ML pipeline이란
ML pipeline은 아래 그림에서 볼 수 있듯이 여러 구성요소로 구성됩니다.
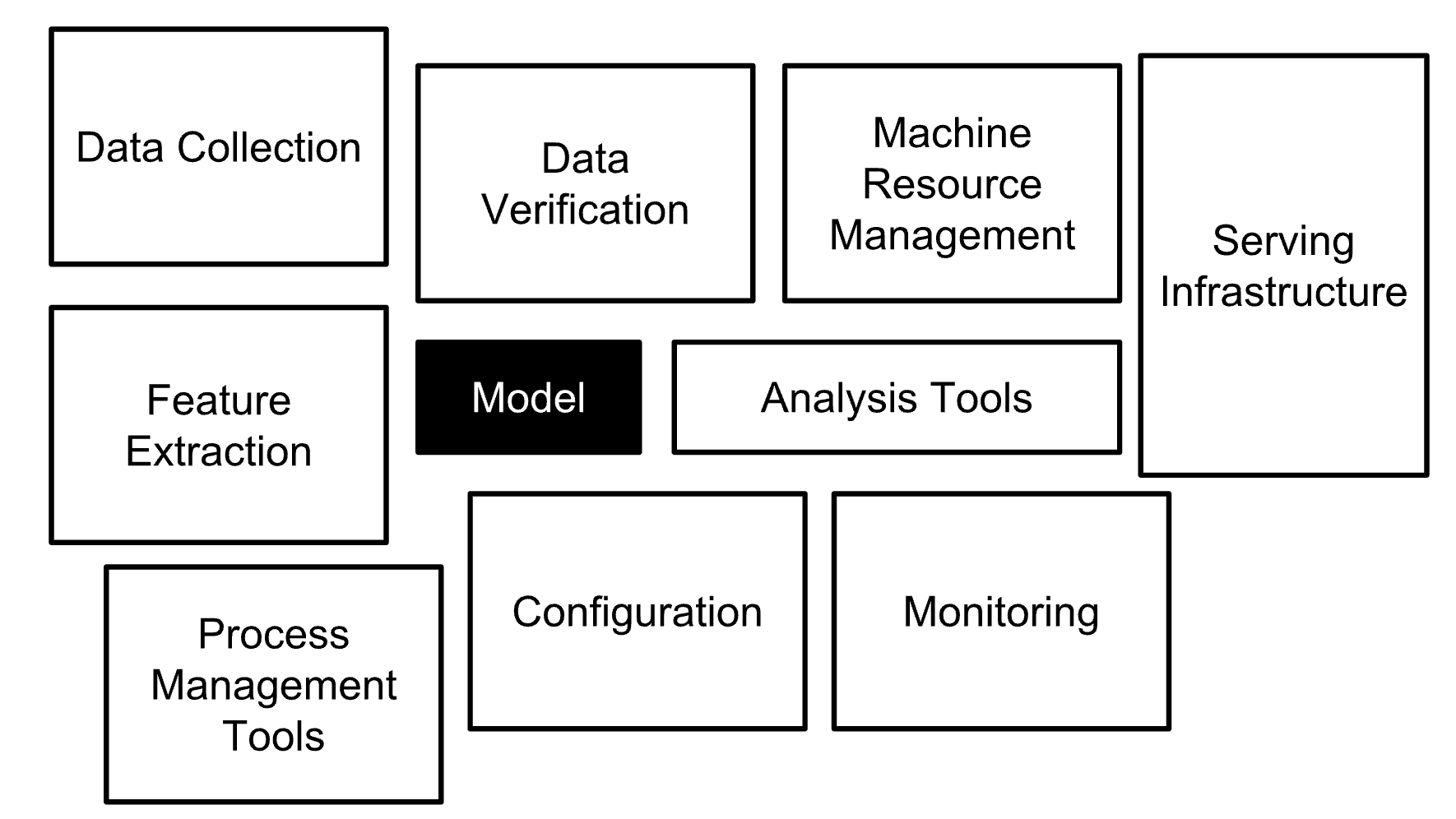
ML pipeline은 모델 학습을 생성하는 데 필요한 워크플로우를 체계화하고 자동화하는 방법입니다.
ML pipeline은 데이터 추출 및 전처리부터 모델 학습, 배포에 이르기까지 모든 작업을 수행하는 여러 순차적 단계로 구성되어있습니다.
ML pipeline 장점
ML pipeline 장점을 알기위해 모델 학습을 위해 data scientist들이 어떤 단계를 거치는 지 알아봅시다.
보통 데싸분들은 단일의 비즈니스 문제를 해결하기 위해 모델 학습 생성에 집중합니다.
실제 팀에서 실제 인프라가 없는 수동 워크플로우로 시작하는 경우도 있으며,데이터 수집, 정리, 모델 학습, 평가 등의 일련의 과정이 단일의 주피터 노트북에 기록되어 로컬에서 실행되어 모델을 생성하고 이를 API 엔드포인트로 전환하는 임무를 맡은 엔지니어에게 전달됩니다.
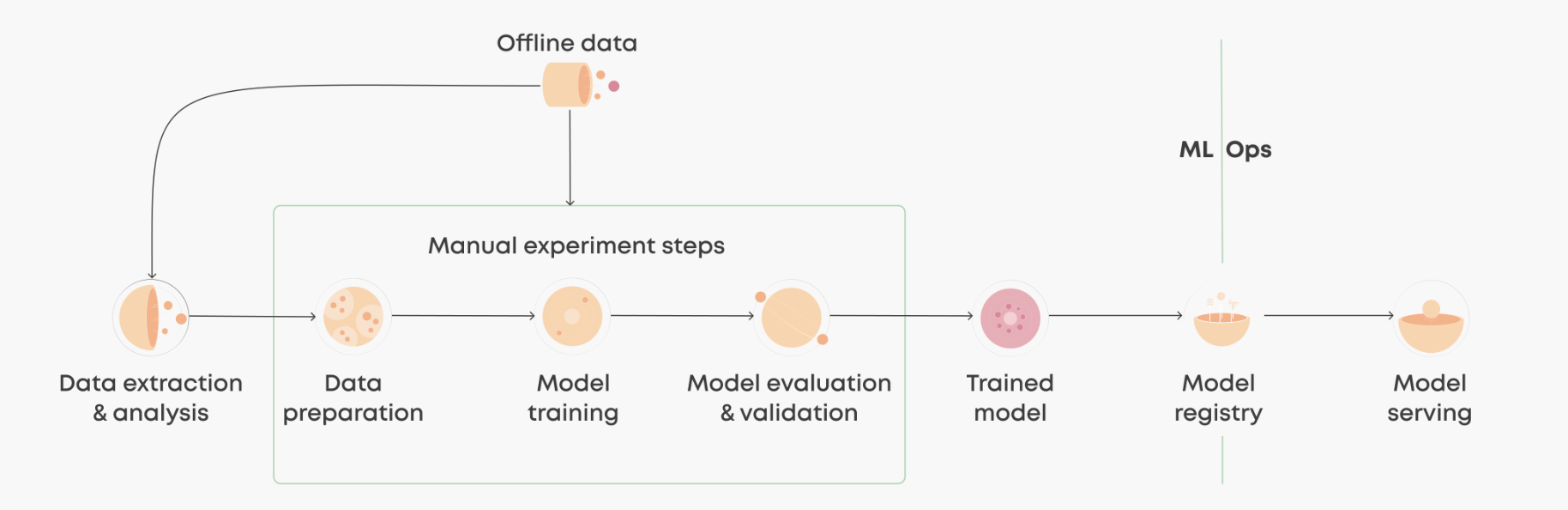
이러한 수동 워크플로우는 임시적이고 반복하거나 자동화 문서화하기 어렵습니다.
따라서, 업무가 반복적으로 진행되거나 중간에 중단되면 다시 진행하는 데에 어려움이 있습니다.
또한 버전 관리가 어렵고, 자동화된 테스트나 성능 모니터링이 불가능하고 그렇기에 반복주기 또한 느리고 데이터 사이언티스트와 엔지니어간의 단절이 생길 수 밖에 없습니다.
반면 자동화된 ML pipeline이 있다면 이러한 문제를 해결할 수 있습니다.
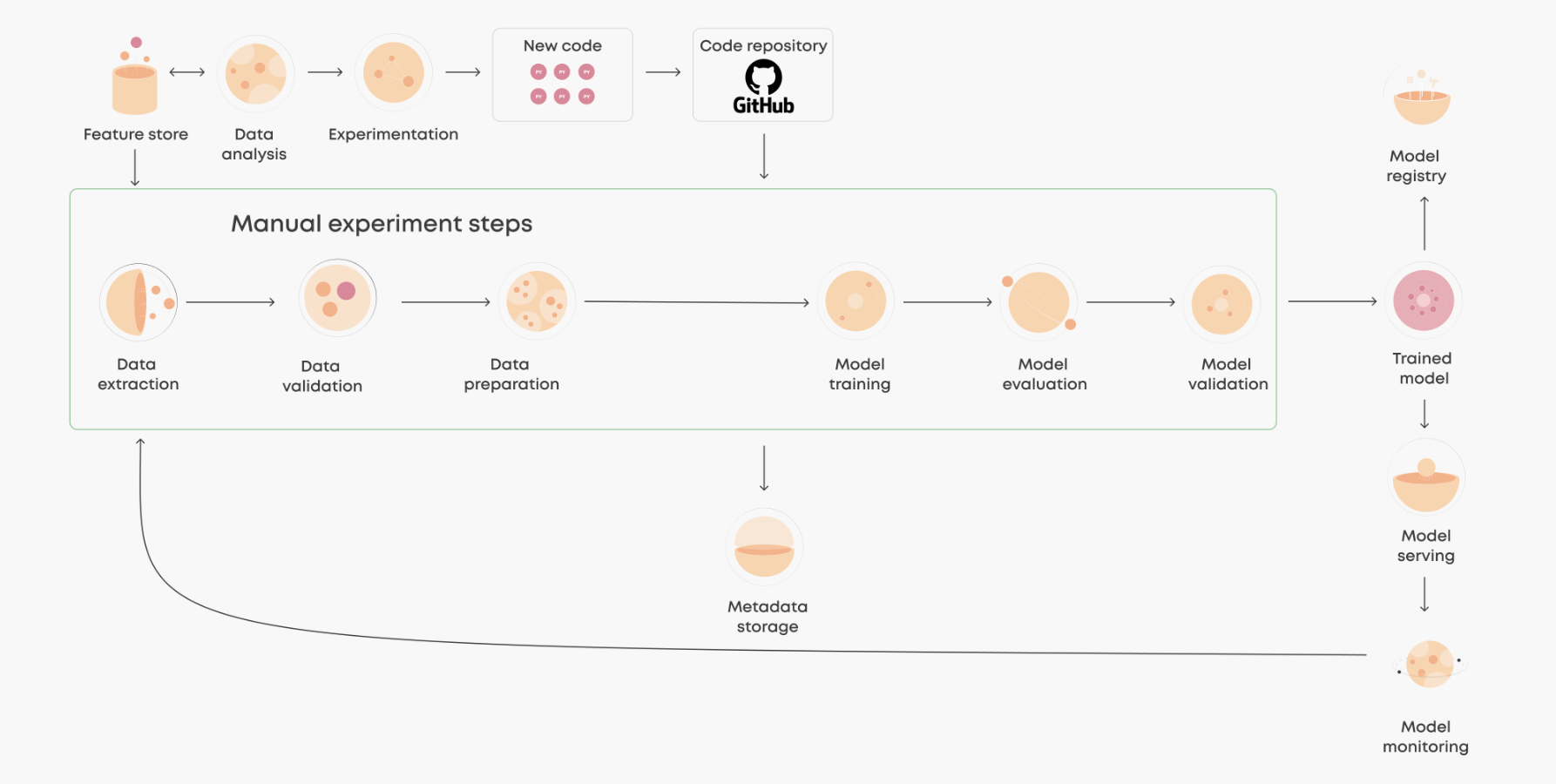
자동화된 워크를로우에서는 엔지니어링 원칙이 견고해야하며 중요합니다.
코드는 데이터 유효성 검사, 모델 학습, 평가, 재교육 트리거 등 보다 관리하기 쉽게끔 구성화되게됩니다.
이 시스템은 랩탑에서 로컬 노트북 셀을 실행하는 것과 동일하고 쉽고 빠른 반복적으로 전체 파이프라인의 맥락에서 단일 구성 요소를 실행, 반복 및 모니터링하는 기능을 제공합니다. 또한 필요한 입출력, 라이브러리 종속성 및 모니터링 매트릭 등을 정의할 수 도 있습니다.
궁극적으로 자동 업데이트가 가능한 CI ML pipeline가 생성되는 것입니다.
ML pipeline 구축 시 고려사항
1. 모든 단계를 재사용 가능한 구성 요소로 구축
ML pipeline을 생성하는 모든 단계를 고려해야합니다. 데이터를 수집하고 사전 처리하는 방법부터 시작해야하고 일반적으로 더 쉽게 이해하고 반복할 수 있도록 각 구성 요소의 범위를 제한하는 것이 좋습니다.
2. 테스트를 구성 요소로 코드화
테스트는 파이프라인의 고유한 부분으로 간주되어야 합니다. 수동 프로세스에서 입력 데이터와 모델 예측이 어떻게 표시되어야 하는지에 대해 온전한 검사를 수행하는 경우 이를 파이프라인에 코드화해야 합니다. 파이프라인은 테스트를 매번 수동으로 수행할 필요가 없기 때문에 훨씬 더 철저하게 테스트할 수 있는 기회를 제공합니다.
3. 실행은 파이프라인을 통해
ML pipeline의 오케스트레이션을 처리하는 방법에는 여러 가지가 있지만 원칙은 동일합니다. 구성 요소가 실행되는 순서와 입력 및 출력이 파이프라인을 통해 실행되는 방식을 정의합니다.
4.필요할 때 자동화
파이프라인 구축은 사람의 개입 없이 후속 단계 실행을 처리하기 때문에 이미 자동화를 도입하고 있지만, 궁극적인 목표는 특정 기준이 충족될 때 기계 학습 파이프라인을 자동으로 실행하는 것이기도 합니다. 예를 들어 프로덕션에서 모델 드리프트를 모니터링하여 재교육 실행을 트리거하거나 매일처럼 더 주기적으로 수행할 수 있습니다.
