이번 포스트에서는 할 일 목록 중 1단계~2단계를 집중적으로 이야기 해 볼 예정이다.

할 일 목록이 뭐냐면 ....
할 일 목록
1️⃣ YAMNet 모델을 활용한 음성 데이터 분류 분석
- YAMNet 모델을 그대로 사용하여 데이터 분석
- YAMNet을 활용하여.wav파일들을 처리하고 각 클래스 (ex. 기침, 박수, 말소리 등)로 분류되는지 확인.
- 분류된 결과를 저장하여, 기침 데이터가 원래의 ‘Cough’ 클래스에 얼마나 잘 들어맞는지 평가.- 기침 데이터가 제대로 분류되는지 1차 분석
- 예측된 클래스와 실제 기침 데이터가 얼마나 일치하는지 평가.
-.wav파일별 분류 결과를 확인하고, 정확도(precision, recall 등)를 계산.
- 오탐지(FP,FN)가 발생하는 경우 해당 샘플을 분석.2️⃣ 시간 길이에 따른 분류 영향 분석
- 음성 길이가 모델 분류에 미치는 영향 확인
- 짧은 기침 (0.5초 미만), 중간 길이 기침 (0.5~1.5초), 긴 기침 (1.5초 이상)으로 데이터를 나누어YAMNet이 어떻게 반응하는지 분석.
- 시간이 길어질수록 특정 다른 클래스로 인식되는지 확인.- 분석 방법
-.wav파일을 길이별로 나누고, 모델이 내놓는 클래스 확률을 비교.
- 오차가 증가하는 특정 길이대 구간을 찾고 시각화.3️⃣ 임베딩 벡터 분석 및 차원 시각화
YAMNet임베딩 추출 및 패턴 분석
- YAMNet은 최종적으로 1024차원의 임베딩 벡터를 출력함. 이를.npy파일로 저장하거나 데이터프레임으로 변환.
-Principal Component Analysis(PCA),t-SNE,UMAP등을 활용해 저차원(2D/3D) 시각화 수행.
- 기침 데이터셋이 특정한 클러스터를 형성하는지 분석.- 임베딩 벡터 기반 패턴 분석
- 기침 데이터가 특정한 벡터 분포를 보이는지, 다른 소리(말소리, 음악, 박수 등)와 구별되는 패턴이 있는지 확인.
- 특정 패턴을 보인다면, 이 패턴을 이용해 추가적인 기침 검출 방법을 적용할 수 있는지 검토.4️⃣ 최종 분류 방법 코드화
- 최적의 분류 방법 정리
-YAMNet원본 모델로 충분한 분류가 가능한지 판단.
- 불충분하다면 추가적인 방법(ex.SVM,k-NN,딥러닝등)을 고려.
- 시간 길이 + 임베딩 벡터 패턴을 활용해 기침을 더 정확하게 분류하는 방안을 코드화.
두둥ㅋ.......ㅋ
# Load the model.
model = hub.load('https://tfhub.dev/google/yamnet/1')
wav_file_name = './archive/output.wav'
sample_rate, wav_data = wavfile.read(wav_file_name, 'rb')
sample_rate, wav_data = ensure_sample_rate(sample_rate, wav_data)
waveform = wav_data / tf.int16.max
# Run the model, check the output.
scores, embeddings, spectrogram = model(waveform)
scores_np = scores.numpy()
spectrogram_np = spectrogram.numpy()
infered_class = class_names[scores_np.mean(axis=0).argmax()]
print(f'The main sound is: {infered_class}')현재 코드는 TensorFlow Hub의 YAMNet 모델을 사용해 .wav 파일을 로드하고 소리를 분석하는 구조로 되어 있다.
현재 코드에서 1단계(분류 분석)와 2단계(시간 길이별 영향 분석)를 동시에 진행할 수 있도록 코드를 업데이트 해보았다.
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import wavfile
import os
# YAMNet 모델 로드
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet = hub.load(yamnet_model_handle)
# 클래스 맵 로드
class_map_path = tf.keras.utils.get_file(
'yamnet_class_map.csv',
'https://raw.githubusercontent.com/tensorflow/models/master/research/audioset/yamnet/yamnet_class_map.csv'
)
class_names = list(pd.read_csv(class_map_path)['display_name'])
# 분석할 WAV 파일 폴더
wav_folder_path = "./archive_wav" # 실제 데이터 경로로 변경
# 결과 저장 리스트
results = []
# WAV 파일 처리 및 분석
for file_name in os.listdir(wav_folder_path):
if file_name.endswith(".wav"):
file_path = os.path.join(wav_folder_path, file_name)
# 오디오 로드
sample_rate, wav_data = wavfile.read(file_path)
duration = len(wav_data) / sample_rate # 초 단위 길이 계산
# YAMNet 예측 수행
waveform = wav_data / np.iinfo(np.int16).max # 정규화
scores, embeddings, spectrogram = yamnet(waveform)
# 예측 결과 분석
mean_scores = np.mean(scores.numpy(), axis=0)
top_class = np.argmax(mean_scores)
top_score = mean_scores[top_class]
top_class_name = class_names[top_class]
# 결과 저장
results.append({
"file_name": file_name,
"duration_sec": duration,
"predicted_class": top_class_name,
"confidence": top_score
})
# 데이터프레임 변환
df_results = pd.DataFrame(results)
# 기침 분류 정확도 분석
coughing_results = df_results[df_results["predicted_class"] == "Coughing"]
coughing_ratio = len(coughing_results) / len(df_results) * 100
# 시간 길이별 분포 분석
df_results["duration_category"] = pd.cut(
df_results["duration_sec"],
bins=[0, 0.5, 1.5, np.inf],
labels=["short", "medium", "long"]
)
# 시간 길이별 기침 분류 비율
coughing_ratio_by_length = df_results.groupby("duration_category")["predicted_class"].apply(lambda x: (x == "Coughing").mean() * 100)
# 결과 시각화
import ace_tools as tools
tools.display_dataframe_to_user(name="YAMNet Classification Results", dataframe=df_results)
plt.figure(figsize=(8, 5))
coughing_ratio_by_length.plot(kind="bar", color="skyblue", edgecolor="black")
plt.title("Coughing Classification Ratio by Duration")
plt.xlabel("Duration Category")
plt.ylabel("Coughing Classification Ratio (%)")
plt.xticks(rotation=0)
plt.grid(axis="y", linestyle="--", alpha=0.7)
plt.show()만약 준비한 .wav파일이 YAMNet에서 요구하는 모노 타입이 아니라 스테레오 타입(2채널)일 경우, 두 채널을 평균내서 단일 채널(모노 타입)으로 변경해줘야할 필요가 있다.
번외로, 해당 코드 돌릴 때 ace_tools 모듈을 import 하기 위해 pip install ace_tools를 실행하여 ace-tools 0.0을 successfully installed하였는데, 제대로 불러와지지 않아 서치해보았다..;;
알고보니 ace-tools 0.0은 empty box라고 ...
그래서 아래와 같이 import 구문을 수정 -> 코드 출처
import ace_tools_open as tools이렇게 하니까 제대로 불러와지더라!
코드를 실행해서 얻은 결과는 표와 그래프로 확인할 수 있다.
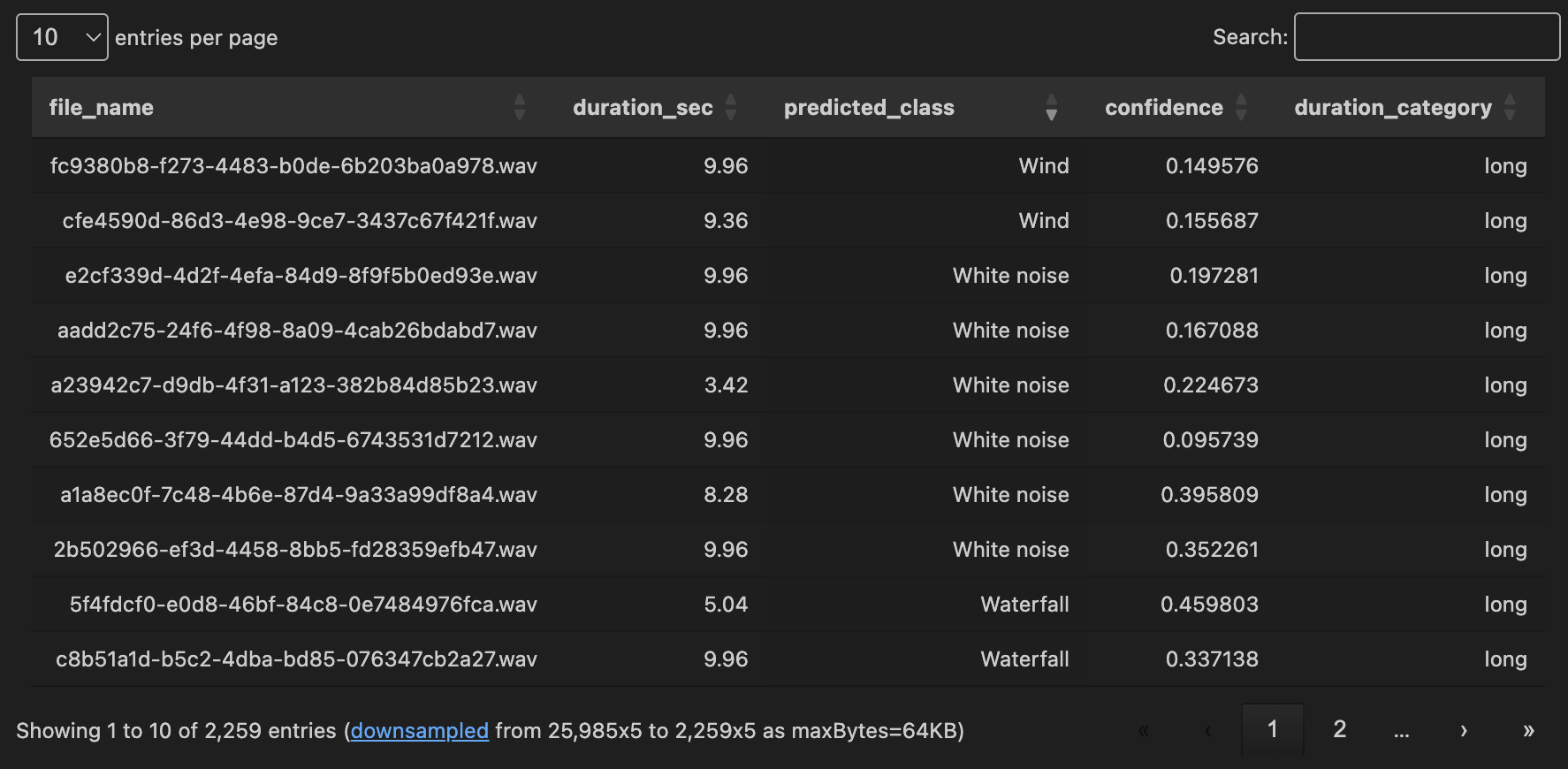
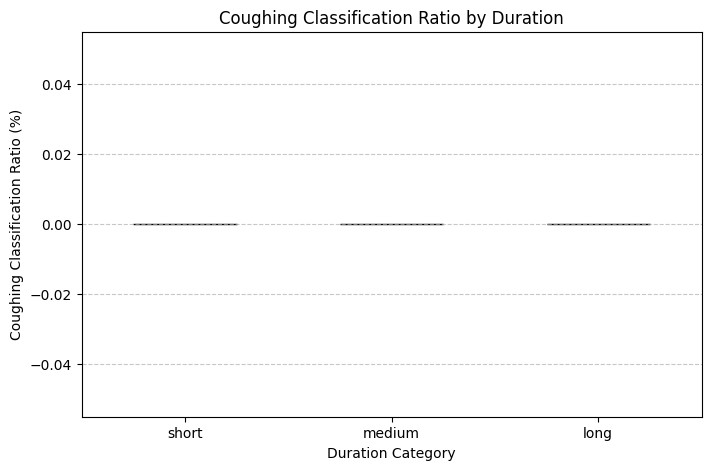
여기서 생긴 문제 ................
약 2,259개의 데이터 중 Cough 클래스로 분류된 음성이 단 하나도 없다.
9초짜리 오디오에 기침만 9초로 가득 차있을 리가 없는데, 기대한 내가 바보인걸까?
하하.
괜찮다 ! 방식을 바꿔보자, 각 오디오를 입력했을 때 Main sound 로 출력된 클래스들을 기준으로 오디오 시간 길이별 기침 분류 비율을 분석하지 말고 아예 전체 오디오의 프레임별(=시간별) 예측 결과를 확인해서 Cough 클래스가 얼만큼의 비율을 차지하는지를 분석해보자.
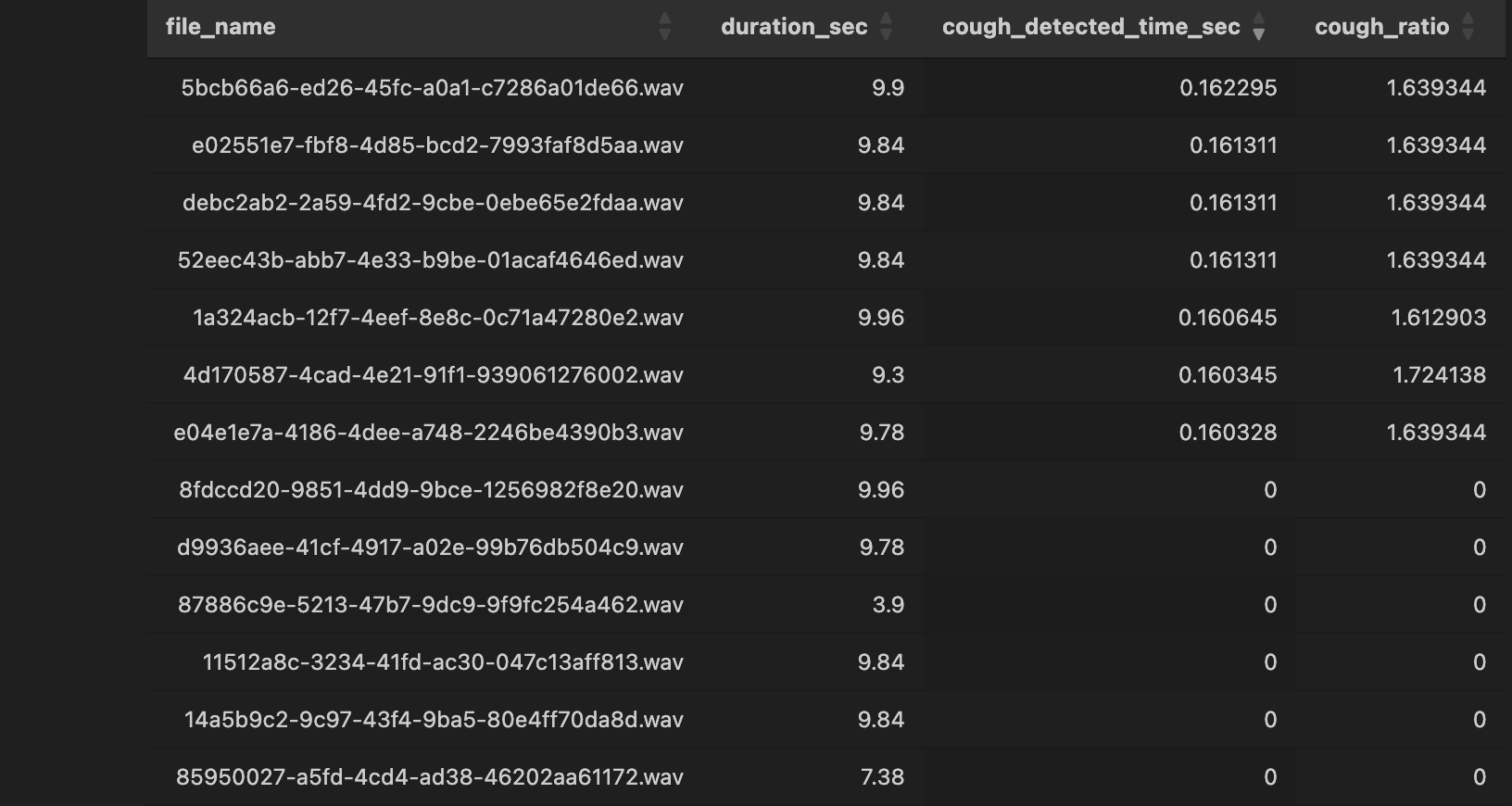
코드 자체를 크게 변화시키진 않았지만, Cough 클래스가 잡힌 오디오를 분류할 수는 있었다. 확인해보니 거의 0.16xx초 동안 지속했을 때 Cough 클래스가 잡힌 것을 확인했다. 기침 자체가 짧은 시간동안 유지되는 소리라 생각보다 더 짧은 시간내에 시작하고 종료하나보다... 싶었다.
결과적으로, 한 7가지 오디오에서 Cough가 잡혔다.
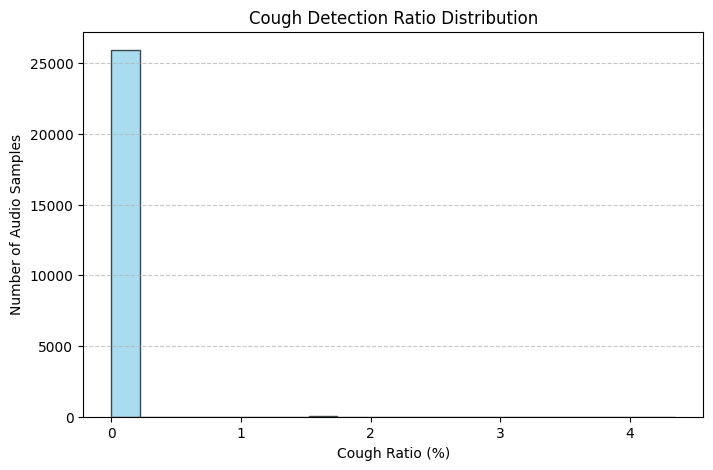
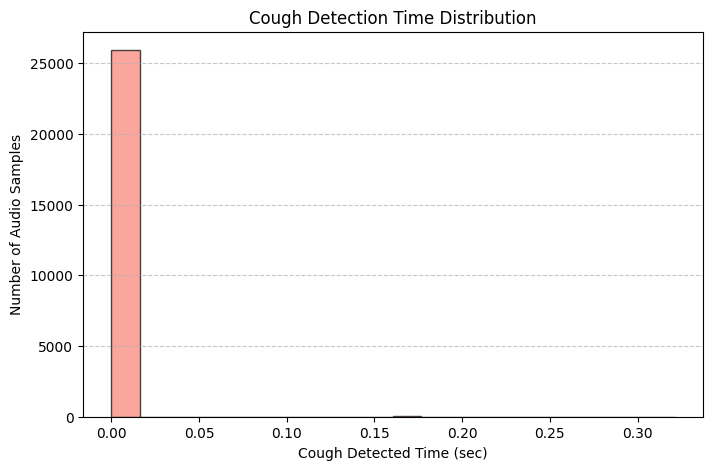
흠.. 생각보다 기침 클래스가 잘 잡히지도 않고, 기침 클래스가 잡히느냐 안잡히느냐만으로 오디오를 분류할 수 없을 것 같다.
😭 이 방법에 추가적으로 조정 볼 수 있는 것들
- Cough 감지 임계값 조정
- 현재 0.3 이상의 확률만 카운트하는데, 이를 0.1~0.2로 낮춰 분석
- 여러 임계값(Threshold)을 테스트하여 최적값을 찾기
- 기침이 검출된 정확한 시간 구간 출력
- 기침이 감지된 타임스탬프를 로그로 확인
- 오디오 데이터를 사전 처리 (잡음 제거, 증폭 등)
- 배경 소음이 크다면 필터링
- 기침 소리가 작다면 음량 증폭
이렇게 마무리하고 이제 할 일 목록의 "3단계" 임베딩 벡터 분석을 통해 오디오 패턴 확인해보기로 넘어가보자..
유의미한 결과를 마주할 수 있도록 기대하며 .....
다음 포스트에서 만납시다.

