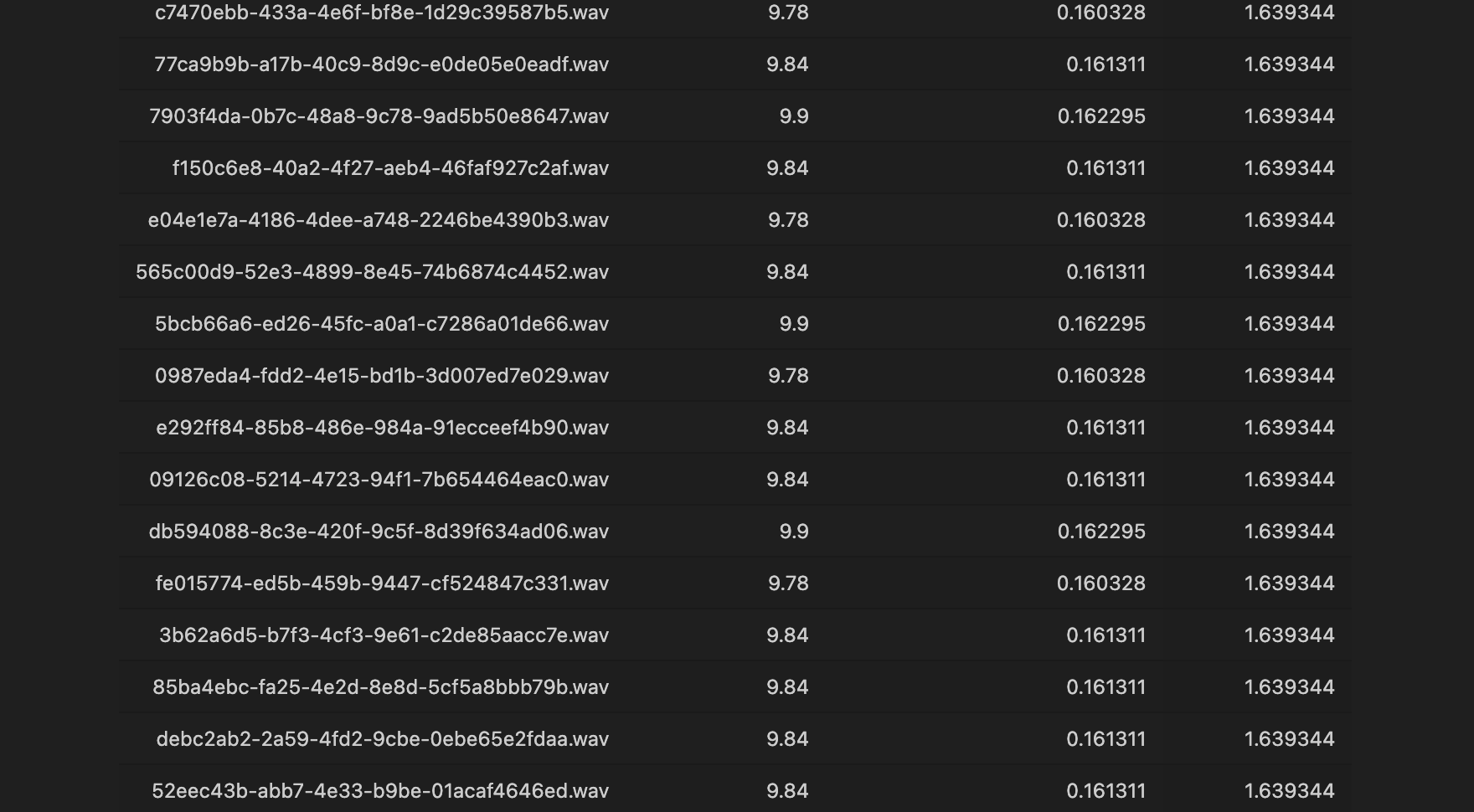
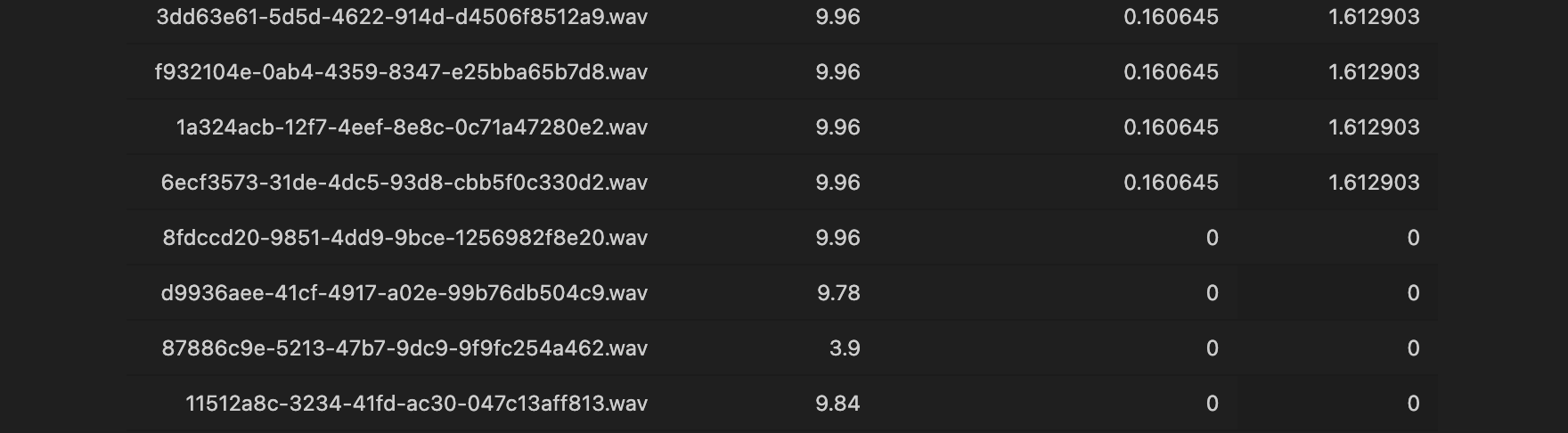
임계값을 0.1까지 낮추니 음성의 기침이 음성의 7퍼센트까지 차지하는 것을 확인할 수 있었다.
그래도 여전히 비율만을 가지고 기침인지 아닌지 파악하기에는 턱없이 부족해보인다.
이 시점이 되니, YAMNet이 기침 오디오 데이터 속 기침을 Cough 클래스라고 제대로 잡을 수만 있다면, 모델을 만들 때 기침을 분류하는 로직을 추가하는 것이 쉬울텐데 왜 Cough 클래스를 잡지 못하는걸까에 대한 궁금증이 생겼다.
이에 네 가지 정도의 가설을 정리해보았다.
Q. YAMNet이 기침 데이터셋을 제대로 감지하지 못하는 원인은 뭘까??
1️⃣ YAMNet의 학습 데이터와 입력 데이터의 차이
YAMNet은 Google의 AudioSet 데이터셋을 기반으로 학습되었고, AudioSet의 기침 데이터는 특정한 환경 (ex. 마이크 품질, 배경 소음이 거의 없는 환경)에서 수집되었을 가능성이 높음.
반면, 네 데이터셋은 환경이 다를 수 있어서 YAMNet이 일반적인 기침과 다르게 인식할 수 있음.2️⃣ 기침이 포함된 오디오지만, 기침 소리의 비율이 적음
입력한 데이터는 기침이 포함된 오디오이지만, 오디오 전체에서 기침이 차지하는 비율이 작을 수도 있음.
예를 들어, 10초짜리 오디오에 기침이 1초만 포함된다면, 나머지 9초 동안의 배경 소음이나 말소리가 더 강하게 작용할 가능성이 큼. YAMNet은 각 0.96초 단위로 분석하는데, 기침이 섞여 있는 구간이 적다면 다른 소리 (ex. 사람 목소리, 환경 소음)가 더 크게 반영될 가능성이 높음.3️⃣ YAMNet의 주요 사운드 기반 분류 방식
YAMNet은 각 프레임(0.96초 단위)마다 "가장 두드러지는 소리"를 기반으로 클래스 예측을 수행함.
즉, 기침이 아주 짧게 발생하고, 다른 소리가 더 크다면 기침이 아닌 다른 클래스로 분류될 수 있음.
기침 소리가 지속적으로 나는 데이터라면 감지될 확률이 높지만, 중간중간 기침이 포함된 데이터는 감지율이 낮아질 수 있음.4️⃣ 기침 감지 기준이 너무 보수적 (Threshold 문제)
현재 기침을 감지하는 임계값(Threshold)을 0.3에서 0.1로 낮췄지만, 여전히 너무 엄격할 가능성이 있어.
일정 확률 이상 감지된 프레임이 한 개라도 있으면 Cough로 판단하는 방식으로 바꿔볼 필요가 있음.✔ 개선 방법:
기침이 감지된 모든 프레임을 확인하고, 최대 확률이 0.0~0.3 사이인 경우도 포함하여 분석.
np.max(cough_probabilities)를 확인해서 "최소한 한 번이라도 0.1 이상 감지된 파일 수"를 세어볼 필요가 있음.💡 해결 방법
기침이 감지된 데이터의 최대 확률 확인
(np.max(cough_probabilities))
만약 기침 확률이 한 번이라도 0.0 이상이면 기침이 포함된 것으로 간주하는 방식으로 변경.
- 오디오에서 기침이 포함된 구간의 시작점과 끝점을 시각화
- 오디오의 특정 시간 구간에서 기침이 감지된 부분을 표시해서 어떤 패턴이 있는지 확인.
일단은 시도해봤으니 만족 :)

아녕
