
Presto는 facebook에서 엄청나게 큰 페타바이트급의 데이터를 효율적으로 분석하기 위해 2012년에 kickoff된 프로젝트입ㄴ디ㅏ.
대용량의 데이터를 빠르게 추출할 때 사용되는 툴입니다.
사용자가 데이터나 명령을 입력할 수 있는 데이터 분석을 위한 분산 sql 쿼리 엔진이빈다.
Presto 특징
- 다양한 소스 지원
hive 메타스토어, RDBMS, 아마존 s3 등 다양한 소스로부터 데이터를 읽어올 수 있습니다. - MR보다 빠르다
MR Job 베이스의 hive는 중간 단계별 결과를 disk에 저장하는데, prestro는 이를 memory에 저장하므로 빠릅니다. 다만 그만큼 리소스를 많이 필요로합니다.
presto의 query plan은 DAG(Directed Acyclic Graph) 기반입니다.
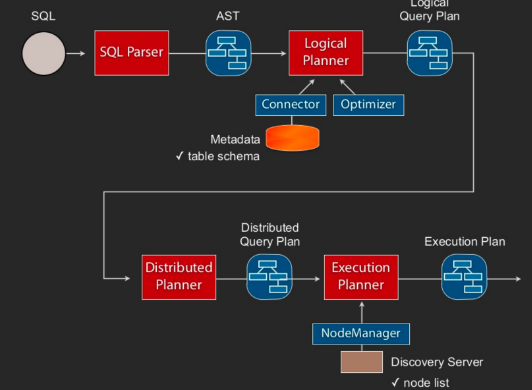
- BI/Visualization Tool
BI/Visualization Tool은 ODBC/JDBC driver 필요로 하기에 구현하는데 매우 오래 걸립니다.
따라서 PostgreSQL protocol의 ODBC/JDBC driver를 사용하여 이런 문제를 해결합ㄴ디ㅏ.

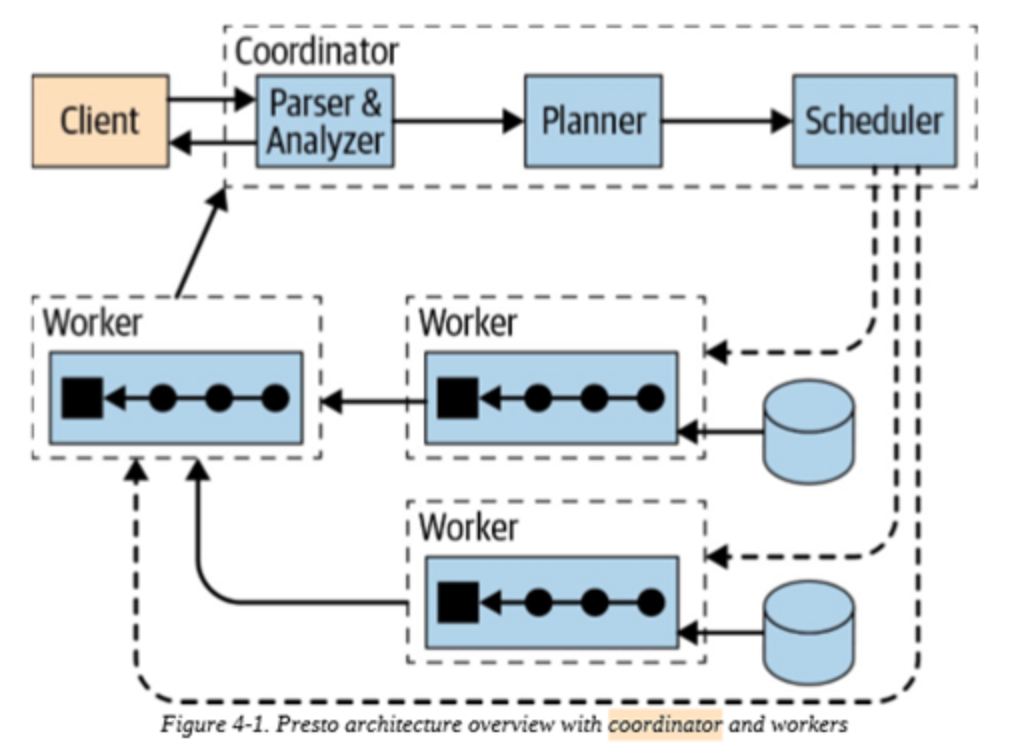
Presto는 하나의 coordinator와 실제로 job을 수행하는 여러 worker로 구성됩니다.
coordinator는 HBase, Hive 등 다양한 데이터 소스등을 읽어와 worker에게 전달을 하는 인터페이스 역할을 합니다.
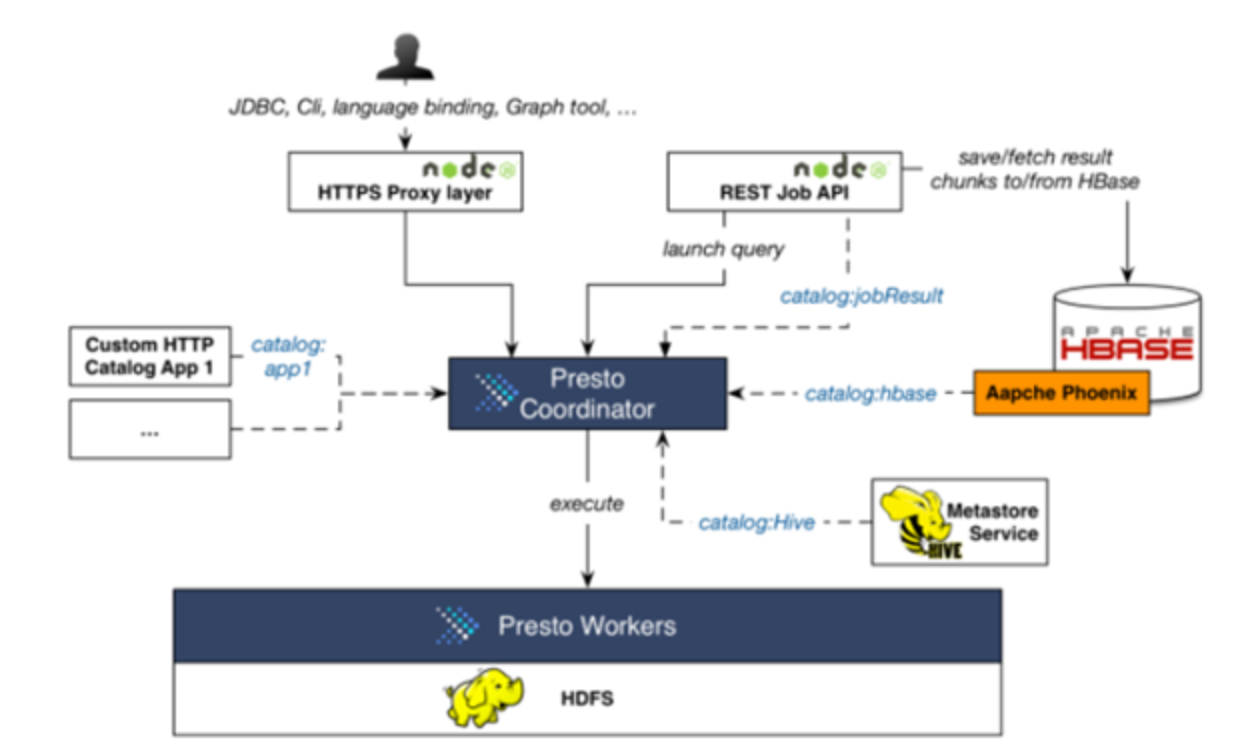
Connector plugin을 통해 다양한 storage 연결이 가능합니다.
connector란 저장소와 메타데이터 접근을 위해 사용되는 장치고 table schema를 coordinator에게 제공하고 table row를 worker에게 제공합니다.
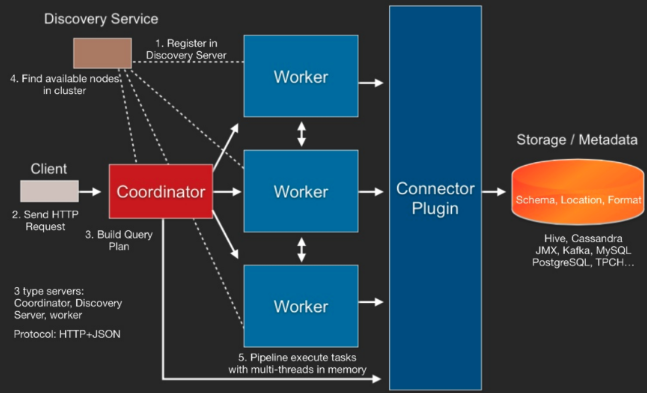
동작
coordinator가 client를 통해 들어오는 쿼리를 관리하며 worker가 data 처리를 하게끔 task를 보내줍니다.
worker는 coordinator로 부터 받은 task를 기반으로 data source에 접근합니다.
리턴 결과를 바로 client로 보내줍니다.

DevOps 🐥