
서비스 구현방식에 대한 내용을 하기 앞서 먼저 간략하게 K8s 서비스를 이해하고 갑시다.
K8s 서비스
서비스의 탄생 배경
K8s에 파드는 애플리케이션을 구동시키기 위해 뜨는 리소스이며 이는 외부 요청없이 독립적으로 수행할 수도 있지만, 주로 외부의 요청에 응답하기 위해 구성됩니다.
마이크로서비스의 경우 파드는 대개 클러스터 내부의 다른 파트나 클러스터 외부의 클라이언트에서 오는 HTTP 요청에 응답합니다.
이 말은 파드가 다른 파드에게 제공하는 서비스를 사용하려면 다른 파드를 찾는 방법이 필요하다는 건데요.
쿠버네티스가 아닌 세계에서는 시스템 관리자가 클라이언트 구성 파일에 서비스를 제공하는 서버의 정확한 IP 주소나 호스트 이름을 지정해 각 클라이언트 애플리케이션을 구성하여 사용할 수 있지만,
쿠버네티스는 파드가 일시적이고 클라이언트는 서버인 파드의 IP 주소를 미리 알 수 없을 뿐더러 (파드가 노드에 스케줄링 되고 파드가 시작되기 전에 IP 주소가 할당됨) 수평 스케일로 여러 파드에 동일한 서비스를 제공하는 경우 여러개의 파드 고유한 IP 파드 주소 목록을 유지해야하는데 이를 클라이언트가 고려해야할 이유가 없다…
무튼!! 이러한 이유로 pod 만으로 외부 접근을 시키기 어려움이 있고 이를 해결하고자 제공되는 리소스가 서비스이다.
서비스가 뭔데?
쿠버네티스의 서비스는 동일한 서비스를 제공하는 파드 그룹에 지속적인 단일 접점을 만들려고 할 때 생성하는 리소스입니다.
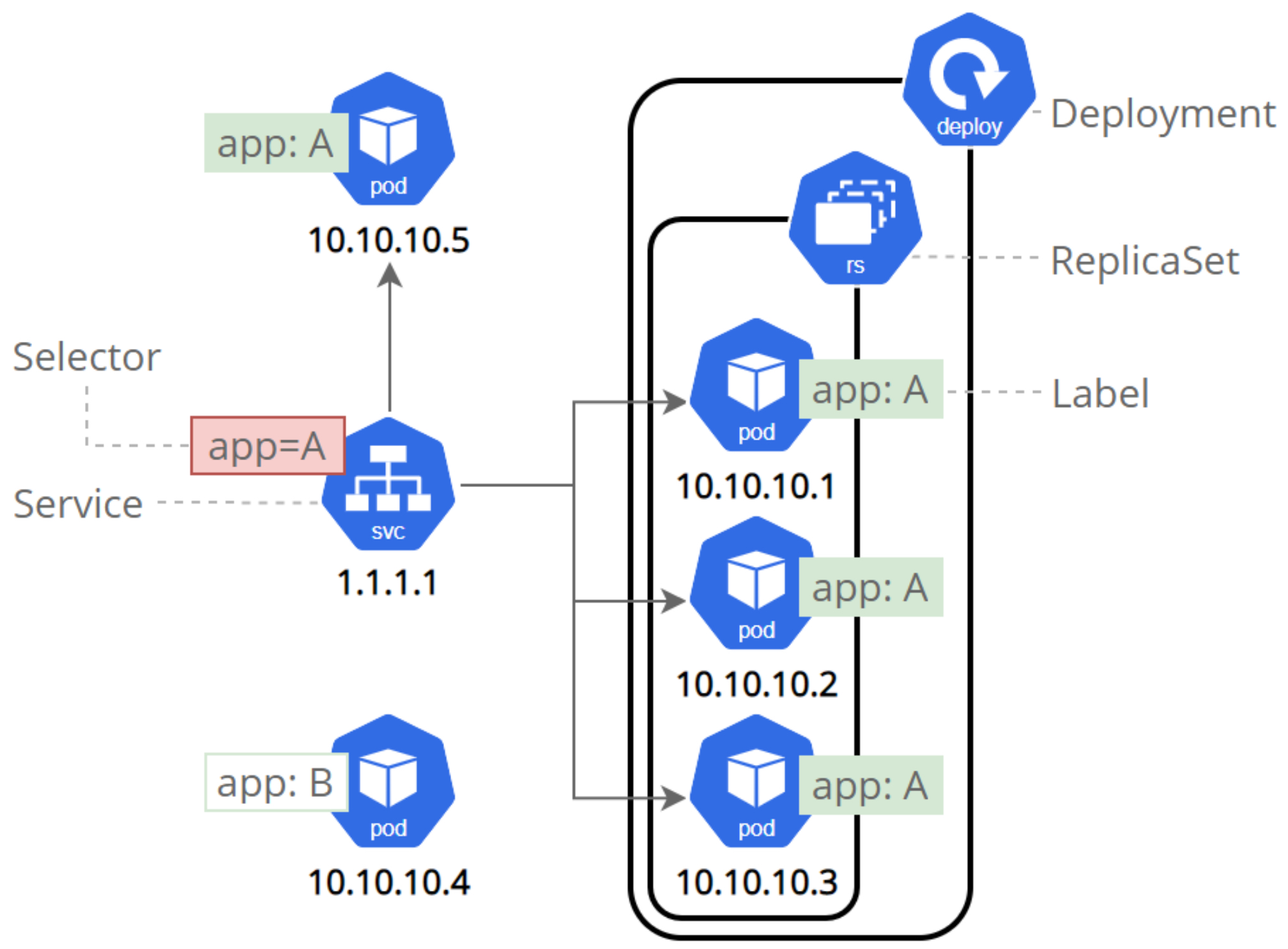
사진에서 보이는 것처럼 특정 서비스를 제공하는 파드 그룹 (deployment)에 1.1.1.1이라는 바뀌지않는 IP 주소를 가진 서비스를 연결하여 외부로부터 트래픽을 해당 IP와 포트로 받을 수 있습니다.
각 서비스는 서비스가 존재하는 동안 절대 바뀌지 않는 IP 주소와 포트가 있다.
클라이언트는 해당 IP와 포트로 접속한 다음 해당 서비스를 지원하는 파드 중 하나로 연결된다. 이러한 방식으로 서비스의 클라이언트는 서비스를 제공하는 개별 파드의 위치를 알 필요도 없고 이 파드는 언제든지 클러스터 안에서 이동할 수 있습니다.
또한 뒤에 연결되는 파드가 추가되거나 삭제, 변경되어도 항상 서비스의 IP 주소로 액세스할 수 있습니다.
서비스 검색
그렇다면 클라이언트 파드는 서비스의 IP와 포트를 어떻게 알 수 있을까요?
서비스를 생성한 다음 IP 주소를 수동으로 찾아서 클라이언트 파드의 구성 옵션에 IP를 전달해야할까?
에이… 설마 그럴리가 너무 짜칩니다.
쿠버네티스는 쿠버네티스 클라이언트 파드가 서비스의 IP와 포트를 검색할 수 있는 방법을 제공하는데요.
환경변수를 통한 서비스 검색
파드가 시작되면 쿠버네티스는 해당 시점에 존재하는 각 서비스를 가리키는 환경변수 세트를 초기화합니다.
즉, 클라이언트 파드를 생성하기 전에 서비스를 생성하면 해당 파드의 프로세스는 환경변수를 검사해 서비스의 IP 주소와 포트를 얻을 수 있습니다.
(컨테이너 내부에서 env 명령어를 실행하면 환경변수가 조회됩니다.)
이 방법의 단점은 파드가 만들어진 후 생성된 서비스는 환경변수에 없다…
그래서 이러한 방법이 있지만 대개 DNS의 도메인을 사용한다.
DNS를 통한 서비스 검색
Kube-system 네임스페이스 안에 kube-dns라는 이름의 파드가 있다.
이름에서 알 수 잇듯이 이 파드는 DNS 서버를 실행하면 클러스터에서 실행 중인 다른 모든 파드는 자동으로 이를 사용하도록 구성된다.
(각 컨테이너의 /etc/resolv.conf 파일을 쿠버네티스가 수정해 이를 수행한다.)
파드에서 실행 중인 프로세스에서 수행된 모든 DNS 쿼리는 시스템에서 실행중인 모든 서비스를 알고 있는 쿠버네티스의 자체 DNS 서버로 처리된다.
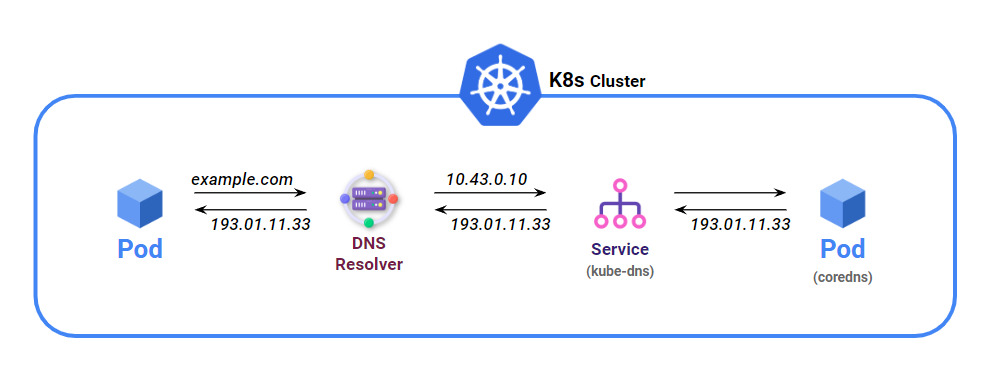
각 서비스는 내부 DNS 서버에서 DNS 항목을 가져오고 서비스 이름을 알고 있는 클라이언트 파드는 환경변수 대신 FQDN으로 액세스할 수 있다.
Ex. 서비스명.namespace.svc.cluster.local
FQDN 을 통한 서비스 연결
FQDN을 사용하면 서비스에 연결하는 것이 훨씬 간단하다.
이것이 가능한 것은 파드 컨테이너 내부의 DNS resolver가 구성되어있기 때문에 네임스페이스와 svc.cluster.local 접미사를 생략할 수 있다.
컨테이너에서 /etc/resolv.conf 파일을 보면
cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local클러스터 외부의 서비스 연결
지금까지는 클러스터 내부에서 실행중인 하나 이상의 파드와 통신을 지원하는 서비스를 설명했다.
그러나 쿠버네티스 서비스 기능으로 외부 서비스를 노출하려는 경우가 있을 수 있다.
서비스가 클러스터 내에 있는 파드로 연결을 전달하는 게 아니라, 외부 IP와 포트로 연결을 전달하는 것이다.
서비스 엔드포인트
서비스는 파드 그룹을 앞단에서 불변 IP로 연결하고 있지만 직접 연결되고 있는 구조는 아니다!!
대신 엔드포인트 리소스가 그 사이에 있다.
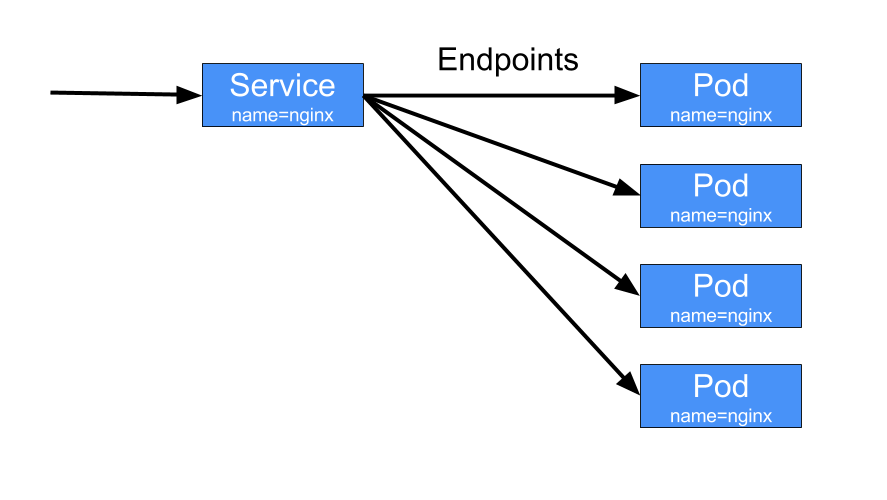
엔드포인트 리소스는 서비스로 노출되는 파드의 IP 주소와 포트 목록이다.
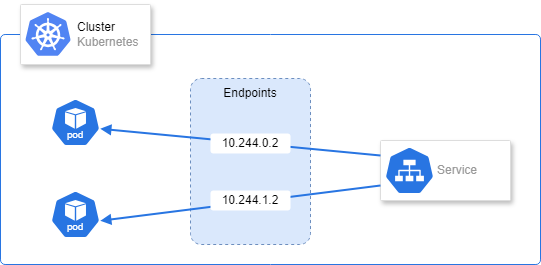
엔드포인트 리소스는 다른 쿠버네티스 리소스와 유사하므로 kubectl get을 사용해 기본 정보를 표시할 수 있다.
파드 셀렉터는 엔드포인트 레소스에 저장될 IP와 포트 목록을 작성하는 데 사용되며 클라이언트가 서비스에 연결하면 서비스 프록시는 이들 중 하나의 IP 와 포트쌍을 선택하고 들어온 연결을 대상 파드의 수신대기 서버로 전달합니다.
외부 클라이언트에 서비스 노출
지금까지는 클러스터 내부에서 파드가 서비스를 사용하는 방법을 배웠다.
그럼 프론트엔드 웹 서버와 같이 특정 서비스를 외부에 노출해 외부 클라이언트가 액세스할 수 있게 하려면 어떻게 해야할까?
외부에서 서비스를 액세스할 수 있는 방법은 몇가지 있다.
1. 노드포트로 서비스 유형 설정
2. 로드밸런서로 서비스 유형 설정
3. 단일 IP 주소로 여러 서비스를 노출하는 인그레스 리소스 만들기
하나씩 알아보자.
1. 노드포트 서비스
노드포트 서비스를 만들면 쿠버네티스는 모든 노드에 특정 포트를 할당하고 서비스를 구성하는 파드로 들어온 연결을 전달한다.
이것은 일반 서비스와 유사하지만 서비스의 내부 클러스터 IP뿐 아니라 모든 노드의 IP와 할당된 노드포트로 서비스에 액세스할 수 있다.
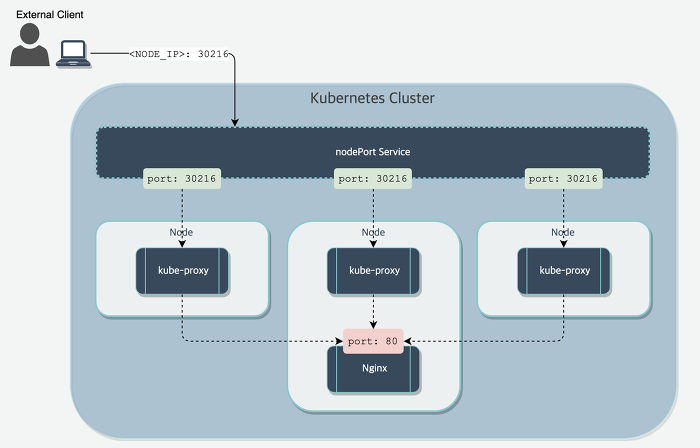
사진에서 보듯 node port로 지정한 30216 포트로 모든 트래픽이 들어오고 요청자의 니즈에 맞는 서비스가 실행중인 서비스가 존재하는 두번째 노드의 파드로 전달됩니다.
2. 외부 로드밸런서
로드밸런서는 노드포트 서비스의 확장 개념입니다.
로드밸런서는 공개적으로 액세스 가능한 고유한 IP 주소를 가지며 모든 연결을 서비스로 전달합니다.
따라서, 로드 밸런서의 IP 주소로 서비스에 액세스할 수 있습니다.
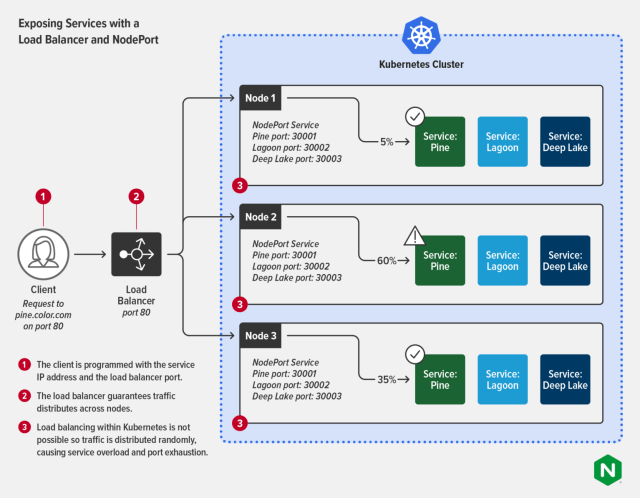
외부 연결의 특성
외부 클라이언트가 노드포트로 서비스에 접속할 경우 임의로 선택된 파드가 연결을 수신한 동일한 노드에서 실행중일 수도 있고, 그렇지 않을 수도 있다.
파드에 도달하려면 추가적인 네트워크 홉이 필요할 수 있으며 이것이 항상 바람직한 것은 아니다.
외부의 연결을 수신한 노드에서 실행중인 파드로만 외부 트래픽이 전달하도록 서비스를 구성해 이 추가홉을 방지할 수 있는데 이것이 externalTrafficPolicy 설정이다.
이 설정이 되어있는 경우 로드밸런서는 실행중인 파드가 하나 이상 있는 노드에만 연결을 전달한다.
따라서, 실행중인 로컬 파드가 존재하지 않으면 연결이 중단된다.
또한, 해당 어노테이션을 사용하면 LB의 균등분배 방식이 더이상 적용되지 않는다.
또한 클러스터 내에서 서비스를 통한 통신의 경우 서비스의 파드는 클라이언트 IP 주소를 얻을 수 있다.
하지만 외부로부터 연결을 받는 경우 노드포트로 연결을 수신하면 패킷에서 소스 네트워크 주소 변환이 수행되므로 패킷의 소스 IP가 변경된다.
즉, 파드는 실제 클라이언트의 IP를 알 수 없어 통신 트러블 발생 시 어디서 온 트래픽에 대한 이슈인지 파악할 수 없다.
3. 인그레스 리소스
위의 2가지 방법이 있는데 인그레스가 추가로 더 필요한 이유가 뭘까..?
인그레스 필요성
로드밸런서 서비스는 자신의 공용 IP주소를 가진 로드밸런서가 필요하지만, 인그레스는 한 IP 주소로 수십개의 서비스에 접근이 가능하도록 지원해준다.
즉, 한개의 인그레스 IP로 접근 시 알아서 요청 호스트와 경로에 따라 요청을 전달할 서비스에 맞게 요청을 전달해준다.
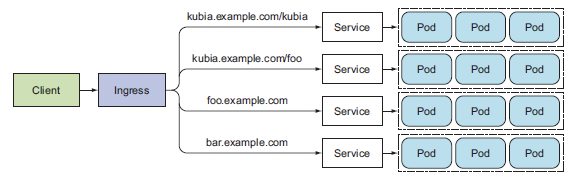
인그레스는 네트워크 스택의 애플리케이션 계층에서 작동하며 서비스가 할 수 없는 쿠키 기반 세션 어피니티 등과 같은 기능을 제공할 수 있다.
인그레스 컨트롤러 필요성
인그레스 리소스를 작동시키려면 클러스터에 인그레스 컨트롤러를 실행해야한다.
인그레스 동작 방식
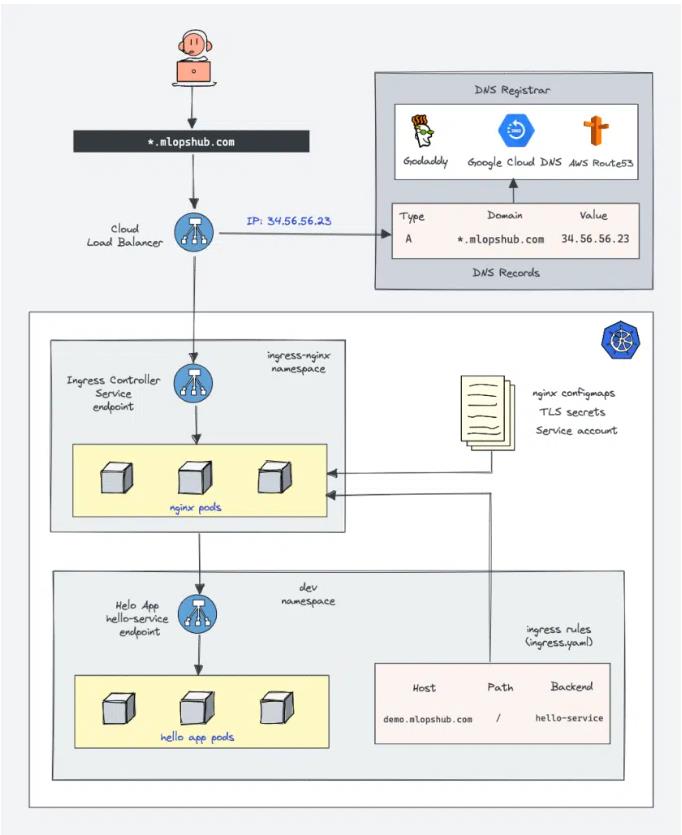
위 사진은 클라이언트가 인그레스 컨트롤러로 파드에 연결하는 방식을 보여준다.
클라이언트는 먼저 mlopshub.com의 DNS 조회를 수행했으며 DNS 서버가 인그레스 컨트롤러 IP를 반환한다.
그런 다음, 클라이언트는 HTTP 요청을 인그레스 컨트롤러로 전송하고 host 헤더에서 mlopshub.com 을 지정한다.
컨트롤러는 해당 헤더에서 클라이언트가 액세스하려는 서비스를 결정하고 서비스와 관련된 엔드포인트 오브젝트로 파드 IP를 조회한 다음 클라이언트 요청을 파드에 전달한다.
보시다시피 인그레스 컨트롤러는 요청을 서비스로 전달하지 않는다.
파드를 선택하는 데만 사용한다. 모두는 아니지만 대부분의 컨트롤러는 이과 같이 동작한다.
하나의 인그레스로 여러 서비스를 노출할 수 있는데, 인그레스 스펙을 보면 규칙과 경로가 배열이므로 여러 항목을 가질 수 있다.

TLS 트래픽 처리하는 인그레스
인그레스가 HTTP 트래픽을 전달하는 방법을 봤다.
HTTPS는 어떨가?
클라이언트가 인그레스 컨트롤러에 대한 TLS 연결을 하면 컨트롤러는 TLS 연결을 종료한다.
Why?..
클라이언트와 컨트롤러 간의 통신은 암호화되지만 컨트롤러와 백엔드 파드 간의 통신은 암호화되지 않는다.
파드에서 실행중인 애플리케이션은 TLS를 지원할 필요가 없다.
즉, 인그레스 컨트롤러가 TLS와 관련된 모든 것을 처리한다.
컨트롤러가 그렇게 하려면 인증서와 개인 키를 인그레스에 첨부해야한다.
이 두개는 시크릿이라는 쿠버네티스 리소스에 저장하고 사용한다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myingress
annotations:
kubernetes.io/ingress.class: "nginx"
cert-manager.io/issuer: "letsencrypt-production"
spec:
tls:
- hosts:
- example.com
secretName: example-tls // 인증서
rules:
- host: example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: hello
port:
number: 80
헤드리스 서비스
지금까지 서비스의 파드에 클라이언트를 연결을 허용하려고 서비스가 안정적인 IP 주소를 제공하는 방법을 살펴봤다.
서비스 연결은 임의의 파드로 전달된다.
그런데.. 클라이언트가 모든 파드에 연결해야하는 경우 어떻게 해야할까?
파드가 다른 파드에 각각 연결해야하는 경우는?
클라이언트가 모든 파드에 연결하려면 각 파드의 IP를 알아야한다.
쉽게 생각해볼 수 있는 방법은 클라이언트가 API 서버를 호출해 파드와 IP 주소 목록을 가져오도록 하는 것이다.
하지만 애플리케이션을 쿠버네티스와 무관하게 유지하려고 노력해야 하기 때문에 항상 API 서버를 사용하는 것은 바람직하지 않다.
다행히 쿠버네티스는 클라이언트가 DNS 조회로 파드 IP를 찾을 수 있도록 한다.
일반적으로 서비스에 대한 DNS 조회를 수행하면 DNS 서버는 하나의 IP를 반환한다.
그러나 쿠버네티스 서비스에 클러스터 IP가 필요하지 않다면 DNS 서버는 하나의 서비스 IP 대신 파드 IP들을 반환한다.
DNS 서버는 하나의 DNS A 레코드를 반환하는 대신 서비스에 대한 여러 개의 A 레코드를 반환한다.
각 레코드는 해당 시점에 서비스를 지원하는 개별 파드의 IP를 가리킨다.따라서, 클라이언트는 간단한 DNS A 레코드 조회를 수행하고 서비스에 포함된 모든 파드의 IP를 얻을 수 있다. 그런 다음 클라이언트는 해당 정보를 사용해 하나 혹은 다수의 또는 모든 파드에 연결할 수 있다.
서비스 스펙의 clusterIP 필드를 None으로 설정하면 쿠버네티스는 클라이언트가 서비스의 파드에 연결할 수 있는 클러스터 IP를 할당하지 않기 때문에 서비스가 헤드리스 상태가 된다.
# headless.yaml
apiVersion: v1
kind: Service
metadata:
name: headless-service
spec:
# type : ClusterIP이지만 clusterIP 필드: None으로 생성
type: ClusterIP
clusterIP: None
# 셀렉터 설정
selector:
app: nginx-for-svc
ports:
- protocol: TCP
port: 80
targetPort: 80이렇게 생성된 헤드리스 서비스는 일반 서비스와 달리 파드 내에서 nslookup 으로 조회해보면 클러스터 IP가 아닌 파드 IP들을 반환한다.
클라이언트 관점에서는 일반 서비스와 마찬가지로 서비스의 DNS 이름에 연결해 파드에 연결하므로 동일해 보일 수 있지만
헤드리스 서비스에서는 DNS가 파드 IP를 반환하기 때문에 클라이언트 서비스 프록시 대신 파드에 직접 연결한다.
헤드리스 서비스는 여전히 파드간에 로드밸런싱을 제공하지만 서비스 프록시 대신 DNS 라운드 로빈 매커니즘으로 제공한다.
