
Hive란
하이브는 하둡 에코시스템 중에서 데이터를 모델링하고 프로세싱하는 경우 가장 많이 사용하는 데이터 웨어하우징용 솔루션입니다.
RDB의 데이터베이스, 테이블과 같은 형태로 HDFS에 저장된 데이터의 구조를 정의하는 방법을 제공하며, 이 데이터를 대상으로 SQL과 유사한 HiveQL 쿼리를 이용하여 데이터를 조회하는 방법을 제공합니다.
가장 큰 특징으로는 메타스토어라는 것이 존재하는데, 하이브는 기존의 RDB와는 다르게 미리 스키마를 정의하고 그 틀에 맞게 데이터를 입력하는 것이 아닌, 데이터를 저장하고 거기에 스키마를 입히는(메타스토어에 입력하는) 것이 가장 큰 특징입니다.
Hive 구성요소
UI
사용자가 쿼리 및 기타 작업을 시스템에 제출하는 사용자 인터페이스
CLI, Beeline, JDBC 등
Driver
쿼리를 입력받고 작업을 처리
사용자 세션을 구현하고, JDBC/ODBC 인터페이스 API 제공
Compiler
메타 스토어를 참고하여 쿼리 구문을 분석하고 실행계획을 생성
Metastore
디비, 테이블, 파티션의 정보를 저장
Execution Engine
컴파일러에 의해 생성된 실행 계획을 실행
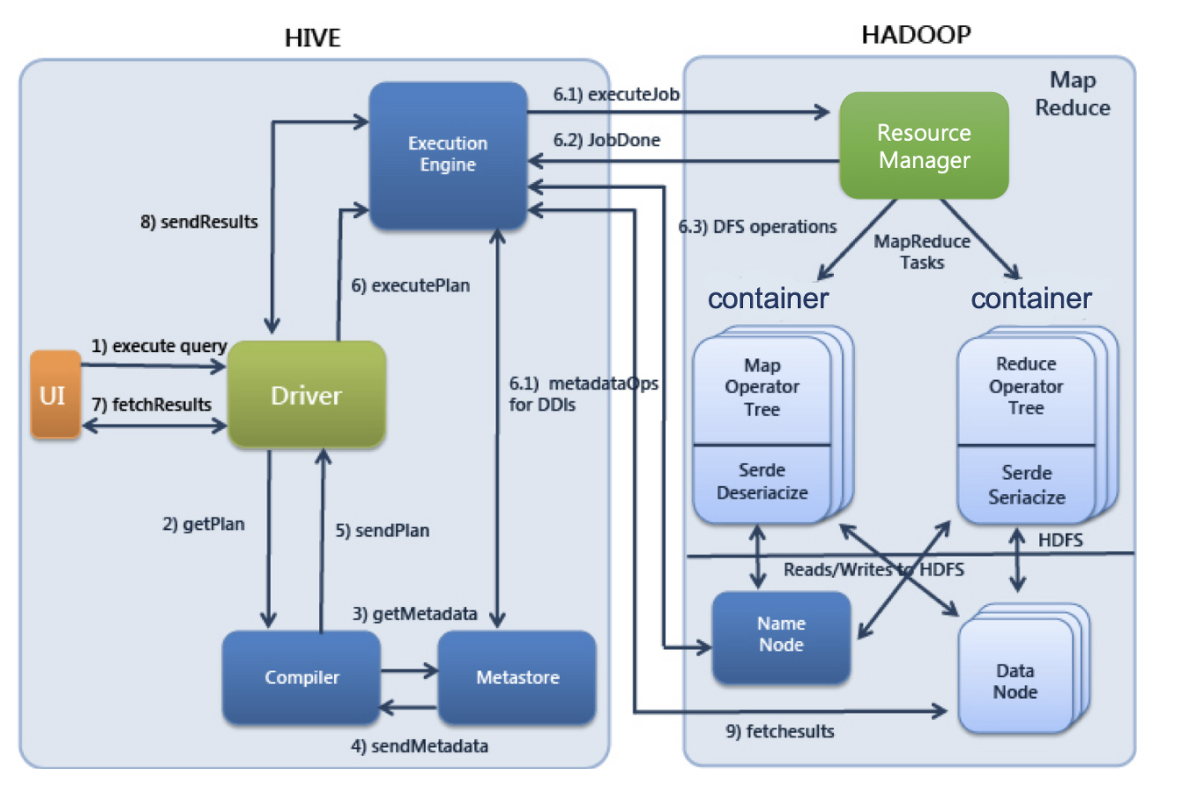
하이브 실행 순서
사용자가 제출한 SQL문을 드라이버가 컴파일러에 요청하여 메타스토어의 정보를 이용해 처리에 적합한 형태로 컴파일
-> 컴파일된 SQL을 실행엔진으로 실행
-> 리소스 매니저가 클러스터의 자원을 적절히 활용하여 실행
-> 실행 중 사용하는 원천데이터는 HDFS등의 저장장치를 이용
-> 실행결과를 사용자에게 반환
3. 등장 배경
하이브는 SQL을 하둡에서 사용하기 위한 프로젝트로 시작됐습니다.
하둡의 MR을 java로 표현하기보다는 익숙한 SQL로써 데이터를 핸들링하는 것이 편하기에 나오게 된 개념입니다.
4. 버전별 Hive 특징
1) Hive 1.0
SQL을 이용한 맵리듀스 처리
파일 데이터의 논리적 표현
빅데이터의 배치 처리를 목표
MR engine을 사용(default engine이 MR)
2) Hive 2.0
LLAP(Live Long and Process) 구조 추가
Spark 지원 강화
CBO 강화
HPLSQL 추가
Tez Engine이 추가(default engine이 Tez로 변경)
LLAP란
- 작업을 실행한 데몬을 계속 유지하여, 핫 데이터를 캐싱하여 할 수 있어 빠른 속도로 데이터를 처리할 수 있습니다.
- LLAP는 작업을 도와주는 보조도구 입니다. 실제 작업을 처리하는 MR, TEZ 같은 작업 엔진이 아닙니다.
- 또한 HDFS같이 데이터를 영구히 저장하지 않습니다. 사용자가 작업 모드를 선택할 수 있으며, TEZ엔진에서만 사용할 수 있습니다.
HPLSQL란
오라클의 PL/SQL과 비슷한 Procedural SQL을 지원합니다. 재사용 가능한 스크립트 작성을 목표로 개발 되었습니다. 아래와 같이 FOR를 이용한 루프문이나 커서등을 이용할 수 있습니다.
TEZ engine이란?
- 테즈(TEZ)는 YARN 기반의 비동기 사이클 그래프 프레임워크입니다.
- 하이브에서 맵리듀스 대신 실행엔진으로 사용할 수 있습니다.
- 맵리듀스는 맵단계에서 데이터를 읽어서 처리하고, 리듀스 단계에서 처리 결과를 저장합니다.
- 하나의 작업이 여러 단계의 맵, 리듀스를 거치게 되면 중간 작업 결과를 HDFS에 쓰고, 다시 맵단계에서 파일을 읽어서 처리하게 됩니다.
- 작업 중간 임시 데이터도 디스크에 쓰게 되어 IO 작업으로 인한 오버헤드가 많았습니다.
테즈는 맵단계 처리 결과를 메모리에 저장하고, 이를 리듀스 단계로 바로 전달합니다. 리듀스 작업의 결과를 맵단계를 거치지 않고 리듀스 단계로 전달하여 IO 오버헤드를 줄여서 속도를 높일수 있습니다.
MR에 비해 30% 정도 향상된 성능을 보입니다.
3) Hive 3.0
- 맵리듀스 엔진, 하이브 CLI를 제거하고 TEZ엔진과 비라인을 이용하여 작업을 처리하도록 수정
- 롤을 이용한 작업 상태 관리(workload management)
- 트랜잭션 처리 강화
- 구체화 뷰(Materialized View) 추가
- 쿼리 결과를 캐슁하여 더 빠른속도로 작업 가능
- 테이블 정보 관리 데이터베이스 추가
Hive metastore(메타스토어)
하이브는 테이블과 파티션과 관련된 메타정보를 모두 메타스토어에 저장합니다.
하이브는 기존의 RDBMS와 달리 데이터를 insert후 스키마를 입히게 되는데, 그때 스키마 정보를 메타스토어에서 참조하여 가져옵니다.
Hive 메타스토어의 유형
하이브의 메타스토어 유형에는 임베디드 메타스토어(Embedded metastore), 로컬 메타스토어(Local metastore), 원격 메타스토어(Remote metastore) 세가지 유형이 있습니다.
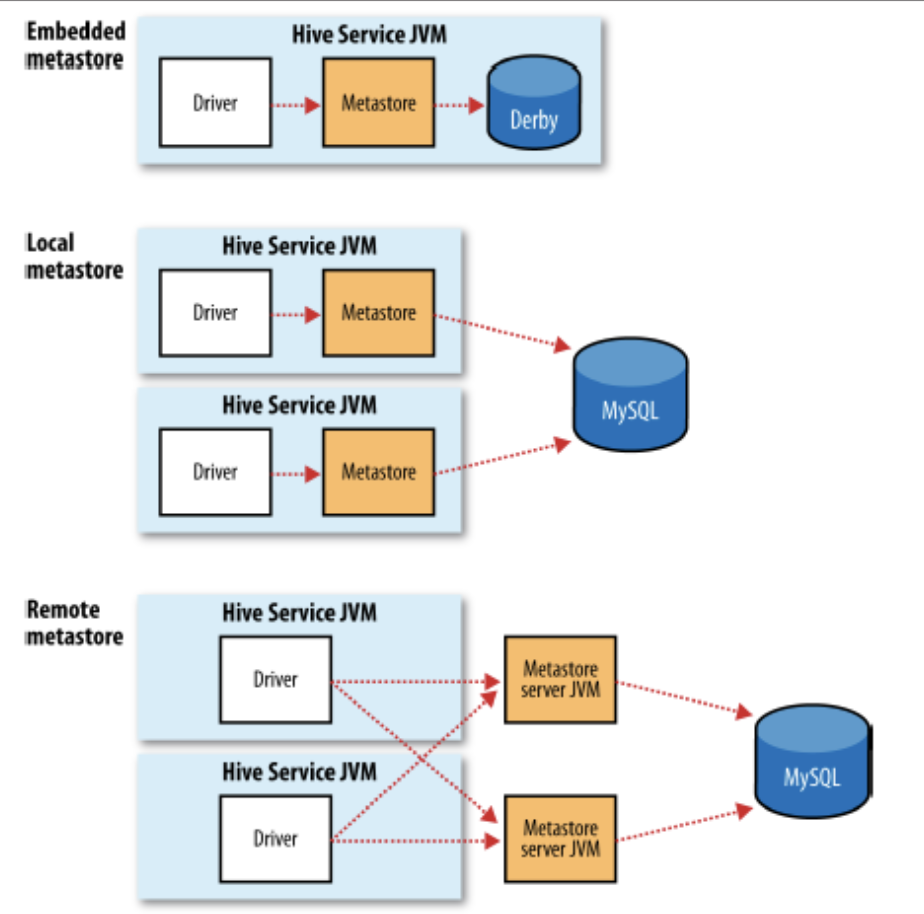
임베디드 메타스토어(Embedded metastore)
하이브를 설치하면 기본적으로 임베디드 메타스토어를 사용합니다.
이 경우 메타스토어가 로컬 장비에 파일로 생성되므로 한번에 하나의 프로세스만 메타스토어에 접근할 수 있습니다. 따라서 실제 환경에서 사용해서는 안됩니다.
보통 DerbyDB가 임베디드 메타스토어의 default DB로 설정됩니다.
로컬 메타스토어(Local metastore)
로컬 메타스토어의 경우 메타데이터가 모두 원격(또는 로컬)의 데이터베이스에 저장됩니다.
ex) mysql, postresql 등
원격 메타스토어(Remote metastore)
원격 메타스토어의 경우에도 메타데이터가 모두 원격(또는 로컬)의 데이터베이스에 저장됩니다. 하지만 로컬 메타스토어와는 달리 메타스토어를 서비스하는 별도의 서버가 기동되며, 클라이언트는 데이터베이스에 집접 쿼리문을 날리는 대신 메타스토어 서버의 중개를 받게 됩니다. 이때 클라이언트와 메타스토어 서버는 thrift 통신을 사용합니다.
Hive 메타스토어의 설정 파라미터
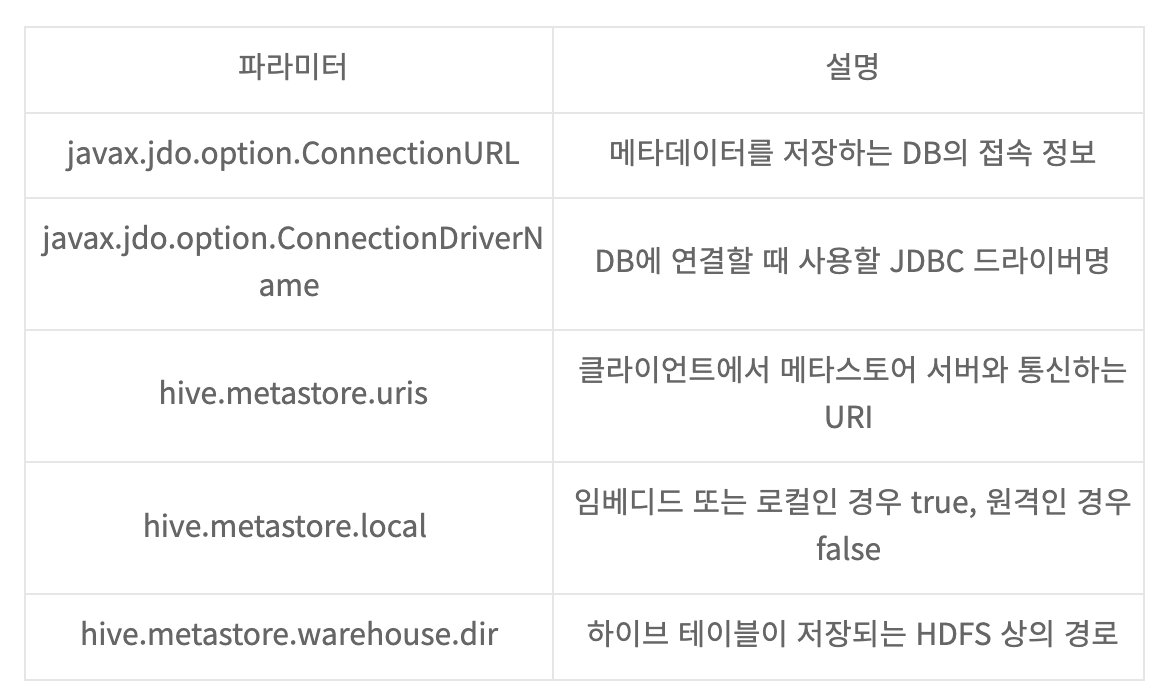
Hive-site.xml
- hive.metastore.warehouse.dir :
데이터 웨어하우스를 저장하는 기본 디렉토리입니다. 기본값은 /user/hive/warehouse - hive.exec.scratchdir :
하이브 잡이 수행될 때 생성되는 데이터를 저장할 HDFS 디렉토리입니다. 기본 경로는 “/tmp/hive-계정명” - hive.metastore.local :
원격 서버에 설치된메타스토어데이터베이스에 접속할 것인지,로컬에 아파치 더비를 이용할 것인지 설정합니다.기본값은true로 설정돼 있어서,로컬의 아파치 더비를 사용합니다.여러 사용자가 함께 사용한다면false로 설정한 후, JDBC설정 속성을 함께 등록 - javax.jdo.option.ConnectionDriverName :
메타스토어 데이터베이스에 접근할 때 사용할 JDBC 드라이버입니다. 기본 드라이버는 org.apache.derby.jdbc.EmbeddedDriver 입니다. - javax.jdo.option.ConnectionURL :
메타스토어 데이터베이스에 접속하기 위한 커넥션 스트링 값입니다. 기본값은 jdbc:derby:;databaseName=metastore_db;create=true - javax.jdo.option.ConnectionUserName :
메타스토어용 데이터베이스에 로그인하는 사용자명입니다. 기본값은 APP - javax.jdo.option.ConnectionPassword :
JDBC 메타스토어용 데이터베이스에 로그인하는 암호이며, 기본값은 mine 으로 설정
