
카프카 개요
오늘날 카프카가 없는 데이터 처리 아키텍처를 상상해보기란 어려울 것입니다. 그만큼 데이터가 비지니스의 핵심이 된 오늘날 현실 속에서 만약 카프카가 없었다면 급속도로 변화하는 다양한 비즈니스의 요구사항들을 충족시키기란 매우 어렵고 고된 일이 될 것 입니다.
오늘날 데이터 처리에서 중요한 핵심 역할을 하는 카프카는 미국의 대표적인 비지니스 인맥 소셜 네트워크 서비스인 링크드인(LinkedIn) 에서 근무하던 제이 크렙스, 준 라오, 네하 나크헤데 가 링크드인 서비스 내에서 발생하고 있는 이슈들을 해결하기 위해서 만들어지게 되었습니다.
데이터 파이프라인 확장의 어려움, 이기종 간의 호환성, 고성능 기반의 실시간 데이터 처리의 어려움 등의 문제를 해결 하기 위해 2010년 개발된 카프카는 일년 뒤인 2011년 아파치(Apache) 오픈소스로 세상에 처음 공개가 되었습니다.
링크드인이 자사에서 직접 개발한 카프카를 첫 도입하면서 링크드인 고객의 서비스 만족도가 높아지는 긍정적인 효과를 이끌어냈습니다.
링크드인 서비스를 사용하는 고객이 직장(JOB)을 변경하면 해당 변경 내용이 링크드인을 사용하는 지인들에게 곧바로 업데이트 되고 링크드인 내부 서비스에도 즉시 반영되어 추천 로직을 거쳐 실시간으로 직장 추천도 가능하게 되었습니다.
카프카의 창시자인 제이 크렙스는 공동 창시자인 준 라오, 네하 나크헤데와 함께 링크드인에서 독립하여 2014년에 컨플루언트(www.confluent.io) 라는 회사를 설립 하였으며, 현재까지 카프카를 계속해서 발전 시키면서 프로젝트를 리드해가고 있습니다.
카프카가 굉장히 안정적인 애플리케이션이며 사용자들의 요구에 맞춰 크고 작은 신기능들이 발 빠르게 추가되면서 고객을 끊임없이 만족시켜줬기 때문에 이와 같은 이유로 실시간 스트리밍 플렛폼이 필요한 곳에서 대부분 카프카를 필수 요소로 채택하여 많은 곳에서 사용되고 있습니다.
카프카의 주요 특징
1. 높은 처리량과 낮은 지연시간
카프카를 선택하는 가장 큰 이유 일 것 입니다. 앞에 사례에서도 그렇고 카프카는 매우 높은 처리량과 낮은 지연시간(latency) 을 자랑 힙니다.
컨플루언트의 블로그에는 메세지 시스템 간의 성능을 비교한 자료가 공개 되어 있습니다.
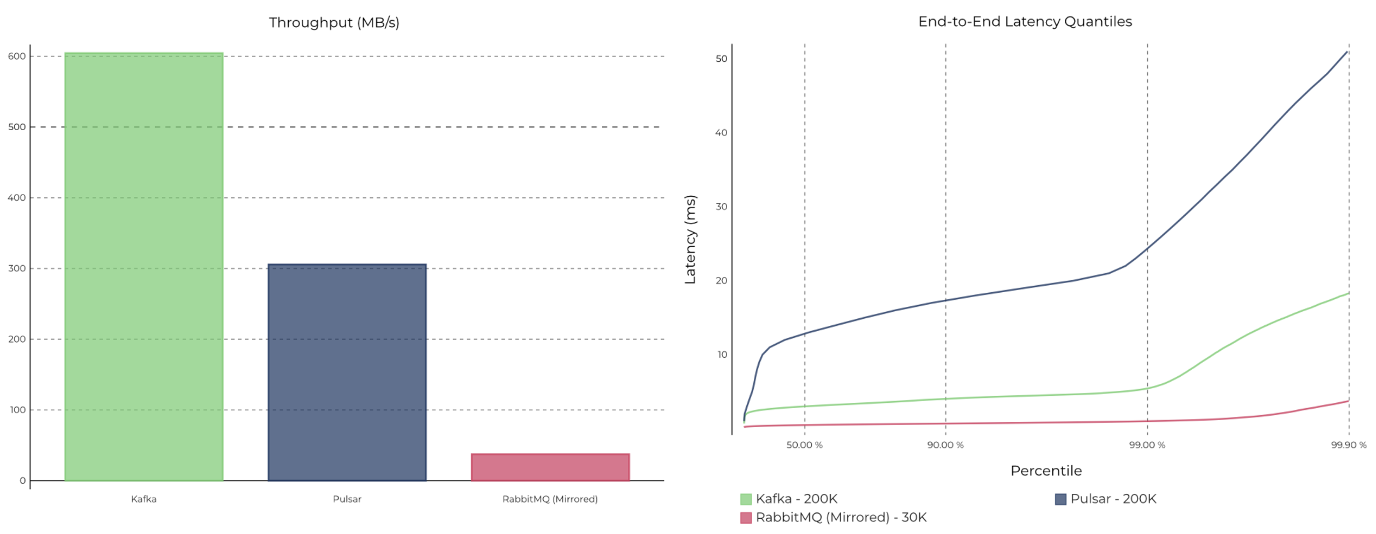
위의 이미지에서 아파치 카프카, 북키퍼(BookKeeper) 기반의 스토리지를 이용한 펄사(Pulsar), 전통적인 메세지 큐 시스템인 래빗MQ(RabbitMQ), 총 세가지 메세징 시스템의 비교한 내용을 확인 할 수 있습니다.
위의 벤치마크의 결과에서 확인 할 수 있듯이 처리량과 응답속도를 같이 비교하면 카프카가 다연 독보적으로 좋다고 할 수 있습니다.
2. 높은 확장성
처리량이 높은 시스템이라도 그 한계 또는 끝은 존재하기 마련 입니다. 이러한 문제를 해결할 수 있는 가장 쉬운 방법은 확장을 하는 것이라고 생각 합니다.
카프카는 손쉬운 확장이 가능하고 잘 설계된 애플리케이션 입니다.
링크드인이 비즈니스 적으로 급성장 하면서 애플리케이션 확장의 필요성을 느끼게 되었습니다. 확장하기 어려운 애플리케이션에서 어려움을 겪으면서 이러한 문제점을 개선하고자 카프카 초기부터 확장이 가능하도록 설계를 하게 되었습니다.
3. 고가용성
카프카 초기버전에서는 무엇보다 메세지를 빠르게 처리하는 것이 목표였지만, 점차 시간이 지나면서 고가용성 측면도 중요하게 생각하게 되었습니다. 카프카는 2013년 에 클러스터 내 레플리케이션 기능을 추가 하였습니다.
고가용성(High Availability) 라는 개념은 간단해 보이지만, 내부 레플리케이션에 대한 로직은 매우 어렵고 복잡합니다. 이러한 복잡하지만 좋은 기능은 고가용성 기능을 카프카는 지원하고 있습니다.
4. 내구성
프로듀서는 카프카로 메세지를 전송할 때, 프로듀서의 acks 라는옵션을 조정하여 메세지의 내구성을 강화할 수 있습니다.
강력한 메세지의 내구성을 원한다면 옵션에서 acks=all 로 사용할 수 도 있습니다.
이렇게 프로듀서에 의해 카프카로 전송되는 모든 메세지는 안전한 저장소인 카프카 로컬 디스크에 저장되게 됩니다.
카프카의 경우에는 컨슈머가 메세지를 가져가더라도 메세지는 삭제되지 않고 지정한 설정 시간 또는 로그의 크기 만큼 로컬 디스크에 보관되므로 코드의 버그나 장애가 발생하더라도 과거의 메세지들을 불러와 재처리 할 수 있습니다.
5. 개발 편의성
카프카는 메세지를 전송하는 역할을 하는 프로듀서 와 메세지를 가져오는 역할을 하는 컨슈머가 완벽하게 분리 되어 동작하고 서로 영향을 주지도 받지도 않습니다.
따라서 프로듀싱을 원하는 개발자는 프로듀싱만 보면 되고, 컨슈밍을 원하는 개발자는 컨슈머만 보면 됩니다.
또한 개발 편의성을 제공하기 위해 카프카에서는 카프카 커넥트(Kafka Connect) 와 스키마 레지스트리 를 제공 하고 있습니다.
6. 운영 및 관리 편의성
카프카는 앞서 언급한 여러 장점으로 인해 중앙 메인 데이터 파이프라인 역할을 하게 되는데, 운영이나 관리의 편의성이 떨어진다면 그와 같은 주요 역할을 맡기가 부담스러울수도 있습니다.
중요한 역할을 하는 애플리케이션이라면 성능 확장을 위한 증설 작업이 쉽고 간단해야 하며, 최신 버전이 릴리즈되는 경우 무중단으로 버전 업그레이도 가능해야 하고 , 버전 업그레이드 작업 역시 단순 해야 합니다.
이런 측면에서는 카프카는 다양한 기능과 3rd Party 를 통해 관리 편의성을 높일수 있는 부분이 있습니다.
카프카의 사용 사례
데이터 파이프라인 : 넷플릭스 사례
넷플릭스는 데이터 기반 회사로서 풍부한 데이터 분석을 통해 비지니스와 제품에 대한 의사결정을 내립니다.
전 세계에 걸쳐 커다란 규모로 데이터를 수집,통계, 처리 , 적재 하기 위한 파이프라인들이 연결되어 있어 이러한 파이프라인을 연결해주는 역할로 카프카를 사용하고 있습니다.
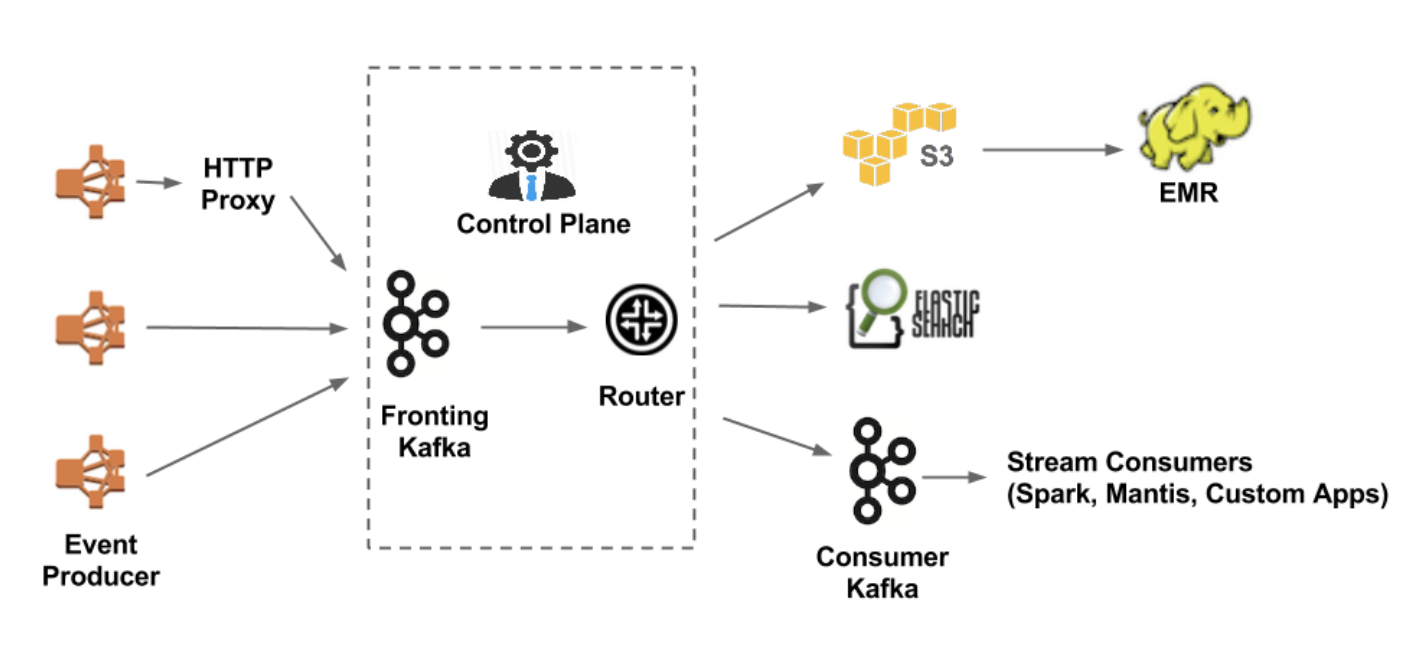
넷플릭스 사용자의 시청 활동, 유저 인터페이스 사용 빈도, 에러 로그 등의 모든 이벤트는 데이터 파이프라인을 통해 흐르게 되고 넷플릭스는 이러한 내용을 분석하여 사용자의 경험을 예측해 능동적으로 대응할 수 있게 됩니다.
카프카(Kafka)란?
Apache Kafka는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 오픈 소스 분산 이벤트 스트리밍 플랫폼(distributed event streaming platform)입니다.
이벤트 스트리밍은 인체의 중추 신경계에 해당하는 디지털 처리 방식입니다. 이는 비즈니스가 점점 더 소프트웨어화, 자동화되는 'always-on' 세상을 위한 기술 기반입니다. Kafka의 이벤트 스트리밍은 Fortune 100대 기업의 60% 이상을 포함하여 수많은 산업 및 조직의 다양한 사용 사례 에 적용됩니다.
증권 거래소, 은행 및 보험과 같은 실시간으로 지불 및 금융 거래를 처리
물류 및 자동차 산업과 같이 자동차, 트럭, 차량 및 선적을 실시간으로 추적하고 모니터링
공장 및 풍력 발전 단지와 같은 IoT 장치 또는 기타 장비의 센서 데이터를 지속적으로 캡처하고 분석
소매, 호텔 및 여행 산업, 모바일 애플리케이션과 같은 고객 상호 작용 및 주문을 수집하고 즉시 대응
병원에서 치료 중인 환자를 모니터링하고 상태 변화를 예측하여 응급 상황에서 시기 적절한 치료를 보장
회사의 여러 부서에서 생성된 데이터를 연결, 저장 및 사용 가능하게 만듦
데이터 플랫폼, 이벤트 중심 아키텍처 및 마이크로서비스(MSA)의 기반 역할
이벤트 스트리밍 플랫폼
Kafka는 세 가지 주요 기능을 결합하여 end-to-end 이벤트 스트리밍을 구현할 수 있습니다.
- 이벤트 스트림을 지속적으로 발행(publish-write), 구독(subscribe-read) 합니다.
- 이벤트 스트림을 원하는 만큼 내구성 있고 안정적으로 저장(store) 합니다. KafkaCluster(broker)
- 이벤트 스트림 을 발생 시 또는 소급하여 처리(Process) 합니다.
그리고 이 모든 기능은 분산되고 확장성이 뛰어나고 탄력적이며 내결함성이 있으며 안전한 방식으로 제공됩니다. Kafka는 베어메탈 하드웨어, 가상 머신, 컨테이너, 온프레미스 및 클라우드에 배포할 수 있습니다. Kafka 환경을 자가 관리하거나 다양한 공급업체에서 제공하는 완전 관리형 서비스를 사용할 수 있습니다.
메시지 큐(Message Queue : MQ)
메시지 지향 미들웨어(Message Oriented Middleware:MOM)는 비동기 메시지를 사용하는 각각의 응용프로그램 사이의 데이터 송수신을 의미하고, 이를 구현한 시스템을 메시지큐(Message Queue:MQ)라 합니다.
많이 사용하는 오픈소스 MQ로는 RabbitMQ ActiveMQ RedisQueue등이 있습니다.
Kafka는 이벤트 스트리밍 플랫폼으로서 여러가지 역할을 할 수 있고 MQ처럼 메시지 브로커 역할을 할 수 있도록 구현하여 사용할 수도 있으며 기존 범용 메시지브로커들과 비교했을때 아래와 같은 특징을 가집니다.
- 대용량의 실시간 로그 처리에 특화되어 TPS가 우수하다. - 고성능
- 분산 처리에 효과적으로 설계 되어 병렬처리와 확장(Scaleout), 고가용성(HA) 용이 - 클러스터링
- 발행/구독(Publish-Subscribe) 모델 ( Push-Pull 구조 )
- 메시지를 받기를 원하는 컨슈머가 해당 토픽(topic)을 구독함으로써 메시지를 읽어 오는 구조
- 기존에 퍼블리셔나 브로커 중심적인 브로커 메시지와 달리 똑똑한 컨슈머 중심
- 브로커의 역할이 줄어들기 때문에 좋은 성능을 기대할 수 있음 - 파일 시스템에 메시지를 저장함으로써 영속성(durability)이 보장
장애시 데이터 유실 복구 가능
메시지가 많이 쌓여도 성능이 크게 저하되지 않음
대규모 처리를 위한 batch 작업 용이
주요 개념 및 용어
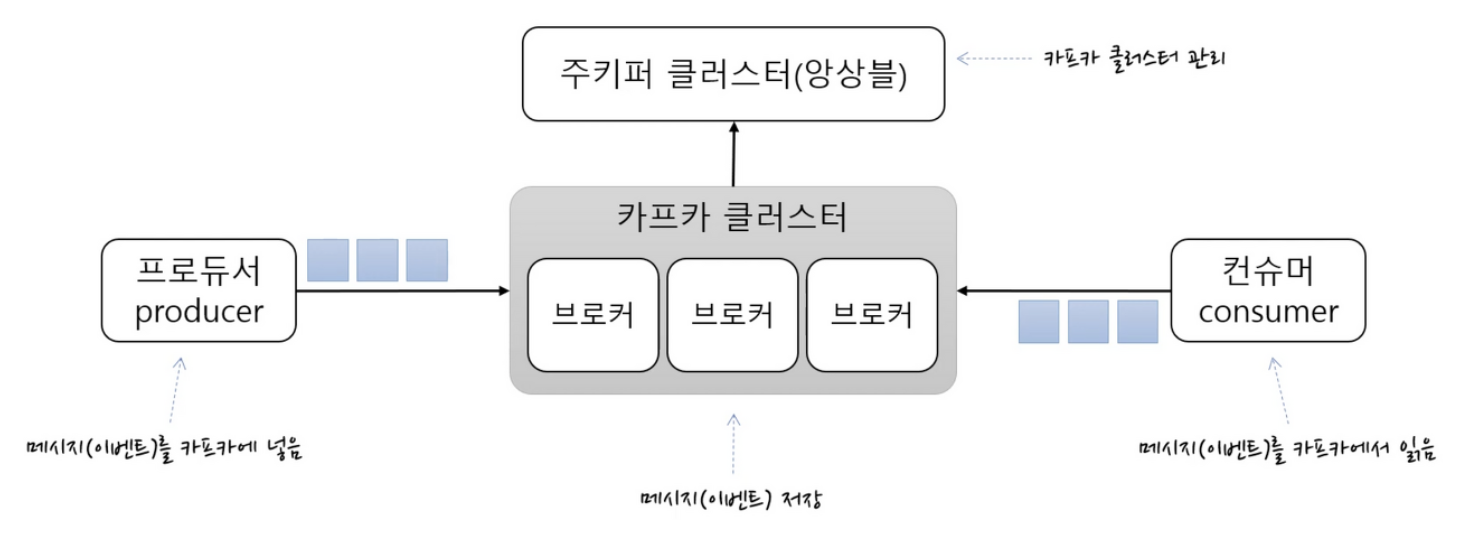
- KafkaCluster : 카프카의 브로커들의 모임. Kafka는 확장성과 고가용성을 위하여 broker들이 클러스터로 구성
- Broker : 각각의 카프카 서버, 동일 노드에 여러 브로커를 띄울 수 있다.
- Zookeeper : 카프카 클러스터 정보 및 분산처리 관리 등 메타데이터 저장. 카프카를 띄우기 위해 반드시 실행되어야 함(곧 카프카 클러스터와 통합 예정)
- Producer : 메시지(이벤트)를 발행하여 생산(Wirte) 하는 주체
- Consumer : 메시지(이벤트)를 구독하여 소비(Read) 하는 주체
토픽, 파티션, 오프셋
카프카에 저장되는 메시지는 topic으로 분류, topic은 여러개의 patition으로 나눠짐
- Topic : 메시지를 구분하는 단위
파일시스템의 폴더, 메일함과 유사함 ex) 주문용 토픽, 결제용 토픽 등 - Partition : 메세지를 저장하는 물리적인 파일
한 개의 토픽은 한 개 이상의 파티션으로 구성됨
파티션은 메시지 추가만 가능한 파일(append-only) - offset : 파티션내 각 메시지의 저장된 상대적 위치
프로듀서가 넣은 메시지는 파티션의 맨 뒤에 추가 (Queue)
컨슈머는 오프셋 기준으로 마지막 커밋 시점부터 메시지를 순서대로 읽어서 처리함
파티션의 메시지 파일은 처리 후에도 계속 저장되어 있며 설정에 따라 일정시간 뒤 삭제됨
프로듀서
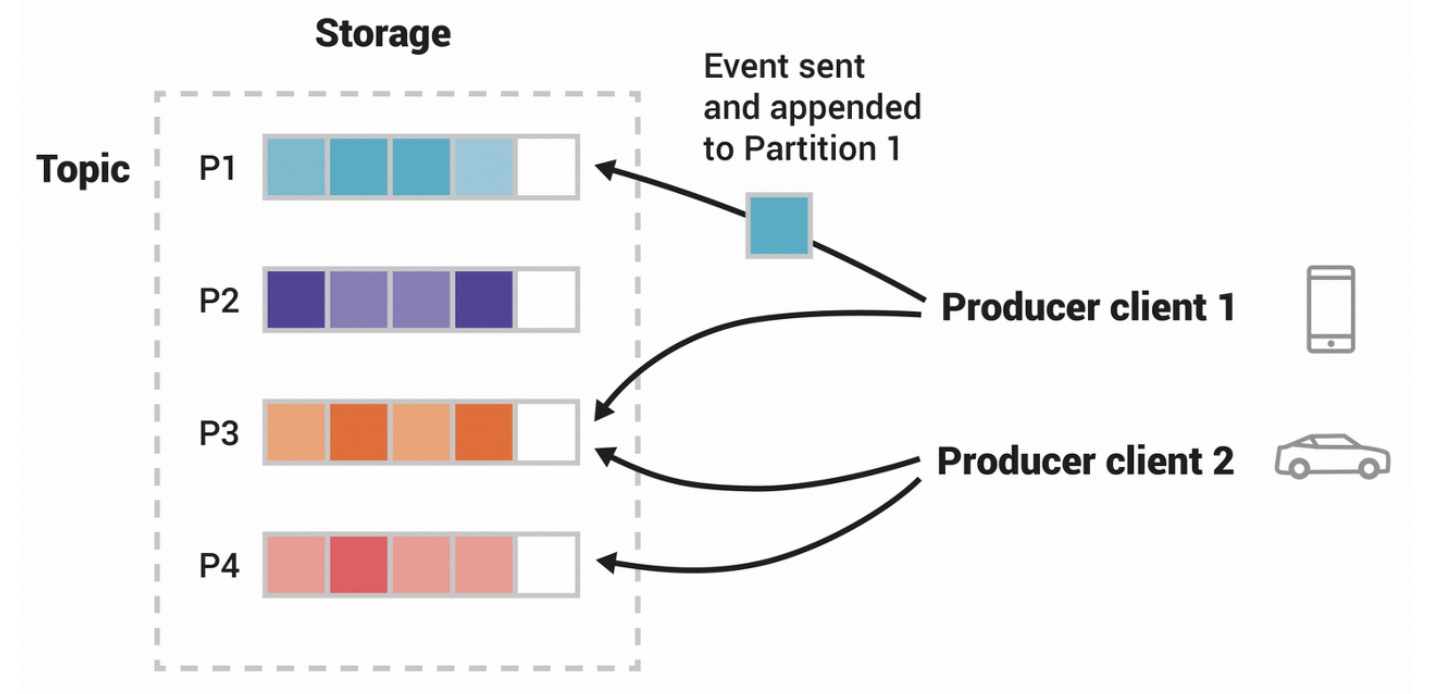
Producer: 메시지(이벤트)를 발행하여 생산(Wirte) 하는 주체
프로듀서는 메시지 전송시 토픽을 지정
파티션은 라운드로빈 방식 혹은 파티션 번호를 지정하여 넣을 수 있음
같은 키를 갖는 메시지는 같은 파티션에 저장 되며 순서 유지
컨슈머
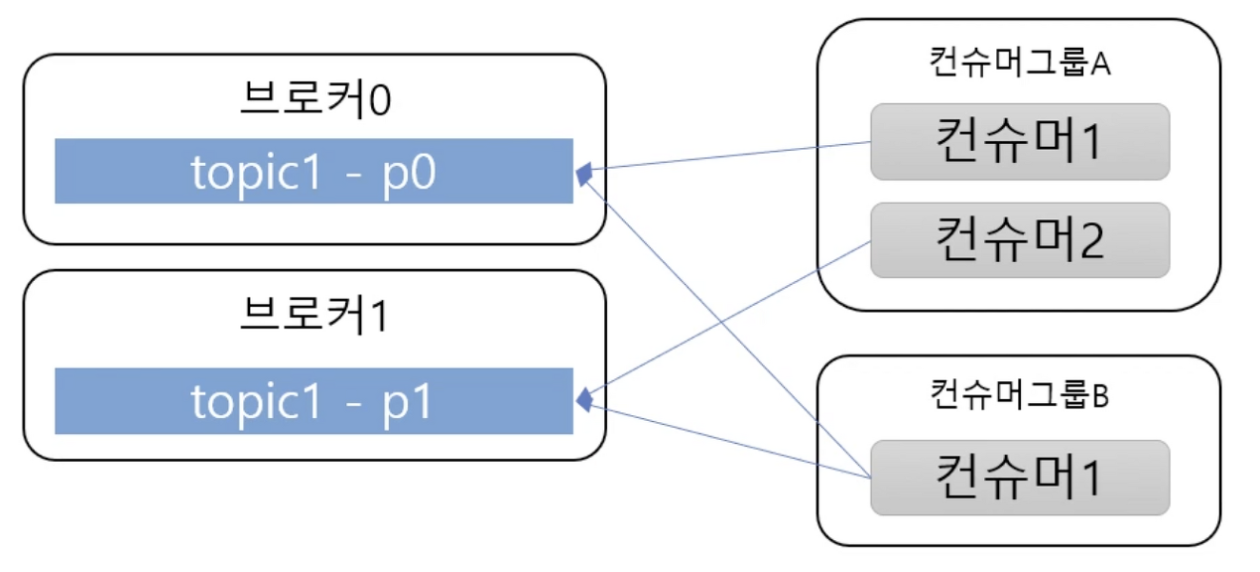
Consumer : 메시지(이벤트)를 구독하며 소비(Read)하는 주체
- Consumer Group
메시지를 소비하는 컨슈머들의 논리적 그룹
Topic의 파티션은 컨슈머그룹과 1:N 매칭 관계로 동일 그룹내 한 개의 컨슈머만 연결가능 하다.
이로써 파티션의 메시지는 순서대로 처리되도록 보장
특정 컨슈머에 문제가 생겼을때 Fail over를 통한 리밸런싱 가능
보통 파티션과 컨슈머는 1:1이 best practice로 봄
