
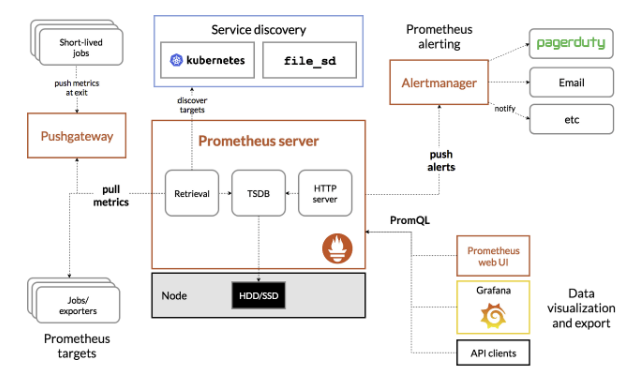
위 아키텍처에서
1. Exporter로는 Mysql-Exporter
2. Prometheus-server
3. Jobs -> metric을 수집해오기위한 job을 등록하고
4. Alertmanager 알림 발생 설정
5. Grafana -> ui 시각화 도구 사용
을 진행할 것이다.
먼저 2. Prometheus-server 구축을 해보자.
모든 구축은 쿠버네티스 환경에서 구성하는 방식으로 진행합니다.
쿠버네티스 환경에서 Prometheus를 구축 및 사용하기 위해서 rbac(role-based access control)을 배포해주어야합니다. 필요한 기본 설정을 진행하겠습니다.
# monitoring 네임스페이스에서 진행
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: monitoring
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: monitoring
namespace: monitoring
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: monitoring
subjects:
- kind: ServiceAccount
name: monitoring
namespace: monitoring
roleRef:
kind: ClusterRole
name: monitoring
apiGroup: rbac.authorization.k8s.io
---그리고 configmap을 배포합니다.
configmap에은 prometheus.yaml 파일로 필요한 설정을 정의하여 사용합니다.
- global
scrape_interval: 몇 초에 한번씩 metric을 수집할 것인지에 관한 옵션입니다. 해당 값을 설정하지 않는다면 default로 1m 값이 설정됩니다.
scrape_timeout: metric을 scrape하는데 time out을 얼마나 둘 것인지에 관한 옵션입니다. default는 10입니다.
evaluation_interval: 몇 초에 한번씩 규칙을 평가할 것인지 확인하는 옵션입니다. default 값은 1m입니다.- rule_files: 알림을 발생시키기 위한 조건을 나열
- alerting : 위의 rule files에 명시된 조건에 부합할 경우 알림을 전송할 alertmanager의 경로
- scrape_configs : prometheus가 metric을 어떻게 scrape 할 것인지와 관련된 옵션
apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: prometheus-server-conf namespace: monitoring data: prometheus.yaml: |- global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 15s rule_files: - "/etc/prometheus-rules/*.rules" alerting: alertmanagers: - scheme: http static_configs: - targets: - "alertmanager-http.monitoring.svc:9093"
scrape_configs:
- job_name: 'kubernetes-nodes'
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:10255'
target_label: __address__
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
target_label: instance
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: (.+)(?::\d+);(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-services'
metrics_path: /probe
params:
module: [http_2xx]
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_pod_container_port_number]
action: keep
regex: 9\d{3}
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kube-state-metrics'
static_configs:
- targets: ['kube-state-metrics-http.monitoring:8080']
위에서 rule_files에서 prometheus-rules 외부파일로 대체한 부분을 configmap으로 작성합니다.apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
labels:
name: prometheus-rules
namespace: monitoring
data:
alert-rules.yaml: |-
groups:
- name: Node
rules:
- alert: Kubernetes PV Error
expr: >
kube_persistentvolume_status_phase{phase=~Failed|Pending, job=kube-state-metrics} > 0
for: 5m
labels:
severity: critical
annotations:
summary: Kubernetes PersistentVolume error (pv: {{ $labels.persistentvolume }})
description: Persistent volume is in {{ $value }}
team: devops
- alert: Kubernetes PVC Pending
expr: >
kube_persistentvolumeclaim_status_phase{job=kube-state-metrics, phase=Pending} == 1
for: 5m
labels:
severity: warning
annotations:
summary: Kubernetes PersistentVolumeClaim pending (instance: {{ $labels.instance }})
description: PersistentVolumeClaim {{ $labels.namespace }}/{{ $labels.persistentvolumeclaim }} is pending
team: devops
- alert: Kubernetes Node Ready
expr: >
kube_node_status_condition{job=kube-state-metrics, condition=Ready,status=true} == 0
for: 5m
labels:
severity: critical
annotations:
summary: Kubernetes Node ready (node: {{ $labels.node }})
description: Node {{ $labels.node }} has been unready for a long time
team: devops
- alert: Node Out Of Memory
expr: >
((node_memory_MemTotal_bytes{job=kubernetes-service-endpoints} - node_memory_MemFree_bytes{job=kubernetes-service-endpoints}) / node_memory_MemTotal_bytes{job=kubernetes-service-endpoints}) * 100 > 90
for: 5m
labels:
severity: critical
annotations:
summary: Node memory usage > 90% (instance: {{ $labels.instance }})
description: {{ $value }}%
team: devops
- name: Pod
rules:
- alert: Container Cpu Usage
expr: >
sum(rate(container_cpu_usage_seconds_total{name!~.*prometheus.*, image!=, container!=POD, job=kubernetes-cadvisor}[5m])) by (container, namespace) / sum(container_spec_cpu_quota{name!~.*prometheus.*, image!=, container!=POD, job=kubernetes-cadvisor}/container_spec_cpu_period{name!~.*prometheus.*, image!=, container!=POD, job=kubernetes-cadvisor}) by (container, namespace) * 100 > 90
for: 5m
labels:
severity: critical
annotations:
summary: Container CPU usage > 90% (namespace: {{ $labels.namespace }}, container: {{ $labels.container }})
description: {{ $value }}%
- alert: Container Memory Usage
expr: >
(avg (container_memory_working_set_bytes{container!=POD, container!=, job=kubernetes-cadvisor}) by (container , namespace)) / (avg (container_spec_memory_limit_bytes{container!=POD, container!=, job=kubernetes-cadvisor} > 0 ) by (container, namespace)) * 100 > 90
for: 5m
labels:
severity: critical
annotations:
summary: Container Memory usage > 90% (namespace: {{ $labels.namespace }}, container: {{ $labels.container }})
description: {{ $value }}%
team: dev
- alert: Kubernetes Statefulset Down
expr: >
(kube_statefulset_status_replicas_ready{job=kube-state-metrics} / kube_statefulset_status_replicas{job=kube-state-metrics}) != 1
for: 5m
labels:
severity: critical
annotations:
summary: Kubernetes StatefulSet down (namespace: {{ $labels.namespace }}, statefulset: {{ $labels.statefulset }})
description: A StatefulSet went down
team: dev
- alert: Kubernetes Pod Not Healthy
expr: >
min_over_time(sum by (namespace, pod) (kube_pod_status_phase{job=kube-state-metrics, phase=~Pending|Unknown|Failed})[5m:]) > 0
for: 5m
labels:
severity: critical
annotations:
summary: Kubernetes Pod not healthy (namespace: {{ $labels.namespace }})(pod: {{ $labels.pod }})
description: Pod has been in a non-ready state for longer than a minute.
team: dev
- alert: Kubernetes Job Failed
expr: >
kube_job_status_failed{job=kube-state-metrics} > 0
for: 5m
labels:
severity: warning
annotations:
summary: Kubernetes Job failed (job: {{ $labels.job_name }})
description: Job {{ $labels.namespace }} / {{ $labels.job_name }} failed to complete
team: devapiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"apiVersion: v1
kind: Service
metadata:
name: prometheus-server-http
namespace: monitoring
labels:
app: prometheus
annotations:
prometheus.io/scrape: "true"
spec:
selector:
app: prometheus
type: NodePort
ports:
- port: 9090
protocol: TCP
name: prometheusapiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus-server
namespace: monitoring
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
serviceName: prometheus-server-http
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: monitoring
securityContext:
runAsUser: 0
containers:
- name: prometheus
image: prom/prometheus:v2.20.1
args:
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention.time=15d"
- "--config.file=/etc/prometheus/prometheus.yaml"
- "--web.enable-admin-api"
ports:
- name: prometheus
containerPort: 9090
resources:
requests:
cpu: 1
memory: 1Gi
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: prometheus-storage
mountPath: /prometheus
- name: prometheus-server-conf
mountPath: /etc/prometheus
- name: prometheus-rules
mountPath: /etc/prometheus-rules
volumes:
- name: prometheus-server-conf
configMap:
defaultMode: 420
name: prometheus-server-conf
- name: prometheus-rules
configMap:
name: prometheus-rules
volumeClaimTemplates:
- metadata:
name: prometheus-storage
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
storageClassName: manual
resources:
requests:
storage: 20Gi이렇게 배포한 prometheus에 port-forward로 접속해보겠습니다.
kubectl port-forward svc/prometheus-server-http 9090:9090 -n monitoringlocalhost:9090으로 접속 후 status>targets로 들어가보면
다음처럼 프로메테우스가 모니터링 하고 있는 타겟을 확인할 수 있는데, 이 중 kube-state-metrics가 (0/1 up)으로 올라가지 않은 것으로 표시된다.
kube-state-metrics는 쿠버네티스 클러스터 내의 API Server를 확인하며 클러스터 내 오브젝트(예를들면 Pod)에 대한 지표정보를 생성하는 서비스다.
따라서 Pod 상태정보를 모니터링하기 위해서는 kube-state-metrics가 떠 있어야 한다.
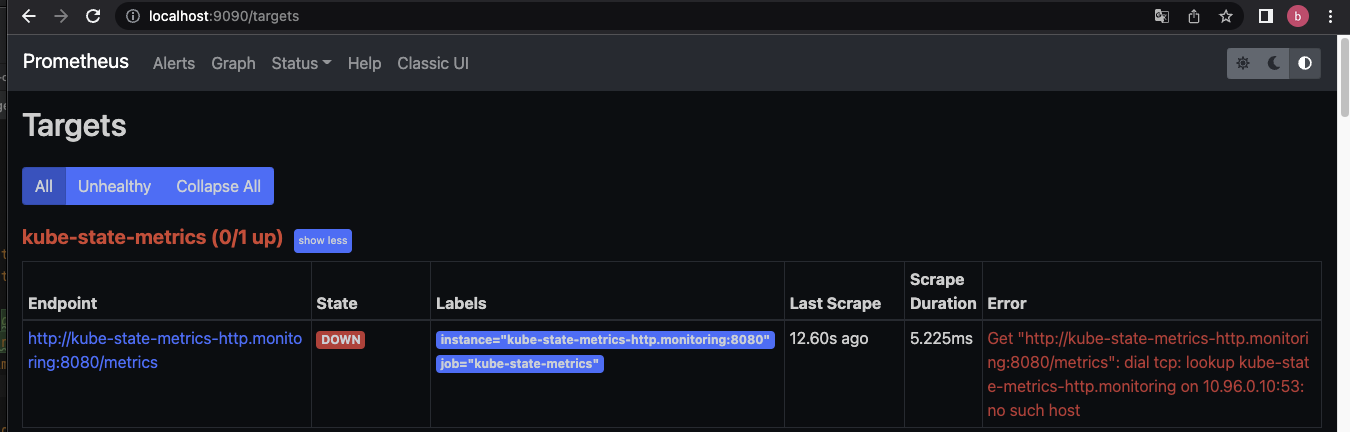
그러기 위해서 kube-state-metrics 파일도 생성하여 적용시켜보겠습니다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.8.0
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.8.0
name: kube-state-metrics
rules:
- apiGroups:
- ""
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs:
- list
- watch
- apiGroups:
- extensions
resources:
- daemonsets
- deployments
- replicasets
- ingresses
verbs:
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
- daemonsets
- deployments
- replicasets
verbs:
- list
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- list
- watch
- apiGroups:
- authentication.k8s.io
resources:
- tokenreviews
verbs:
- create
- apiGroups:
- authorization.k8s.io
resources:
- subjectaccessreviews
verbs:
- create
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- list
- watch
- apiGroups:
- certificates.k8s.io
resources:
- certificatesigningrequests
verbs:
- list
- watch
- apiGroups:
- storage.k8s.io
resources:
- storageclasses
- volumeattachments
verbs:
- list
- watch
- apiGroups:
- admissionregistration.k8s.io
resources:
- mutatingwebhookconfigurations
- validatingwebhookconfigurations
verbs:
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- networkpolicies
verbs:
- list
- watch
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.8.0
name: kube-state-metrics
namespace: kube-systemapiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.8.0
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.8.0
spec:
containers:
- image: quay.io/coreos/kube-state-metrics:v1.8.0
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: kube-state-metricsapiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.8.0
name: kube-state-metrics
namespace: kube-system
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics참조
https://twofootdog.tistory.com/17?category=845779
https://ooeunz.tistory.com/139
